
In questo articolo vedremo come usare un corpus di dati e estrarre token e sequenze con padding da usare per addestrare modelli di deep learning attraverso Tensorflow.
Ho già toccato l'argomento in un post precedente dove parlavo di come convertire testi per in tensori per il deep learning, ma in questo caso il focus sarà su come formattare correttamente le sequenze di token per Tensorflow.
Questa metodologia è indispensabile per fornire ai nostri modelli sequenze di token di lunghezza uniforme (padding). Vediamo come.
Il Dataset
Useremo il dataset fornito da Sklearn, 20newsgroups, per avere rapido accesso ad un corpus di dati testuali. A scopo dimostrativo, userò solo un campione di 10 testi.
import numpy as np
from sklearn.datasets import fetch_20newsgroups
# categorie dalle quali prenderemo i nostri dati
categories = [
'comp.graphics',
'comp.os.ms-windows.misc',
'rec.sport.baseball',
'rec.sport.hockey',
'alt.atheism',
'soc.religion.christian',
]
# primi 10 elementi
dataset = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, remove=('headers', 'footers', 'quotes'))
corpus = [item for item in dataset['data'][:10]]
corpus
Su questi testi non applicheremo preprocessing, in quanto la tokenizzazione di Tensorflow rimuove automaticamente la punteggiatura per noi.
Cosa è la tokenizzazione?
In gergo, tokenizzare vuol dire ridurre una frase nei simboli (in inglese, token, per l'appunto) che la formano.
Quindi se abbiamo una frase del tipo "Ciao, mi chiamo Andrea." la sua versione tokenizzata sarà semplicemente ["Ciao", ",", "mi", "chiamo", "Andrea", "."]. Da notare come la tokenizzazione includa di default la punteggiatura.
Applicare la tokenizzazione è il primo passo per convertire le nostre parole in valori numerici processabili da un modello di machine learning.
Tipicamente è sufficiente applicare .split() su una stringa in Python per effettuare una tokenizzazione semplice. Ci sono però diverse metodologie di tokenizzazione che possono essere applicate. Tensorflow offre una API molto interessante per che permette di customizzare proprio tale logica. La vedremo tra poco.
Cosa è il padding?
Una volta tokenizzata una frase, Tensorflow restituisce valori numerici associati ad ogni token. Questa è chiamata tipicamente word_index, ed è un dizionario formato da parola e indice {word: index}. Ogni parola incontrata viene numerata e tale numero viene usato per identificare quella parola.
Un modello di deep learning vorrà spesso un input di dimensione uniforme. Questo significa che frasi di lunghezza diverse saranno problematiche per il nostro modello. Qui è dove entra il padding in gioco.
Prendiamo due frasi e le loro sequenze di indici (escludendo la punteggiatura):
- Ciao, mi chiamo Andrea: [43, 3, 56, 6]
- Ciao, sono un analista e uso Tensorflow per i miei progetti di deep learning: [43, 11, 9, 34, 2, 22, 15, 4, 5, 8, 19, 10, 26, 27]
Notiamo come la prima sia più corta (4 elementi) della seconda (14 elementi). Se dessimo in pasto al nostro modello le sequenze in questo modo, questo restituirebbe degli errori. Vanno quindi normalizzate le sequenze in modo che abbiano la stessa lunghezza.
Applicare padding (in italiano possiamo tradurlo con riempimento, imbottitura) su una sequenza di significa usare un valore numerico predefinito (solitamente 0) per portare le sequenze più corte alla stessa lunghezza della sequenza dalla lunghezza massima. Quindi avremo questo:
- Ciao, mi chiamo Andrea: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 43, 3, 56, 6]
- Ciao, sono un analista e uso Tensorflow per i miei progetti di deep learning: [43, 11, 9, 34, 2, 22, 15, 4, 5, 8, 19, 10, 26, 27]
Ora entrambe le sequenze hanno la stessa lunghezza. Possiamo decidere come fare padding, se inserire gli zeri prima o dopo la sequenza, direttamente con pad_sequences di Tensorflow.
Applicazione della tokenizzazione e padding
Applichiamo ora con il codice qui sotto la tokenizzazione e il padding al nostro corpus di dati dopo aver estratto le frasi da esso.
# creiamo una lista vuota che conterrà le nostre frasi
sentences = []
# iteriamo nel nostro corpus
for text in corpus:
# splittiamo le frasi sul punto
splitted_text = text.split(".")
# inseriamo nella lista ogni frase estratta,
for sentence in splitted_text:
sentences.append(sentence)
# importiamo Tokenizer e pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# inizializziamo il tokenizer con un out_of_vocabulary token
tokenizer = Tokenizer(oov_token="<OOV>")
# generiamo il dizionario parola - indice andando a fare fit sul tokenizer
tokenizer.fit_on_texts(sentences)
# generiamo e facciamo padding sulle sequenze
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')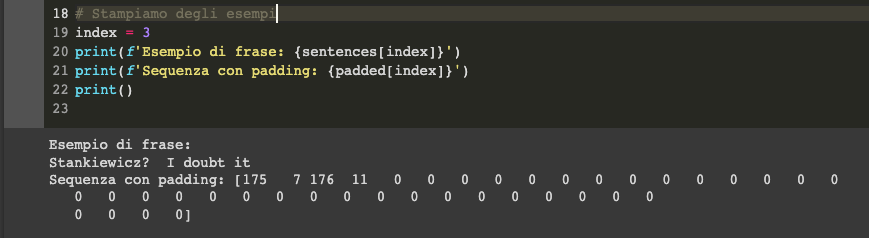
Da notare come nel codice sia presente post come modalità di padding. Questo significa che gli zeri vengono inseriti post-sequenza, quindi allungando il vettore dopo il valore tokenizzato e non prima.
Ed ecco come vengono applicati tokenizzazione e padding sui testi per fornirli ad una rete neurale su Tensorflow. Se avete domande o dubbi lasciate un commento nel box in fondo alla pagina. Alla prossima!





Commenti dalla community