
In questo post vedremo come costruire un modello di classificazione binaria con TensorFlow per differenziare tra cani e gatti in immagini. Prendendo spunto da una famosa competizione su Kaggle e il relativo dataset, useremo questo compito per imparare come
- importare dal web un dataset compresso
- costruire un modello di classificazione con strati di convoluzione e max pooling
- creare un generatore di immagini con ImageDataGenerator per gestire efficacemente le immagini di addestramento e di validazione
- compilare e addestrare il modello
- visualizzare le trasformazioni applicate alle immagini nei vari strati della rete neurale
- fare delle previsioni su immagini mai viste prima
Poiché fare deep learning non è alla portata di qualsiasi PC di uso domestico, useremo Google Colab con runtime impostato su GPU.
Importare il dataset compresso dal web
Useremo un dataset ridotto di 3000 immagini di cani e gatti presi dal famoso dataset di Kaggle formato da 25000 immagini. Il dataset completo pesa più di 500 MB e caricarli/scaricarli su Colab può essere frustrante. Useremo questa versione ridotta che in ogni caso ci permetterà di testare efficacemente il nostro modello.
La URL al dataset è questa:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Usiamo il comando wget per scaricare il file compresso nel nostro file system:
import zipfile
import os
## --- DOWNLOAD DATASET
# scarichiamo il file
!wget --no-check-certificate https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
# scompattiamo la cartella con zipfile
local_zip = './cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall()
zip_ref.close()
## --- DOWNLOAD DATASET
## -- DEFINIZIONE VARIABILI
# dichiariamo la posizione dei nostri file di addestramento e validazione
base_dir = 'cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# puntiamo alle cartelle di gatti e cani per il training
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# puntiamo alle cartelle di gatti e cani per la validazione
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')Usando il comando wget e i pacchetti os e zipfile siamo in grado di scaricare e organizzare i nostri file di addestramento in maniera efficiente. Abbiamo ora un modo per puntare ai nostri file con delle variabili specifiche, che useremo in ImageDataGenerator di TensorFlow.
Diamo una occhiata ad un set di immagini così da farci una idea su quello che andremo a classificare

Vediamo come le immagini siano molto diverse tra loro e come a volte siano presenti anche entità estranee come esseri umani o altri oggetti. Costruiremo un modello di deep learning in grado di differenziare efficacemente tra cani e gatti nonostante questi elementi non inerenti.
Se usiamo len(os.listdir(train_cats_dir))per contare il numero di immagini nelle varie cartelle vediamo che il loro numero ammonta a 3000, con 1000 immagini di cani e di gatti nel training e 500 immagini rispettivamente per la validazione.
Breve introduzione a convoluzioni e pooling
Nel modello che vedremo a breve useremo strati di convoluzioni e di max pooling. Entrambi gli strati sono ampiamente usati in compiti di computer vision per via delle trasformazioni che applicano sulla immagine in input e beneficiano la rete neurale perché la aiutano nell'identificazione dei pattern andando a enfatizzare delle caratteristiche essenziali presenti in esse.
Convoluzione
Una convoluzione è essenzialmente un filtro che viene applicato ad una immagine. Ragionando a livello di pixel, che sono le entità che andremo a trasformare quando si parla di immagini, una convoluzione guarda il suo valore e quelli dei suoi pixel vicini e trasforma il pixel target usando una griglia di valori mappati ad ogni pixel considerato.
Se per esempio usiamo una griglia 3x3, allora considereremo tutti i pixel vicini del nostro pixel target. Quando applichiamo la convoluzione, il pixel target viene trasformato e assume il valore corrispondente alla moltiplicazione del valore originale di ogni pixel considerato e del rispettivo valore nella griglia di convoluzione. Il valore finale corrisponde alla somma di ogni prodotto. Vediamo con una immagine.
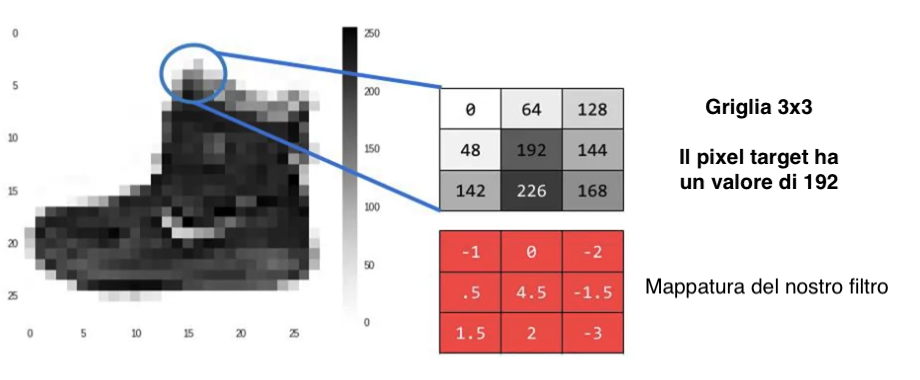
Considerando il pixel target con valore 192, allora una convoluzione applicato su di esso considererà tutti i pixel intorno ad esso come vicini e il suo nuovo valore sarà il seguente:
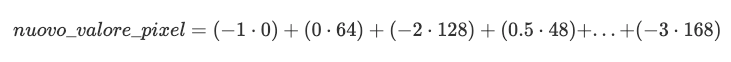
L'idea alla base di una convoluzione è quella di far emergere alcune caratteristiche di una immagine, come ad esempio rendere bordi e contorni più salienti rispetto al background.
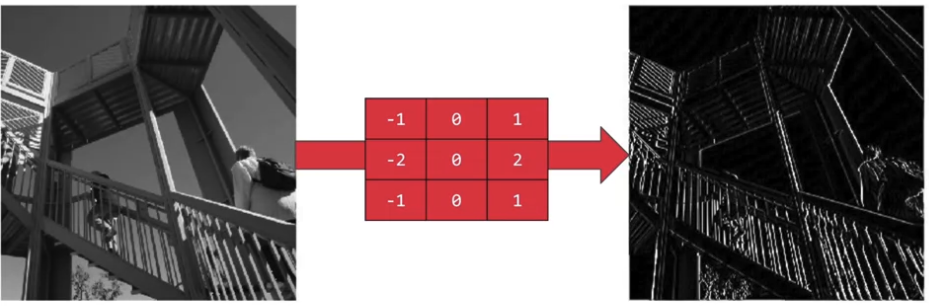
Le convoluzioni vengono spesso accompagnate dal pooling (in italiano, aggregazione, compressione), che permette alla rete neurale di comprimere l'immagine e estrarre gli elementi davvero salienti della stessa.
In TensorFlow, un tipico strato di convoluzione viene applicato con tf.keras.layers.Conv2D(filters, kernel_size, activation, **kwargs). In filters inseriremo il numero di filtri di convoluzione da applicare, invece con kernel_size indicheremo la grandezza della griglia. Con activation specificheremo invece la funzione di attivazione. I parametri sono molti e consiglio al lettore di studiare meglio il materiale sulla documentazione ufficiale di TensorFlow.
Pooling
Fare pooling vuol dire applicare una compressione all'immagine. Se per esempio volessimo applicare uno strato di pooling 2D con TensorFlow, questo significherebbe prendere il pixel di riferimento, quello sotto di esso e i due al suo lato sinistro, in modo da formare una griglia di quattro valori. Di questi valori si conserva solo il valore più grande.
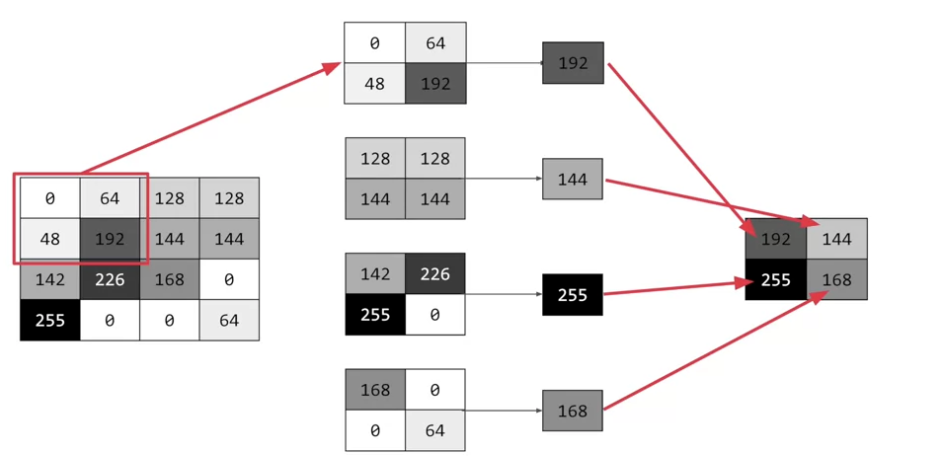
Guardando attentamente questa immagine vediamo come fare pooling riduce una immagine di 16 pixel in una da 4, andando proprio a prendere i pixel dal valore più grande in blocchi di 4 e ripetendo il processo.
Questo meccanismo viene applicato dopo la convoluzione, andando così a preservare le caratteristiche messe in risalto dalla stessa e amplificando ancora di più questo effetto. Il pooling riduce anche la dimensione dell'immagine, velocizzando quindi l'addestramento negli strati più avanzati di una rete neurale.
Il pooling è solitamente applicato applicato prendendo il valore massimo, ma ci sono anche altre logiche, come ad esempio quelle basate sulla media e somma.
In TensorFlow, un tipico strato di pooling viene applicato con tf.keras.layers.MaxPooling2D(pool_size, **kwargs). In pool_size inseriremo la grandezza della griglia. I parametri sono molti e consiglio al lettore di studiare meglio il materiale sulla documentazione ufficiale di Keras.
Creazione del modello con TensorFlow
Ora che è un po' più chiaro cosa siano convoluzione e aggregazione, procediamo con la creazione di un modello di classificazione binaria con TensorFlow in grado di sfruttare le caratteristiche che rendono cani e gatti identificabili. Useremo l'API sequenziale di TensorFlow perché è facile da comprendere e da implementare.
Una nota sulla input_shape
È importante notare che dovremmo fornire al modello immagini dalle dimensioni uniformi. Questa dimensione è arbitraria e per questo modello useremo una dimensione di 150x150 pixel. Ogni immagine verrà quindi ridimensionata da TensorFlow in modo da essere quadrata.
Poiché stiamo usando immagini a colori, dovremmo anche fornire questa informazione. La input_shape sarà quindi (150, 150, 3), dove 3 sta proprio per i tre bit di informazione che codificano il colore. Vedremo tra poco come assicurarci che le nostre immagini siano di questa dimensione quando sfrutteremo ImageDataGenerator.
Vediamo come implementare l'architettura della rete neurale.
import tensorflow as tf
model = tf.keras.models.Sequential([
# poiché Conv2D è il primo strato della rete neurale, dovremmo specificare anche la dimensione dell'input
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
# applichiamo uno strato di aggregazione 2D
tf.keras.layers.MaxPooling2D(2,2),
# e ripetiamo il processo
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# appiattiamo il risultato per fornirlo allo strato denso per la classificazione
tf.keras.layers.Flatten(),
# e definiamo 512 neuroni per l'elaborazione dell'output processato dagli strati precedenti
tf.keras.layers.Dense(512, activation='relu'),
# un singolo neurone di output. Il risultato sarà 0 se l'immagine è un gatto, 1 se è un cane
tf.keras.layers.Dense(1, activation='sigmoid')
])Come menzionato, convoluzioni e aggregazioni vanno spesso insieme. Il loro numero però è arbitrario e va testato dall'analista. Magari aumentando o diminuendo questo numero di strati la performance aumenta. L'unico modo per capirlo è di sperimentare.
L'output dell'ultimo neurone viene infine sottoposto alla funzione di attivazione sigmoide che restituisce 0 oppure 1.
Utilizziamo ora model.summary() per comprendere come il dato viene trasformato dalla rete neurale e come questo venga convertito in una classe binaria.
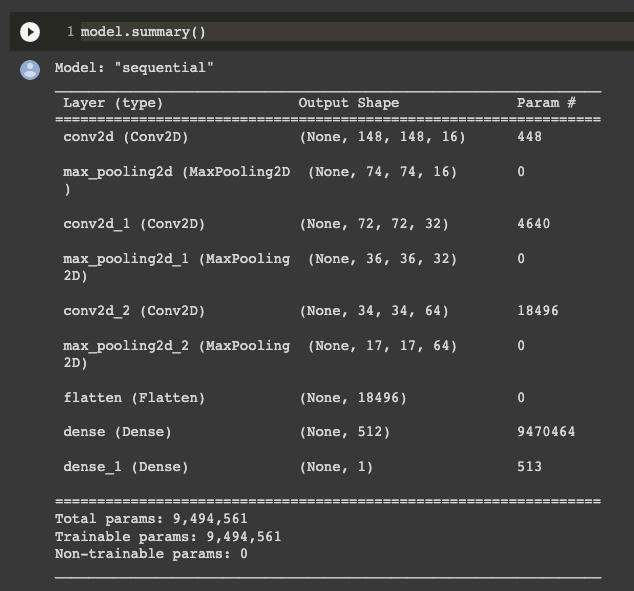
Vediamo come, a cascata, la nostra immagine venga ridotta dalla convoluzione e successivamente compressa ulteriormente dal pooling. Dobbiamo porre particolare attenzione alla colonna Output Shape, in quanto ci mostra proprio il percorso del dato nella rete. Vediamo come nel primo strato conv2d l'output shape sia 148, 148, 64.
Analizziamo un attimo meglio questa informazione. Come mai se le nostre immagini sono 150x150, la rete neurale prende in input una immagine 148x148? La risposta è perché la convoluzione che stiamo usando utilizza una griglia 3x3. I primi pixel intorno all'immagine non hanno dei pixel vicini per permettere la sovrapposizione del filtro. Viene quindi rimosso un pixel sull'asse X e Y, riducendo il margine dell'immagine proprio di 1 pixel. Il 64 sta per il numero di convoluzioni applicati all'immagine.

In seguito alla prima convoluzione vediamo come lo strato di max pooling vada a ridurre la dimensione dell'immagine, riducendolo esattamente della metà. Il processo continua fino a che non arriviamo allo strato flatten, che prende l'output arrivato a quel punto e lo appiattisce in un singolo vettore.
Questo viene fornito ad uno strato denso di 512 neuroni e poi si arriva alla fine della rete con l'output singolo, 0 oppure 1.
Per dire a TensorFlow che l'architettura del modello è conclusa dobbiamo usare il comando compile. Useremo l'ottimizzatore Adam, una loss function di crossentropia binaria e l'accuratezza come metrica di performance.
model.compile(optimizer="adam",
loss='binary_crossentropy',
metrics = ['accuracy'])Procediamo ora con lo scrivere la pipeline di pre-processing delle immagini da fornire al modello.
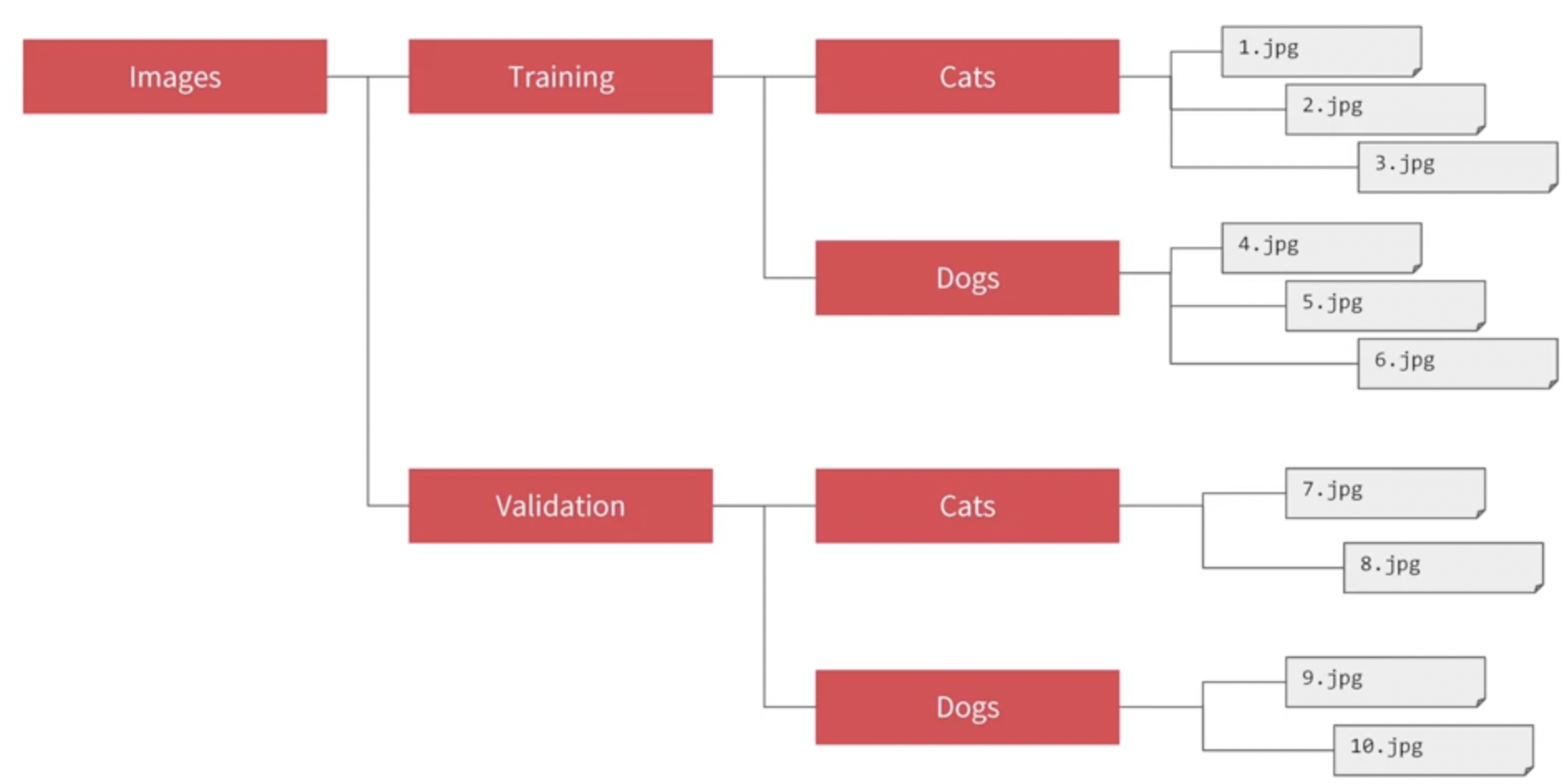
Preprocessing e consegna delle immagini al modello
Il prossimo step è quello di fare preprocessing sulle immagini per assicuraci che siano adatte al nostro modello. Esse verranno ridimensionate a prescindere dalla dimensione originale, convertite in float64 e associate alla loro etichetta (cane o gatto). Queste informazioni verranno poi consegnate al modello.
Creeremo due generatori: uno per l'addestramento e uno per la validazione. Ognuno di questi, inoltre, convertirà le immagini in valori numerici normalizzati tra 0 e 255. 255 è il valore massimo di un pixel, quindi un pixel di intensità 255 diventerà 1 mentre un pixel "spento" sarà 0 e ogni valore intermedio sarà proprio compreso tra 0 e 1.
In TensorFlow tutto questo viene fatto con ImageDataGenerator. Una delle particolarità che rende ImageDataGenerator così potente è che genera etichette per le nostre immagini automaticamente, basandosi sulla gerarchia e nomenclatura delle cartelle che contengono le immagini.
Vediamo come implementare i generatori in Python. Questi ora verranno usati per addestrare il modello, ma non dovremmo preoccuparci di riscalare manualmente le immagini o di fare labeling. Il lavoro sporco lo fa tutto TensorFlow ;)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# riscaliamo tutte le nostre immagini con il parametro rescale
train_datagen = ImageDataGenerator(rescale = 1.0/255)
test_datagen = ImageDataGenerator(rescale = 1.0/255)
# utilizziamo flow_from_directory per creare un generatore per il training
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))
# utilizziamo flow_from_directory per creare un generatore per la validazione
validation_generator = test_datagen.flow_from_directory(validation_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))Addestramento del modello
Addestreremo il modello su 2000 immagini e lo valideremo su 1000. Faremo questo per 15 epoche.
history = model.fit(
train_generator, # passiamo il generatore per il training
steps_per_epoch=100,
epochs=15,
validation_data=validation_generator, # passiamo il generatore per la validazione
validation_steps=50,
verbose=2
)Steps_per_epoch denota il numero di batches da selezionare per un'epoca. Se vengono selezionati 500 steps, la rete userà 500 batch per completare un'epoca. Vediamo le performance del modello durante il training.
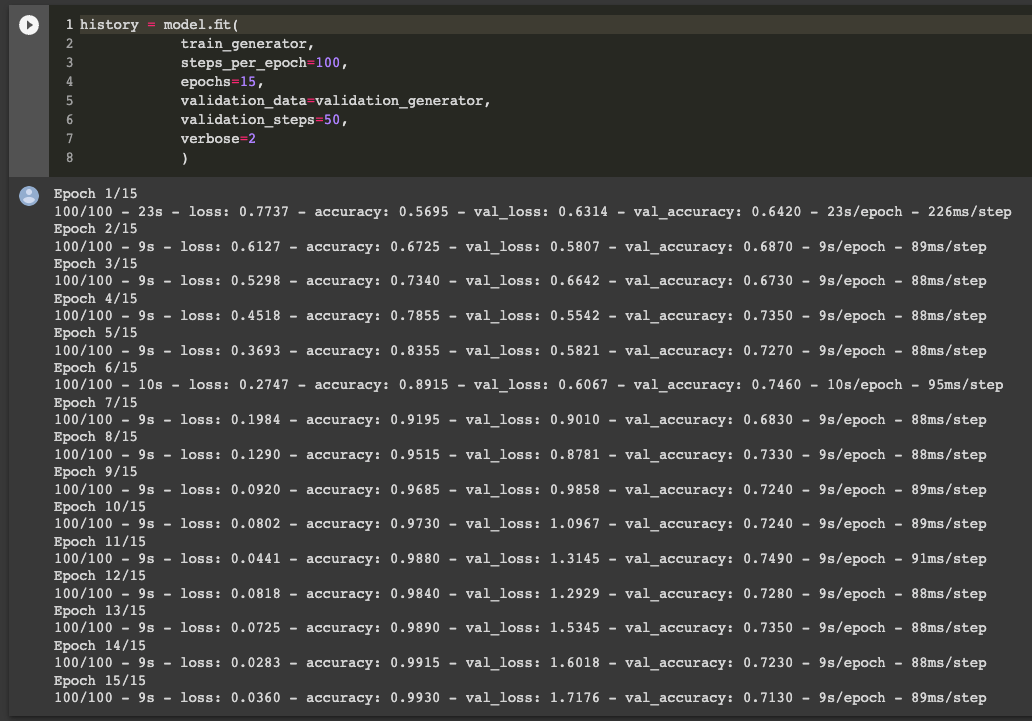
Vediamo come l'accuracy del nostro modello sia intorno al 71% sul set di validazione. Non male ma nemmeno benissimo - su un dataset così piccolo 71% è soddisfacente a mio avviso! Aumentare il numero di immagini darebbe sicuramente risultati più solidi.
Visualizzare le rappresentazioni neurali
Una delle cose più interessanti è vedere come una rete neurale convoluzionale estragga le informazioni salienti dalle immagini e le rappresenti mentre passano tra i vari strati. Useremo un modello di Keras per fare ciò, e gli passeremo gli input del modello convoluzionale addestrato precedentemente.
Questa porzione di codice è un po' avanzata, quindi sentitevi liberi di saltarla oppure eseguirla meramente per l'output (che è molto interessante!)
import numpy as np
import random
from tensorflow.keras.preprocessing.image import img_to_array, load_img
# definiamo un nuovo modello custom di Keras che riceve una immagine in input
# e restituisce le rappresentazioni degli strati del modello precedente
successive_outputs = [layer.output for layer in model.layers]
visualization_model = tf.keras.models.Model(inputs=model.input, outputs=successive_outputs)
# prepariamo una immagine a caso dal nostro dataset
cat_img_files = [os.path.join(train_cats_dir, f) for f in train_cat_fnames]
dog_img_files = [os.path.join(train_dogs_dir, f) for f in train_dog_fnames]
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150)) # questa è una immagine grezza in formato PIL
x = img_to_array(img) # array numpy con dimensione (150, 150, 3)
x = x.reshape((1,) + x.shape) # array numpy con dimensione 1, 150, 150, 3)
# normalizziamo i valori dei pixel per 1/255
x /= 255.0
# facendo una previsione non facciamo altro che ottenere
# le rappresentazioni "intermedie" di questa immagine dal modello precedente
successive_feature_maps = visualization_model.predict(x)
# mappiamo gli strati di questo modello con il loro nome
layer_names = [layer.name for layer in model.layers]
# plottiamo il tutto
for layer_name, feature_map in zip(layer_names, successive_feature_maps):
if len(feature_map.shape) == 4: # se è uno strato convoluzionale o di pooling
n_features = feature_map.shape[-1] # numero di feature
size = feature_map.shape[ 1] # dimensione
# creiamo una griglia per visualizzare i dati
display_grid = np.zeros((size, size * n_features))
# un po' di post processing per capirci qualcosa
for i in range(n_features):
x = feature_map[0, :, :, i]
x -= x.mean()
x /= x.std ()
x *= 64
x += 128
x = np.clip(x, 0, 255).astype('uint8')
display_grid[:, i * size : (i + 1) * size] = x
# mostriamo il grafico
scale = 20. / n_features
plt.figure( figsize=(scale * n_features, scale) )
plt.title ( layer_name )
plt.grid ( False )
plt.imshow( display_grid, aspect='auto', cmap='viridis' ) Ecco il risultato
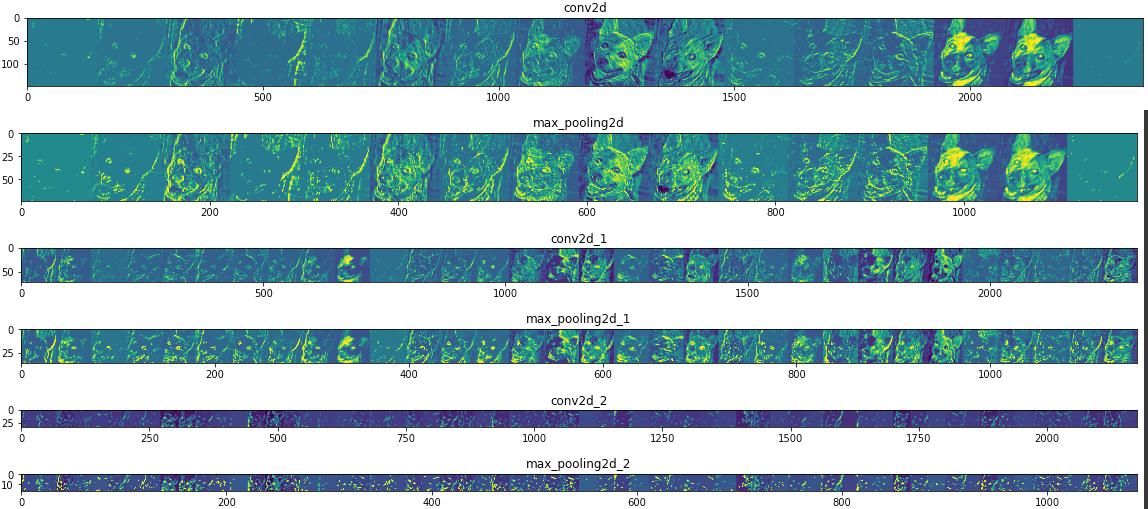
Vediamo come le feature più salienti vengano passate di strato in strato e che rendono tale il cane preso in esempio. Vediamo come spiccano le orecchie, gli occhi e il muso. Queste feature vengono mantenute attraverso tutte (o quasi) le rappresentazioni negli strati e servono a far comprendere alla rete neurale com'è fatto un cane. Molto interessante!
Questa tecnica di visualizzare le rappresentazioni della rete neurale è utile perché ci aiuta a comprendere cosa mettono in risalto le convoluzioni e le aggregazioni. Se ci sono cose che non vanno questo è il primo luogo dove andare a guardare. Ad esempio, la rete potrebbe mettere in risalto feature non inerenti che la portano a sbagliare la predizione. In questo caso una analisi manuale è d'obbligo e dovremmo agire sull'architettura della rete.
Valutazione del modello
Prima di passare alla previsione di immagini nuove, vediamo come scrivere il codice che permette mostrare su grafico l'andamento di loss e di accuracy nel set di addestramento e di validazione.
# recuperiamo le metriche che ci interessano da history
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
# plottiamo la accuracy con matplotlib
plt.plot(epochs, acc)
plt.plot(epochs, val_acc)
plt.title('Accuracy in training e validazione')
plt.figure()
# plottiamo la loss con matplotlib
plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Loss in training e validazione')Ecco i risultati - si nota dell'overfitting nel training set. Questo è dovuto alle dimensioni ridotte del dataset, come menzionato. Si nota come nel training la accuracy raggiunga velocemente, già dopo la seconda epoca, una accuracy tra il 95-99%. L'overfitting si verifica quando un modello esposto a un numero insufficiente di esempi apprende pattern che non si generalizzano a nuovi dati, ovvero quando il modello inizia a utilizzare feature irrilevanti per fare previsioni.
L'overfitting è IL problema numero uno nel machine learning, ed è un termine che leggerete parecchie volte in questo blog. Da analisti, il nostro primo obiettivo è quello di evitare l'overfitting e di rendere un modello quanto più generalizzabile possibile.
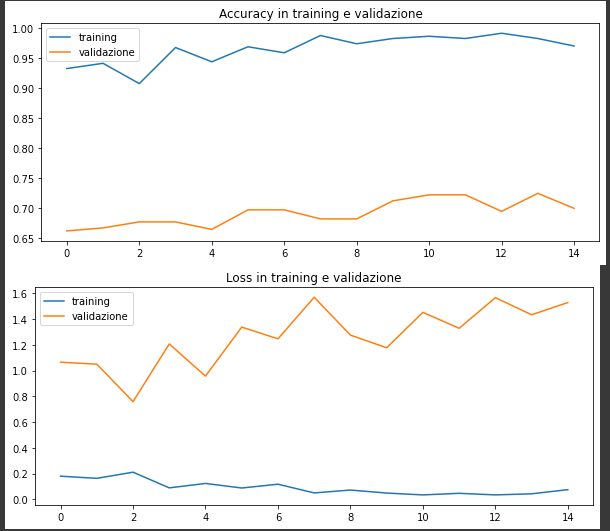
Il lettore interessato può leggere di più su overfitting e perché è uno degli ostacoli più importanti nel machine learning.
Predizioni su immagini nuove
Siamo arrivati alla conclusione di questo articolo. Grazie per la tua attenzione! Ricordati di lasciare un commento o di condividere questo post con un collega se hai voglia :) Vediamo ora come caricare una immagine su Colab e usarla per effettuare una classificazione usando il nostro modello predittivo.
Useremo questa immagine di un cucciolo di Labrador per testare il modello.

Ecco il codice
import numpy as np
from google.colab import files
from keras.preprocessing import image
uploaded = files.upload()
for fn in uploaded.keys():
# predizione di una immagine caricata
path = '/content/' + fn # carichiamo l'immagine su Colab
img = image.load_img(path, target_size=(150, 150)) # e usiamo load_img per scalarla alla dimensione target
# scaliamo i valori
x = image.img_to_array(img)
x /= 255
x = np.expand_dims(x, axis=0)
# appiattiamo l'output
images = np.vstack([x])
# eseguiamo la predizione
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0] > 0.5:
print(fn + " è un cane!")
else:
print(fn + " è un gatto!")E infine ecco la predizione corretta del nostro modello!






Commenti dalla community