
Tabella dei Contenuti
Quando si lavora con immagini e video, è spesso fondamentale individuare gli oggetti presenti nella scena, specificandone la posizione e la categoria di appartenenza.
L'obiettivo principale dei modelli di object detection (rilevamento di oggetti) è quello di identificare gli oggetti nella scena e associare a loro un set di informazioni, come una classe (automobile, sedia, divano, ...) e altri metadati utili. Questo tipo di compito permette di far interagire i nostri software col mondo reale direttamente via sensori come webcam.
Questo articolo ti guiderà all'utilizzo di un object detector con Ultralytics un framework di alto livello in Python per la object detection, al fine di ottenere informazioni preziose direttamente da immagini.
Clicca su questo link per saperne di più su Ultralytics.

- cosa è un object detector
- quali sono le sfide più comuni
- come utilizzare un modello pre-addestrato per identificare gli oggetti su un'immagine
Perché è utile rilevare oggetti in una scena
Le motivazioni possono essere svariate - eccone che risuonano con la maggior parte della community nella computer vision:
- Sicurezza e sorveglianza: rilevare persone in aree sensibili o monitorare movimenti sospetti.
- Automazione industriale: identificare pezzi o prodotti su una linea di produzione.
- Veicoli autonomi: riconoscere pedoni, ciclisti, altri veicoli o ostacoli sulla strada.
- Analisi sportiva: tracciare giocatori, palloni e altri elementi in tempo reale per statistiche e strategie.
In generale, capire cosa c’è nella scena e dove si trova permette di prendere decisioni automatiche o guidate dai dati, trasformando semplici immagini in informazioni utili.
Requisiti per l’Object Detection
Rilevare oggetti in modo efficace all’interno di un’immagine o di un video è un compito complesso poiché influenzato da numerosi fattori. Le principali difficoltà si possono suddividere in tre categorie:
- condizioni di acquisizione dell'immagine
- caratteristiche degli oggetti
- complessità del contesto
Vediamo queste condizioni una per una.
Condizioni di acquisizione dell'immagine.
L’inquadratura e la prospettiva possono cambiare drasticamente l’aspetto di un oggetto: un’auto vista dal davanti, non assomiglia per nulla alla stessa auto vista lateralmente o dal di dietro.

A questo si aggiungono i problemi legati all’illuminazione: ombre forti, controluce o riflessi rendono più difficile distinguere gli oggetti dallo sfondo.
Un ultimo problema di acquisizione è legato al fattore scala: un oggetto troppo piccolo rischia di passare inosservato, mentre uno troppo grande può perdere dettagli importanti.
Caratteristiche degli oggetti
Un'altra categoria che va tenuta in considerazione quando si affronta il problema dell'object detection include le caratteristiche del tipo di oggetto che si vuole rilevare. Spesso capita che oggetti appartenenti alla stessa categoria presentano forme molto diverse: un esempio classico è la categoria sedia.

Una sedia può essere diversa da un'altra per forma, colore, dimensione, numero di piedi e così via.
Complessità del contesto
Uno sfondo con caratteristiche o elementi simili all’oggetto di interesse, può confondere il modello e generare rilevamenti che nella realtà non esistono.

In questo esempio è evidente come l'aspetto dell'animale si confonda con l'aspetto dell'essere umano, rendendo il suo riconoscimento notevolmente complicato.
Applicazione pratica dellaobject detection
Conosciute le potenzialità e le difficoltà di questa tecnologia, passiamo ora ad un esempio di applicazione pratica. In questo articolo useremo Utralytics, una libreria che ha reso il rilevamento di oggetti con YOLO incredibilmente semplice e veloce da implementare, anche per chi è alle prime armi.
Installazione delle librerie necessarie
Il primo passaggio è capire come configurare l’ambiente di lavoro, ovvero capire quali sono le librerie necessarie da installare. La configurazione esatta dipende dall'hardware che hai a disposizione, ovvero se lavori solo con la CPU o se hai a disposizione una GPU.
Se non hai una scheda grafica dedicata o vuoi semplicemente un'installazione veloce e leggera, puoi scegliere la versione ottimizzata per CPU: in questo caso, Ultralytics viene installato senza i componenti più pesanti, e il sistema di calcolo PyTorch viene scaricato nella sua versione specifica per la CPU.
Se non hai familiarità con PyTorch e con il suo ruolo nel deep learning, puoi approfondire l'argomento leggendo questo articolo dedicato.

Configurazione per CPU
Questa configurazione riduce i tempi di installazione e l’uso di memoria, mantenendo tutte le funzionalità necessarie per la rilevazione degli oggetti.
Usando il gestore di ambienti virtuali e pacchetti chiamato uv, possiamo usare i seguenti comandi per installare le librerie.
uv add ultralytics --no-depsUltralytics per CPU
uv add torch torchvision --index-url https://download.pytorch.org/whl/cpuPyTorch ottimizzato per CPU
uv add opencv-python-headlessVersione leggera di OpenCV senza GUI
Segui questo link se vuoi saperne di più su come attivare un ambiente virtuale in Python.
Configurazione per GPU
Se disponi di GPU, invece, è consigliabile installare la versione completa dei pacchetti, abilitando l’accelerazione tramite CUDA. In questo modo i modelli possono essere eseguiti molto più velocemente, soprattutto su video o immagini ad alta risoluzione.
uv add ultralytics opencv-pythonIn entrambi i casi, una volta completata l’installazione, l’ambiente risulta pronto per eseguire modelli pre-addestrati e iniziare a sperimentare con la rilevazione di oggetti in immagini e video.
Modern Computer Vision with PyTorch
V Kishore Ayyadevara
Scoprirai le migliori pratiche per lavorare con le immagini, modificare gli iperparametri e portare i modelli in produzione. Man mano che avanzerai, implementerai diversi casi d'uso per il riconoscimento facciale di punti chiave, il rilevamento multi-oggetto, la segmentazione e il rilevamento della posa umana. Questo libro fornisce solide basi nella generazione di immagini mentre esplori diverse architetture GAN.

Esempio pratico con YOLOv8
In questo esempio useremo il modello YOLOv8, con l'obiettivo di mostrare come effettuare la sua configurare, come scaricare immagini di esempio, eseguire l’inferenza e salvare i risultati in modo strutturato.
Caricamento del modello
Il primo passo pratico per utilizzare YOLOv8 consiste nel caricare un modello pre-addestrato. Questo viene gestito dalla funzione setup_yolo_model(), che si occupa di preparare il modello pronto per l’inferenza.
All’interno della funzione, viene importata la classe YOLO dalla libreria Ultralytics. Al primo utilizzo, il modello selezionato viene scaricato automaticamente, evitando all’utente di dover gestire manualmente i pesi pre-addestrati.
La libreria mettere a disposizione diverse varianti di YOLOv8, ognuna con un compromesso diverso tra velocità e accuratezza:
yolov8n.pt(nano) – molto veloce, meno accuratoyolov8s.pt(small)yolov8m.pt(medium)yolov8l.pt(large)yolov8x.pt(extra large) – più accurato, ma più lento
Nel nostro esempio viene usata la versione nano, ideale per test rapidi e sistemi con risorse limitate.
Se vuoi sapere di più circa i modelli disponibili, consulta la documentazione ufficiale.
from ultralytics import YOLO
def setup_yolo_model():
"""
Carica il modello YOLOv8. Al primo utilizzo verrà scaricato automaticamente
"""
print("Caricamento modello YOLOv8...")
model = YOLO('yolov8n.pt') # Usiamo la versione nano per velocità
print("Modello caricato con successo!")
return modelScaricare immagini di esempio
Prima di poter testare il modello YOLOv8, è necessario disporre alcune immagini su cui eseguire la rilevazione. La funzione download_sample_images() si occupa proprio di questo: scarica automaticamente immagini di esempio fornite da Ultralytics, così da avere un set di test pronto all’uso senza dover cercare immagini esterne.
All’interno della funzione, viene creata una cartella sample_images e vengono scaricate due immagini da URL predefiniti, contenenti soggetti come persone o scene urbane. La funzione controlla se i file sono già presenti, evitando download duplicati.
import os
def download_sample_images():
"""
Ultralytics fornisce immagini di esempio che possiamo usare
"""
import urllib.request
# URL di immagini di esempio da Ultralytics che contengono persone
sample_urls = [
"https://ultralytics.com/images/bus.jpg",
"https://ultralytics.com/images/zidane.jpg"
]
# Crea la cartella per le immagini se non esiste
os.makedirs("sample_images", exist_ok=True)
# Scarica le immagini se non sono già presenti
for i, url in enumerate(sample_urls):
filename = f"sample_images/sample_{i+1}.jpg"
if not os.path.exists(filename):
print(f"Scaricando {url}...")
urllib.request.urlretrieve(url, filename)
print(f"Salvata in {filename}")
return ["sample_images/sample_1.jpg", "sample_images/sample_2.jpg"]Di seguito vengono mostrate le immagini scaricate per il test.


Inferenza
Una volta caricato il modello e preparate le immagini di esempio, il passo successivo consiste nell’eseguire l’inferenza. Questo compito è gestito dalla funzione run_inference().
La funzione prende in input il modello YOLOv8, il percorso dell’immagine da analizzare, un eventuale filtro sulle classi (classes) e la cartella di destinazione dei risultati (output_dir).
Se non viene specificato alcun filtro di classe, l’inferenza verrà eseguita su tutte le categorie rilevabili dal modello. In alternativa, è possibile passare un elenco di classi specifiche per limitare la rilevazione. Nel nostro esempio useremo la classe 0, ovvero la classe associata alla categoria persone.
L'identificativo di ciascuna classe per il modello YOLOv8 pre-addestrato può essere ricavato dalla sezione Set di dati della pagina di Ultralytics.
All’interno della funzione:
- Inferenza – viene eseguita direttamente tramite il modello, eventualmente filtrando per le classi indicate.
- Visualizzazione – ogni risultato viene mostrato con i bounding box sull’immagine, così da avere un feedback immediato.
- Salvataggio – le immagini risultanti vengono salvate in cartelle separate a seconda che l’inferenza sia generica o filtrata.
- Dettagli delle rilevazioni – per ogni oggetto rilevato, viene stampata a video la classe, l’indice e il punteggio di confidenza, permettendo di verificare rapidamente i risultati del modello.
In questo modo, run_inference() combina visualizzazione immediata, salvataggio dei risultati e informazioni dettagliate sugli oggetti rilevati, rendendo semplice sia la sperimentazione che la verifica dell’accuratezza del modello su immagini di esempio.
def run_inference(model, image_path, classes=None, output_dir="results"):
"""
Esegue l'inferenza su tutte le classi rilevabili o su quelle specificate.
"""
if classes is None:
print(f"\n--- INFERENZA GENERICA su {image_path} ---")
else:
print(f"\n--- INFERENZA FILTRATA (classi: {classes}) su {image_path} ---")
# Esegui l'inferenza direttamente con filtro classi
results = model(image_path, classes=classes)
for result in results:
# Visualizza immagine con i bounding box filtrati
result.show()
# Salva l'immagine con i risultati
base_name = os.path.splitext(os.path.basename(image_path))[0]
if classes is None:
output_dir = os.path.join(output_dir, "generic")
else:
output_dir = os.path.join(output_dir, "filtered")
os.makedirs(output_dir, exist_ok=True)
jpg_file = os.path.join(output_dir, f"{base_name}_output.jpg")
result.save(filename=jpg_file) # Salva l'immagine con i risultati
print(f"Immagine di output salvata in {jpg_file}")
# Stampa i dettagli delle rilevazioni
if result.boxes is not None and len(result.boxes) > 0:
print(f"Trovati {len(result.boxes)} oggetti:")
for box in result.boxes:
class_id = int(box.cls[0])
class_name = model.names[class_id]
confidence = float(box.conf[0])
print(f" - {class_name}: {confidence:.2f}")
else:
print("Nessun oggetto rilevato")
return results
Salvataggio dei risultati
Dopo aver eseguito l’inferenza, è spesso utile conservare i risultati in un formato strutturato per ulteriori analisi o elaborazioni successive. La funzione save_results() si occupa proprio di questo: salva i dati relativi agli oggetti rilevati in un file CSV.
La funzione prende in input il percorso dell’immagine, l’oggetto results prodotto dall’inferenza e la cartella di destinazione (output_dir). Per ogni immagine analizzata, viene creato un file CSV che contiene una riga per ogni oggetto rilevato, riportando:
class_id– l’identificativo della classe rilevatax1, y1, x2, y2– le coordinate della bounding box
All’interno della funzione, viene creata automaticamente la cartella di output se non esiste. Le informazioni sulle bounding box vengono estratte dall’oggetto results prodotto da YOLOv8, convertite in array NumPy e scritte nel file CSV con un formato chiaro e leggibile.
In questo modo, save_results() consente di avere un registro dettagliato di tutte le rilevazioni, utile sia per elaborazioni successive (statistiche, tracking, visualizzazioni) sia per confronti tra diverse immagini o modelli.
def save_results(image_path, results, output_dir="results"):
"""
Salva una riga per ogni oggetto rilevato con: class_id, x1, y1, x2, y2
"""
os.makedirs(output_dir, exist_ok=True)
# Crea nome file CSV
base_name = os.path.splitext(os.path.basename(image_path))[0]
csv_file = os.path.join(output_dir, f"{base_name}_detections.csv")
with open(csv_file, 'w') as f:
# Header del CSV
f.write("class_id,x1,y1,x2,y2\n")
# Estrai le box dall'oggetto results
boxes = results[0].boxes.data.cpu().numpy() if results[0].boxes is not None else []
# Itera sulle box (array NumPy: x1,y1,x2,y2,conf,class)
for box in boxes:
x1, y1, x2, y2, conf, class_id = box
f.write(f"{int(class_id)},{x1:.1f},{y1:.1f},{x2:.1f},{y2:.1f}\n")
print(f"Risultati salvati in {csv_file}")
Funzione main
Una volta definite tutte le funzioni necessarie, non resta altro che eseguire la funzione principale main(), che coordina l’intero flusso.
def main():
"""
FUNZIONE PRINCIPALE
Esegue tutto il processo dall'inizio alla fine
"""
print("=== YOLOV8 PERSON DETECTION ===\n")
# 1. Setup del modello
model = setup_yolo_model()
# 2. Scarica immagini di esempio
sample_images = download_sample_images()
# 3. Processa ogni immagine
for image_path in sample_images:
print(f"\n{'='*50}")
print(f"PROCESSANDO: {image_path}")
print('='*50)
# 4. Inferenza generica (tutte le classi)
results = run_inference(model, image_path)
# 5. Inferenza solo sulle persone
results_person = run_inference(model, image_path, classes=[0])
save_results(image_path, results_person)
if __name__ == "__main__":
main()
Una volta eseguito il programma principale, l’output fornisce un feedback completo su ogni fase del processo.
=== YOLOV8 PERSON DETECTION ===
Caricamento modello YOLOv8...
Modello caricato con successo!
==================================================
PROCESSANDO: sample_images/sample_1.jpg
==================================================
--- INFERENZA GENERICA su sample_images/sample_1.jpg ---
image 1/1 sample_images/sample_1.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 272.0ms
Speed: 16.6ms preprocess, 272.0ms inference, 17.8ms postprocess per image at shape (1, 3, 640, 480)
Immagine di output salvata in results/generic/sample_1_output.jpg
Trovati 6 oggetti:
- bus: 0.87
- person: 0.87
- person: 0.85
- person: 0.83
- person: 0.26
- stop sign: 0.26
--- INFERENZA FILTRATA (classi: [0]) su sample_images/sample_1.jpg ---
image 1/1 sample_images/sample_1.jpg: 640x480 4 persons, 252.6ms
Speed: 3.6ms preprocess, 252.6ms inference, 5.1ms postprocess per image at shape (1, 3, 640, 480)
Immagine di output salvata in results/filtered/sample_1_output.jpg
Trovati 4 oggetti:
- person: 0.87
- person: 0.85
- person: 0.83
- person: 0.26
Risultati salvati in results/sample_1_detections.csv
==================================================
PROCESSANDO: sample_images/sample_2.jpg
==================================================
--- INFERENZA GENERICA su sample_images/sample_2.jpg ---
image 1/1 sample_images/sample_2.jpg: 384x640 2 persons, 1 tie, 607.1ms
Speed: 17.5ms preprocess, 607.1ms inference, 6.3ms postprocess per image at shape (1, 3, 384, 640)
Immagine di output salvata in results/generic/sample_2_output.jpg
Trovati 3 oggetti:
- person: 0.84
- person: 0.82
- tie: 0.29
--- INFERENZA FILTRATA (classi: [0]) su sample_images/sample_2.jpg ---
image 1/1 sample_images/sample_2.jpg: 384x640 2 persons, 361.4ms
Speed: 33.9ms preprocess, 361.4ms inference, 1.9ms postprocess per image at shape (1, 3, 384, 640)
Immagine di output salvata in results/filtered/sample_2_output.jpg
Trovati 2 oggetti:
- person: 0.84
- person: 0.82
Risultati salvati in results/sample_2_detections.csvVengono quindi salvate le immagini con le predizioni e i file con i risultati in formato strutturato. Di seguito viene mostrato l'output del modello sull'immagine sample_2.jpg.
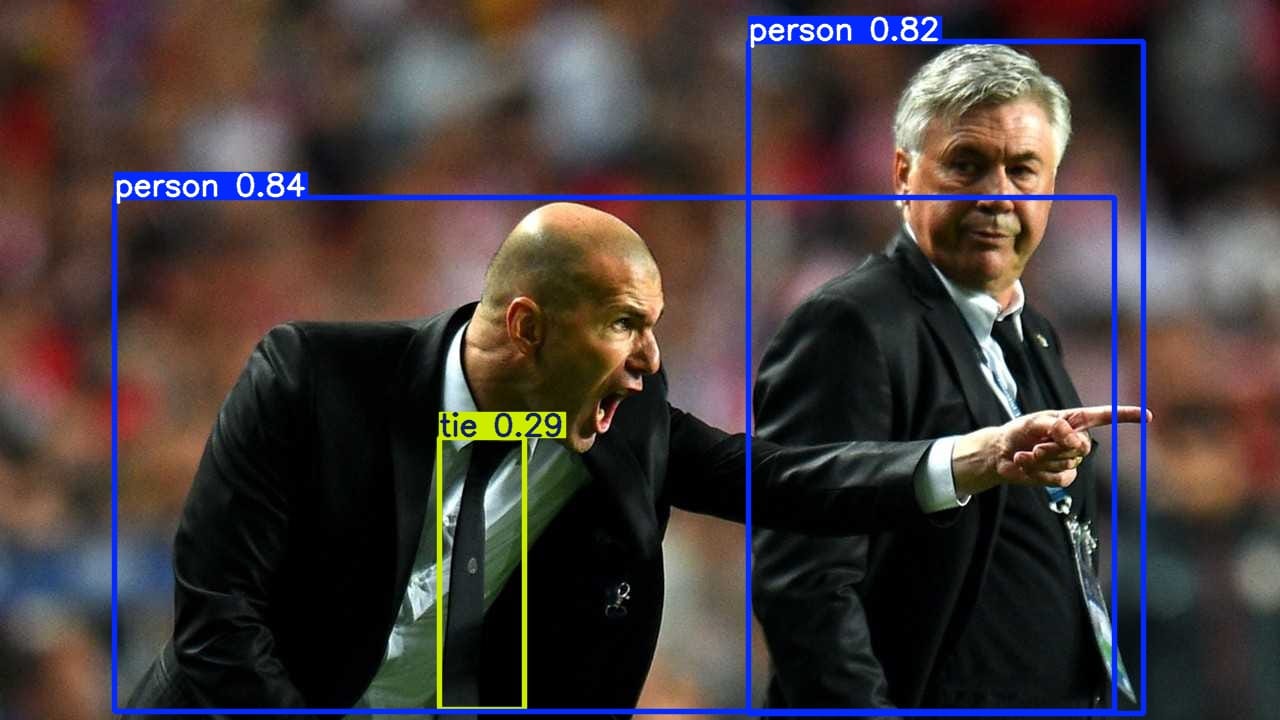
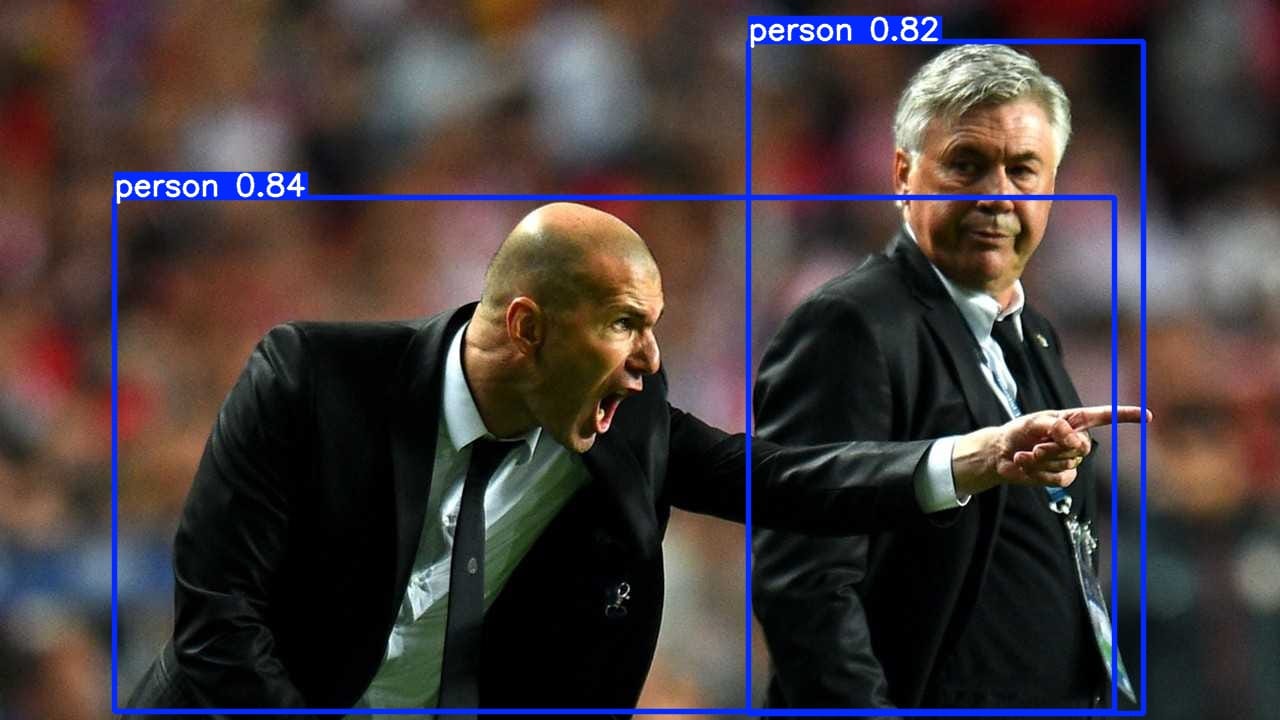
Il file CSV risulta, invece, essere il seguente.
class_id,x1,y1,x2,y2
0,114.9,197.4,1114.5,711.9
0,748.5,41.9,1143.1,713.0Conclusioni e possibili estensioni
L’object detection con Ultralytics permette di individuare oggetti in immagini e video in modo rapido, con relativamente pochi passaggi.
Abbiamo visto come rilevare oggetti in una singola immagine, ma cosa succede con i video? E perché non seguire i movimenti degli oggetti nel tempo per analizzare il loro percorso?
A queste e altre domande si può rispondere integrando il modulo di object detection con sviluppi successivi, che possono riguardare:
- Detection su video: Eseguire il rilevamento frame-by-frame o in tempo reale su flussi video, essenziale per la sorveglianza o l'analisi sportiva.
- Tracking di oggetti in sequenza: Seguire il movimento degli oggetti tra fotogrammi consecutivi per analizzare traiettorie o comportamenti.
- Re-identification: Identificare e tracciare lo stesso oggetto nel tempo, anche quando esce e rientra dal campo visivo.
- Scelta del modello: Valutare se usare modelli pre-addestrati (adatti a test rapidi o scenari generici) oppure addestrare modelli custom su dati specifici per ottenere maggiore accuratezza in contesti particolari.
Queste estensioni dimostrano come le funzionalità base di Ultralytics + YOLO possano diventare la base per sistemi più complessi di analisi visiva.
Commenti dalla community