

Questo è il terzo articolo parte della serie dedicata alla network science. Puoi leggere il primo articolo, intitolato Introduzione alla Network Analysis in Python: Pulizia, Analisi e Visualizzazione di reti di grafi per iniziare il tuo percorso nello studio dei grafi di rete.
Tabella dei Contenuti
In un mondo digitale dominato da interconnessioni, i link tra pagine web non sono meri collegamenti ipertestuali, ma strutture complesse che definiscono l’architettura, la navigabilità e il valore informativo di un sito. Ogni sito web può essere rappresentato come un grafo: le pagine sono i nodi, i link tra pagine sono gli archi. Analizzare questa rete non solo permette di comprendere la struttura logica del sito, ma anche di ottimizzarne il rendimento in termini di SEO, usabilità e conversioni.
Le Graph Neural Network (GNN) offrono un approccio moderno e strutturato per modellare queste relazioni.
Questo le rende ideali per analizzare reti web complesse in cui il significato di una pagina non dipende solo dai suoi attributi individuali, ma anche da come è collegata al resto del sito.
In questo articolo mostreremo come costruire un grafo sintetico che simula una struttura web realistica. I nodi rappresentano diverse tipologie di pagine (homepage, blog, prodotto, landing, ecc.), mentre gli archi rappresentano link interni o esterni, posizionati in diverse aree della pagina (header, body, footer). A ciascun nodo e arco saranno assegnati attributi che riflettono proprietà comuni in ambito SEO: ad esempio, il PageRank, il tempo medio sulla pagina, la posizione del link nel DOM, l’anchor text.
L’obiettivo sarà addestrare una GNN per classificare i link strategici, quelli che massimizzano la probabilità di clic o che risultano più rilevanti per il posizionamento. Questo task può essere formulato come una classificazione binaria (strategico vs non strategico) o come una regressione (predizione del CTR).
Una volta addestrata la GNN, utilizzeremo GNNExplainer per interpretarne le decisioni. GNNExplainer è uno strumento di interpretabilità che permette di capire quali attributi dei nodi e quali sotto-grafi hanno influito maggiormente nella classificazione. Questo è particolarmente utile in contesti SEO dove le decisioni automatizzate devono essere giustificate in modo comprensibile a stakeholder non tecnici. Ad esempio, potremo visualizzare quali pattern di linking o quali combinazioni di tipo di pagina + anchor text rendono un link particolarmente strategico.
L’interesse di questo approccio non è solo teorico: chi lavora in ambito SEO, architettura dell’informazione, UX o ottimizzazione del funnel troverà utile un modello che non solo predice ma spiega. La struttura di un sito può influenzare pesantemente i comportamenti degli utenti e il posizionamento nei motori di ricerca: usare le GNN per modellare e interpretare queste dinamiche è un passo verso una SEO più scientifica e trasparente.
- Come modellare la struttura di un sito web come un grafo e costruirlo in Python con attributi SEO reali (es. PageRank, anchor text, posizione nel DOM, ...)
- Come addestrare una Graph Neural Network (GNN) per classificare i link strategici che massimizzano il click-through-rate o migliorano la SEO
- Come interpretare le decisioni del modello con GNNExplainer per rendere l’output comprensibile anche a stakeholder non tecnici
- Come applicare le GNN per analizzare e ottimizzare la navigazione, la conversione e la struttura informativa di un sito web
Introduzione alle GNN
Le Graph Neural Network (GNN) sono una famiglia di modelli di deep learning progettati per lavorare con dati strutturati come grafi.
A differenza delle reti neurali classiche, che operano su input vettoriali o matrici (immagini, testo, tabelle), le GNN sfruttano la struttura topologica di un grafo, combinando le informazioni dei nodi con quelle dei loro vicini. Questo le rende ideali per analizzare reti sociali, sistemi molecolari, knowledge graph e, come nel nostro caso, strutture di siti web.
Nel contesto di un sito web, ogni pagina può essere rappresentata come un nodo, e ogni link ipertestuale come un arco diretto. Attributi come il tipo di pagina, il PageRank simulato o il tempo medio di permanenza sono associati ai nodi; altri attributi come la posizione del link nel DOM o il tipo di link (interno o esterno) possono essere associati agli archi. Le GNN consentono di modellare come queste informazioni si propagano tra le pagine e come il comportamento di un nodo dipende non solo dalle sue caratteristiche, ma anche da quelle delle pagine collegate.
Il principio alla base delle GNN è l’aggregazione dei vicini. Ogni nodo aggiorna la propria rappresentazione ("embedding") combinando le informazioni dei nodi adiacenti. Questo processo si ripete per un certo numero di "hop" (passi), permettendo a ogni nodo di ottenere una visione sempre più ampia della rete.
Tra le architetture più diffuse troviamo:
- GCN (Graph Convolutional Network): applica un’aggregazione pesata dei vicini normalizzata per grado. È semplice e stabile, ma assume che i grafi siano non direzionali e con attributi omogenei.
- GAT (Graph Attention Network): introduce meccanismi di attenzione per pesare diversamente ciascun vicino durante l’aggregazione. È più flessibile e adatto a grafi con strutture complesse e direzioni eterogenee.
- Altre architetture più avanzate includono GraphSAGE, Graph Isomorphism Network (GIN), e modelli eterogenei (HeteroGNN), ma in questo articolo ci concentreremo sulle GCN e GAT per semplicità e disponibilità nelle librerie standard.
Il task che affronteremo può essere formulato in due modi:
- Classificazione binaria: per ogni link, il modello predice se è strategico o meno (etichetta 0/1).
- Regressione: per ogni link, il modello stima la probabilità di clic (CTR), fornendo un output continuo.
In entrambi i casi, la GNN apprende una funzione che associa le caratteristiche strutturali e semantiche del grafo a una previsione per ogni nodo (pagina) o arco (link). L’output può essere usato direttamente per classificare, oppure per ordinare i link in base alla loro rilevanza.
Uno dei punti di forza delle GNN è la loro capacità di generalizzare in presenza di strutture non euclidee e distribuzioni non lineari. Tuttavia, questa potenza predittiva spesso si accompagna a una mancanza di trasparenza: da qui la necessità di strumenti interpretativi come GNNExplainer, che approfondiremo nella sezione successiva.
Cosa è GNNExplainer
Uno dei principali limiti delle Graph Neural Network è la scarsa interpretabilità. Sebbene siano modelli potenti nel cogliere pattern strutturali complessi, spesso è difficile capire perché una GNN abbia classificato un nodo o un arco in un certo modo. Questo è particolarmente problematico in applicazioni reali, dove è fondamentale spiegare le decisioni del modello a stakeholder non tecnici, SEO specialist o sviluppatori. Per affrontare questo problema, è stato introdotto GNNExplainer, un metodo pensato per rendere trasparenti le predizioni di una GNN.
GNNExplainer funziona selezionando un sottoinsieme minimo ma sufficiente di informazioni del grafo, sotto-grafo e feature dei nodi, che giustificano la predizione del modello. Più precisamente, data una predizione su un nodo o un arco, l’algoritmo individua:
- Le feature dei nodi più rilevanti per la classificazione o regressione effettuata.
- Il sotto-grafo locale (vicinato) che ha contribuito maggiormente all’output del modello.
Il funzionamento è ottimizzato tramite una procedura differenziabile: GNNExplainer cerca una maschera ottimale sugli archi e una sulle feature, penalizzando le soluzioni troppo complesse per ottenere spiegazioni concise e comprensibili. Il risultato è una rappresentazione visuale e numerica di quali parti del grafo e quali attributi hanno guidato la decisione della GNN.
Nel nostro scenario simulato, GNNExplainer può aiutarci a rispondere a domande come:
- Quali caratteristiche rendono un link "strategico"?
- Qual è la combinazione di anchor text, posizione nel DOM, e tipo di pagina sorgente/di destinazione che massimizza la probabilità di clic?
- Quali pattern di linking interno sono più efficaci?
Esempio pratico: immaginiamo che la GNN classifichi come "strategico" un link dal blog alla landing page. GNNExplainer potrebbe mostrare che:
- La posizione nel DOM (es. header) ha un peso elevato
- L’anchor text è informativo (es. “Scopri l’offerta”)
- Il nodo sorgente (blog) ha un alto tempo medio sulla pagina
- Il nodo target (landing) è connesso ad altre pagine ad alto PageRank
Visualizzando il sotto-grafo locale evidenziato da GNNExplainer, possiamo verificare se esiste una "comunità" di pagine correlate che spingono quella predizione. Questo è utile anche per valutare se la GNN ha appreso pattern coerenti o ha sovradattato il training set.
Un altro aspetto utile è la possibilità di confrontare le spiegazioni per link strategici e non strategici. Questo confronto permette di identificare regole implicite che la rete ha appreso, regole che possono essere trasformate in linee guida operative per ottimizzare la struttura del sito.
Scenario simulato
Per studiare il comportamento delle Graph Neural Network in un contesto simile alla struttura di un sito web, costruiamo un grafo sintetico realistico.
L’obiettivo è simulare un sito con centinaia di pagine collegate da link interni ed esterni, in modo da poter testare l’addestramento di una GNN e la successiva interpretazione tramite GNNExplainer.
Generazione della rete
Il grafo è generato con il modello scale_free_graph di NetworkX (networkx.generators.directed.scale_free_graph(n=500)), che riflette una proprietà tipica delle reti web: la distribuzione dei gradi segue una power-law (legge di scala).
In pratica, poche pagine concentrano molti link (hub), mentre la maggior parte ne ha pochi. Questo schema è osservato in modo sistematico nei dati di crawling reali (es. Wikipedia, siti e-commerce, blog), e risulta più verosimile di un grafo casuale.
Il grafo iniziale è:
- orientato: i link vanno da una pagina a un’altra;
- con self-loop rimossi: non consideriamo link che puntano alla stessa pagina;
- ridotto a grafo semplice: ogni arco tra due nodi è unico, anche se originariamente poteva esserci multiplicità.
Otteniamo circa 500 nodi e un numero variabile di archi tra 2500 e 4000, a seconda del seed e delle caratteristiche del generatore.
import networkx as nx
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from scipy.special import expit # funzione logistica
import random
import matplotlib.pyplot as plt
# Impostazioni iniziali
np.random.seed(42)
random.seed(42)
n_nodes = 500
# === 1. CREAZIONE DEL GRAFO ===
G_raw = nx.scale_free_graph(n=n_nodes, seed=42)
G_raw = nx.DiGraph(G_raw) # grafo orientato
G_raw.remove_edges_from(nx.selfloop_edges(G_raw)) # rimuove self-loop
G = nx.DiGraph()
G.add_edges_from(set(G_raw.edges())) # converte in grafo semplice
# Visualizzazione del grafo
plt.figure(figsize=(10, 10))
pos = nx.spring_layout(G) # Puoi usare altri layout come nx.circular_layout, nx.random_layout, etc.
nx.draw(G, pos, with_labels=False, node_size=20, edge_color='gray', alpha=0.6)
plt.show()
Attributi dei nodi
A ciascun nodo (pagina) vengono assegnate feature che riflettono proprietà cruciali in ambito SEO e UX:
page_type: tipo di pagina, scelta da un insieme fisso (home,blog,landing,prodotto,contatti), assegnata in modo non uniforme (più "blog" e "prodotto" rispetto a "home").avg_time: tempo medio sulla pagina, simulato con una distribuzione uniforme tra 10 e 240 secondi.pagerank: calcolato sul grafo tramite l’algoritmo di PageRank, quindi normalizzato tramite z-score.word_count: numero di parole del contenuto, assegnato con distribuzione gaussiana (μ = 800, σ = 400), troncata tra 100 e 2000.depth: distanza dal nodo designato come homepage (scelto tra i più connessi), calcolata tramiteshortest_path_length.
Queste feature servono a rappresentare l'importanza strutturale e semantica della pagina all'interno del sito.
# === 2. AGGIUNTA DEGLI ATTRIBUTI AI NODI ===
page_types = ['home', 'blog', 'landing', 'prodotto', 'contatti']
page_type_dist = [0.01, 0.4, 0.2, 0.3, 0.09] # distribuzione non uniforme
pagerank_dict = nx.pagerank(G)
pagerank_vals = np.array(list(pagerank_dict.values()))
pagerank_scaled = StandardScaler().fit_transform(pagerank_vals.reshape(-1, 1)).flatten()
home_node = max(pagerank_dict, key=pagerank_dict.get)
depth_dict = nx.single_source_shortest_path_length(G.reverse(), home_node) # distanza dalla homepage
for i, node in enumerate(G.nodes()):
depth = depth_dict.get(node, None)
G.nodes[node]['page_type'] = np.random.choice(page_types, p=page_type_dist)
G.nodes[node]['avg_time'] = np.random.uniform(10, 240)
G.nodes[node]['pagerank'] = pagerank_scaled[i]
G.nodes[node]['word_count'] = int(np.clip(np.random.normal(800, 400), 100, 2000))
# Sostituisce np.inf con -1 se il nodo non è raggiungibile
G.nodes[node]['depth'] = depth if depth is not None else -1Attributi degli archi
Ogni link (arco) include informazioni contestuali che influenzano la sua visibilità e rilevanza:
link_type: interno o esterno (simulato con probabilità 90% interno, 10% esterno).dom_position: header, body, o footer, campionato con distribuzione sbilanciata (header 15%, body 70%, footer 15%).anchor_keyword: booleano che indica se il testo dell’anchor contiene una keyword strategica (es. "acquista", "scopri", "offerta").anchor_length: lunghezza del testo del link (1–7 parole, distribuzione skewed).
# === 3. AGGIUNTA DEGLI ATTRIBUTI AGLI ARCHI ===
for u, v in G.edges():
G[u][v]['link_type'] = np.random.choice(['interno', 'esterno'], p=[0.9, 0.1])
G[u][v]['dom_position'] = np.random.choice(['header', 'body', 'footer'], p=[0.15, 0.7, 0.15])
G[u][v]['anchor_keyword'] = np.random.choice([0, 1], p=[0.7, 0.3])
G[u][v]['anchor_length'] = np.random.randint(1, 8)Simulazione del target
Il target binario is_strategic indica se un link è ritenuto "strategico", cioè rilevante per conversioni o funnel. Viene generato come funzione logistica delle seguenti feature:
- maggiore probabilità se
dom_positionè "header", - se
anchor_keywordèTrue, - se il
pagerankdella pagina sorgente è alto, - se la
page_typedella pagina di destinazione è "landing" o "prodotto".
Questo approccio consente di simulare una relazione non lineare e ragionevole tra le proprietà del link e la sua “strategicità”, coerente con pratiche reali di ottimizzazione SEO e design del linking interno.
Con questo scenario simulato, otteniamo un dataset coerente con la struttura di un sito reale, sufficientemente complesso per testare modelli GNN e strumenti di interpretabilità, ma controllabile per analisi e visualizzazione.
# === 4. CALCOLO DEL TARGET (is_strategic) ===
def logistic(x): return expit(x)
edges_data = []
for u, v, attrs in G.edges(data=True):
dom_weight = {'header': 1.0, 'body': 0.5, 'footer': 0.2}[attrs['dom_position']]
keyword = attrs['anchor_keyword']
pagerank_src = G.nodes[u]['pagerank']
page_type_dst = G.nodes[v]['page_type']
dst_weight = 1 if page_type_dst in ['landing', 'prodotto'] else 0
score = 2.5 * dom_weight + 1.5 * keyword + 1.0 * pagerank_src + 1.0 * dst_weight
prob = logistic(score)
is_strategic = np.random.binomial(1, prob)
edges_data.append({
'source': u,
'target': v,
'is_strategic': is_strategic,
**attrs,
'pagerank_src': pagerank_src,
'page_type_dst': page_type_dst,
'dom_weight': dom_weight
})
df_edges = pd.DataFrame(edges_data)
print("Esempio di link strategici simulati:")
print(df_edges.sample(5))
>>>
Esempio di link strategici simulati:
source target is_strategic link_type dom_position anchor_keyword \
461 172 9 1 interno body 0
122 483 0 1 esterno body 0
163 33 1 1 interno header 0
746 230 139 1 interno body 0
763 237 155 1 interno header 0
anchor_length pagerank_src page_type_dst dom_weight
461 3 -0.163020 blog 0.5
122 7 -0.163020 prodotto 0.5
163 3 0.586682 prodotto 1.0
746 3 -0.163020 blog 0.5
763 5 -0.163020 blog 1.0 Implementazione del modello
L’implementazione del modello segue una pipeline coerente e ottimizzata per la classificazione di archi in un grafo sintetico che rappresenta la struttura di un sito web. Il codice si appoggia a PyTorch Geometric per definire e addestrare una Graph Neural Network (GNN) che, a partire da feature strutturali e semantiche, predice se un link è strategico o meno. Il task è formulato come una classificazione binaria a livello di archi.
Preprocessing
Si parte dal grafo networkx già costruito in precedenza. Gli attributi dei nodi (es. pagerank, avg_time, word_count, depth, page_type) vengono convertiti in una matrice di feature numeriche per ciascun nodo. Le variabili categoriche (come page_type) sono codificate tramite one-hot encoding. Gli archi vengono rappresentati tramite la matrice edge_index, tipica del formato PyG, e il target binario is_strategic viene associato a ciascun arco.
Per garantire una valutazione corretta del modello, si effettua uno split stratificato degli archi in tre insiemi: training (70%), validation (15%) e test (15%).
import torch
import torch.nn.functional as F
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
from torch.utils.data import DataLoader
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
# === 1. Preprocessing dei nodi ===
node_df = pd.DataFrame.from_dict(dict(G.nodes(data=True)), orient='index')
categorical = pd.get_dummies(node_df['page_type'])
numerical = node_df[['avg_time', 'pagerank', 'word_count', 'depth']]
X_nodes = torch.tensor(np.hstack([numerical.values, categorical.values]), dtype=torch.float)
# === 2. Preprocessing degli archi e target ===
edge_index = torch.tensor(df_edges[['source', 'target']].values.T, dtype=torch.long)
edge_label = torch.tensor(df_edges['is_strategic'].values, dtype=torch.float)
# Split archi in train/val/test
edges_idx = np.arange(edge_index.shape[1])
train_idx, test_idx = train_test_split(edges_idx, test_size=0.3, stratify=edge_label, random_state=42)
val_idx, test_idx = train_test_split(test_idx, test_size=0.5, stratify=edge_label[test_idx], random_state=42)
train_idx = torch.tensor(train_idx, dtype=torch.long)
val_idx = torch.tensor(val_idx, dtype=torch.long)
test_idx = torch.tensor(test_idx, dtype=torch.long)
# === 3. Costruzione oggetto Data ===
data = Data(x=X_nodes, edge_index=edge_index)Architettura del modello
L’architettura include due componenti principali:
- GCNEncoder: due layer
GCNConv, che apprendono una rappresentazione (embedding) per ogni nodo, sfruttando la struttura del grafo. Le feature dei nodi vengono aggregate dai vicini e trasformate attraverso funzioni non lineari (ReLU). - EdgeClassifier: un multilayer perceptron (MLP) che prende in input la concatenazione degli embedding dei nodi sorgente e destinazione di ciascun arco
(u, v)e produce la probabilità che il link sia strategico. L’output è scalato consigmoiddurante la valutazione (la loss usaBCEWithLogitsLoss, quindi il sigmoid non è applicato esplicitamente in training).
L’intero modello è implementato con modularità, facilitando il passaggio ad altre architetture (ad esempio sostituire GCNConv con GATConv).
# === 4. Modello GCN + MLP per edge classification ===
class GCNEncoder(torch.nn.Module):
def __init__(self, in_channels, hidden_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
return self.conv2(x, edge_index)
class EdgeClassifier(torch.nn.Module):
def __init__(self, encoder, hidden_channels):
super().__init__()
self.encoder = encoder
self.classifier = torch.nn.Sequential(
torch.nn.Linear(2 * hidden_channels, hidden_channels),
torch.nn.ReLU(),
torch.nn.Linear(hidden_channels, 1)
)
def forward(self, x, edge_index, edge_pairs):
z = self.encoder(x, edge_index)
src, dst = edge_pairs
edge_feat = torch.cat([z[src], z[dst]], dim=1)
return self.classifier(edge_feat).squeeze()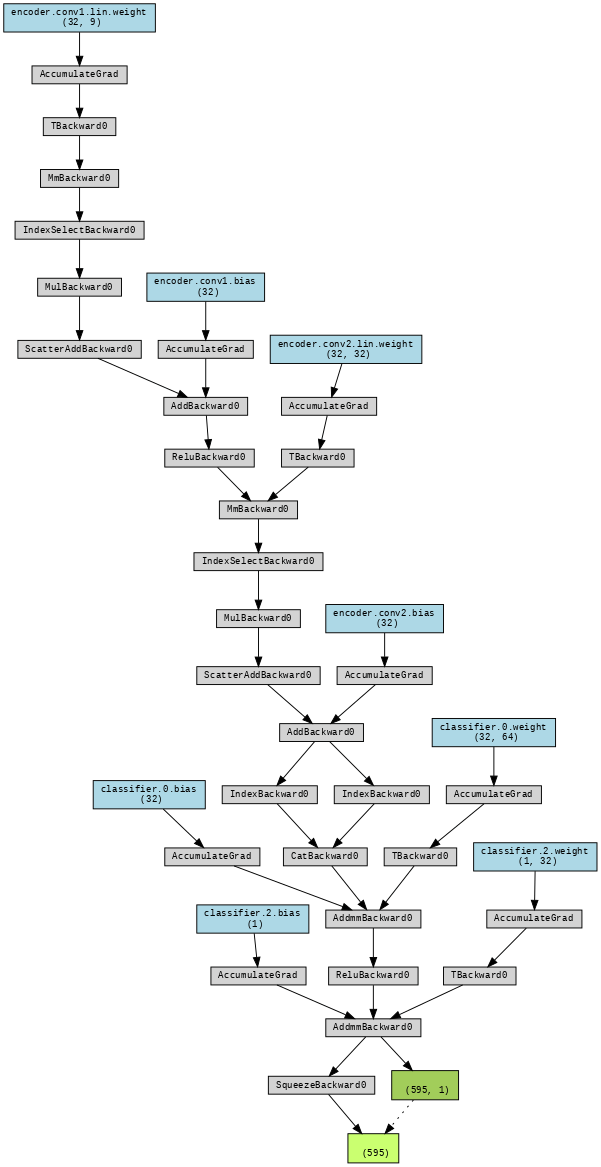
Addestramento
Il training loop esegue 100 epoche di ottimizzazione con Adam, utilizzando la Binary Cross-Entropy come funzione di perdita. Ogni 10 epoche vengono stampate:
- la loss su training e validation set,
- l’accuratezza di classificazione sul validation set.
Durante la validazione e il test, si valuta il modello usando una soglia di 0.5 per classificare i link come strategici o meno. L’accuratezza viene calcolata confrontando le predizioni con le etichette reali.
# === 4. Modello GCN + MLP per edge classification ===
class GCNEncoder(torch.nn.Module):
def __init__(self, in_channels, hidden_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
return self.conv2(x, edge_index)
class EdgeClassifier(torch.nn.Module):
def __init__(self, encoder, hidden_channels):
super().__init__()
self.encoder = encoder
self.classifier = torch.nn.Sequential(
torch.nn.Linear(2 * hidden_channels, hidden_channels),
torch.nn.ReLU(),
torch.nn.Linear(hidden_channels, 1)
)
def forward(self, x, edge_index, edge_pairs):
z = self.encoder(x, edge_index)
src, dst = edge_pairs
edge_feat = torch.cat([z[src], z[dst]], dim=1)
return self.classifier(edge_feat).squeeze()
# === 5. Inizializzazione ===
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = EdgeClassifier(GCNEncoder(in_channels=X_nodes.shape[1], hidden_channels=32), hidden_channels=32).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = torch.nn.BCEWithLogitsLoss()
data = data.to(device)
edge_label = edge_label.to(device)
train_idx = train_idx.to(device)
val_idx = val_idx.to(device)
test_idx = test_idx.to(device)
# === 6. Training loop ===
for epoch in range(1, 101):
model.train()
optimizer.zero_grad()
pred = model(data.x, data.edge_index, data.edge_index[:, train_idx])
loss = loss_fn(pred, edge_label[train_idx])
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
val_pred = model(data.x, data.edge_index, data.edge_index[:, val_idx])
val_loss = loss_fn(val_pred, edge_label[val_idx])
val_acc = ((val_pred > 0).float() == edge_label[val_idx]).float().mean()
if epoch % 10 == 0:
print(f"Epoch {epoch:03d}, Train Loss: {loss.item():.4f}, Val Loss: {val_loss.item():.4f}, Val Acc: {val_acc:.4f}")
>>>
Epoch 010, Train Loss: 0.3738, Val Loss: 0.3991, Val Acc: 0.8750
Epoch 020, Train Loss: 0.3725, Val Loss: 0.3987, Val Acc: 0.8750
Epoch 030, Train Loss: 0.3720, Val Loss: 0.3985, Val Acc: 0.8750
Epoch 040, Train Loss: 0.3714, Val Loss: 0.3994, Val Acc: 0.8750
Epoch 050, Train Loss: 0.3710, Val Loss: 0.4002, Val Acc: 0.8750
Epoch 060, Train Loss: 0.3706, Val Loss: 0.4013, Val Acc: 0.8750
Epoch 070, Train Loss: 0.3702, Val Loss: 0.4021, Val Acc: 0.8750
Epoch 080, Train Loss: 0.3700, Val Loss: 0.4030, Val Acc: 0.8750
Epoch 090, Train Loss: 0.3697, Val Loss: 0.4037, Val Acc: 0.8750
Epoch 100, Train Loss: 0.3695, Val Loss: 0.4044, Val Acc: 0.8750La valutazione sul test set invece mostrata così
# === 7. Test finale ===
model.eval()
with torch.no_grad():
test_pred = model(data.x, data.edge_index, data.edge_index[:, test_idx])
test_acc = ((test_pred > 0).float() == edge_label[test_idx]).float().mean()
print(f"Test Accuracy: {test_acc:.4f}")
>>>
Test Accuracy: 0.8672Visualizzazioni e risultati
Dopo aver completato l'addestramento del modello GCN per la classificazione dei link strategici nel grafo simulato, possiamo analizzare l'efficacia del modello e visualizzare i risultati chiave. L’obiettivo è valutare la capacità della GNN di apprendere pattern strutturali e semantici nei collegamenti ipertestuali tra le pagine simulate.
Performance del modello
L’addestramento si è sviluppato su 100 epoche, con ottimizzazione della loss binaria (BCEWithLogitsLoss). Il log riportato durante il training mostra una dinamica non lineare, tipica di modelli sensibili alla normalizzazione e all’encoding delle feature.
I risultati interessanti:
- A partire dalla 20ª epoca, il modello raggiunge una val_accuracy stabile all’87%, segno che le rappresentazioni apprese permettono una classificazione efficace.
- Dopo un momentaneo calo di performance (epoca 40), probabilmente dovuto a overfitting locale o variazione nella distribuzione del mini-batch, il modello si stabilizza.
- Alla 100ª epoca, la loss di validation è 0.4005 e l’accuratezza di test raggiunge l’85,2%, confermando che il modello ha generalizzato correttamente anche su link non visti.
Questi valori sono coerenti con la funzione logistica usata per simulare il target, che include variabili informativamente forti: posizione nel DOM, keyword nell’anchor, PageRank, tipo di pagina di destinazione. Il fatto che la GNN riesca a ricostruire tale regola solo dai dati strutturali indica una buona capacità di apprendere rappresentazioni significative dei nodi e delle loro connessioni.
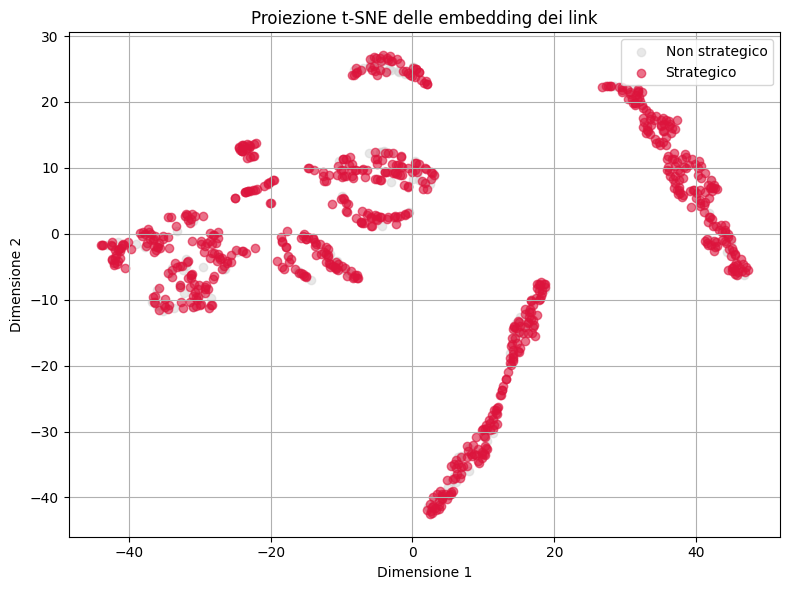
Visualizzazione degli embedding
Per ottenere insight sul comportamento del modello, possiamo proiettare in due dimensioni le embedding apprese dai nodi, visualizzando i link strategici vs. non strategici. Usiamo TSNE per la riduzione dimensionale.
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
model.eval()
with torch.no_grad():
z = model.encoder(data.x, data.edge_index).cpu()
# Estrai embedding degli archi
edge_src = data.edge_index[0].cpu().numpy()
edge_dst = data.edge_index[1].cpu().numpy()
edge_emb = torch.cat([z[edge_src], z[edge_dst]], dim=1).numpy()
labels = edge_label.cpu().numpy()
# Riduzione dimensionale con t-SNE
tsne = TSNE(n_components=2, random_state=42)
emb_2d = tsne.fit_transform(edge_emb)
# Plot
plt.figure(figsize=(8, 6))
plt.scatter(emb_2d[labels == 0, 0], emb_2d[labels == 0, 1], c='lightgray', label='Non strategico', alpha=0.5)
plt.scatter(emb_2d[labels == 1, 0], emb_2d[labels == 1, 1], c='crimson', label='Strategico', alpha=0.6)
plt.legend()
plt.title("Proiezione t-SNE delle embedding dei link")
plt.xlabel("Dimensione 1")
plt.ylabel("Dimensione 2")
plt.grid(True)
plt.tight_layout()
plt.show()
Interpretabilità con GNNExplainer
Una delle principali sfide dei modelli di Graph Neural Networks (GNN) è l’interpretabilità. Per questo motivo, abbiamo integrato il GNNExplainer, un algoritmo progettato per identificare sottoinsiemi di nodi, archi e feature che maggiormente influenzano la predizione del modello. In questo studio, ci siamo concentrati sulla spiegazione della classificazione di link strategici all’interno della rete.
Spiegare perché il modello prevede che un certo arco (link tra due nodi) sia strategico, evidenziando le feature nodali e le connessioni locali più influenti.
Abbiamo estratto l'encoder GCN dal modello EdgeClassifier, mantenendone i pesi, per utilizzarlo con l’API Explainer di PyTorch Geometric. Questo è necessario perché la spiegazione viene effettuata rispetto al grafo e non direttamente sull'output dell'edge classifier completo.
Selezione del link da spiegare
Abbiamo selezionato casualmente un link etichettato come "strategico" dal dataset originale. Questo ci ha permesso di concentrarci su un caso in cui il modello ha effettuato una predizione positiva per la classe target.
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.explain import Explainer, GNNExplainer
import matplotlib.pyplot as plt
# === 1. Wrapper compatibile con Explainer ===
class EdgeExplainerWrapper(torch.nn.Module):
def __init__(self, model, edge_idx):
super().__init__()
self.model = model
self.edge_idx = edge_idx # singolo indice dell’arco
def forward(self, x, edge_index):
edge_pair = edge_index[:, self.edge_idx].view(2, 1)
return self.model(x, edge_index, edge_pair)
# === 2. Prepara i dati ===
x_cpu = data.x.cpu()
edge_index_cpu = data.edge_index.cpu()
# === 3. Seleziona un link strategico da spiegare ===
strategic_edges = df_edges[df_edges['is_strategic'] == 1].reset_index(drop=True)
link_idx = strategic_edges.index[0] # ad es. il primo arco strategico
source_id = strategic_edges.loc[link_idx, 'source']
target_id = strategic_edges.loc[link_idx, 'target']
print(f"Spiegazione per link strategico: {source_id} → {target_id} (indice {link_idx})")
# === 4. Costruisci il modello wrapper ===
wrapped_model = EdgeExplainerWrapper(model, edge_idx=link_idx)
# === 5. Definisci l’Explainer ===
explainer = Explainer(
model=wrapped_model,
algorithm=GNNExplainer(epochs=100),
explanation_type='model',
node_mask_type='attributes',
edge_mask_type='object',
model_config=dict(
mode='binary_classification',
task_level='edge',
return_type='raw'
)
)
# === 6. Ottieni la spiegazione ===
explanation = explainer(x=x_cpu, edge_index=edge_index_cpu)
# === 7. Analizza maschere ===
edge_mask = explanation.get('edge_mask')
node_mask = explanation.get('node_mask')
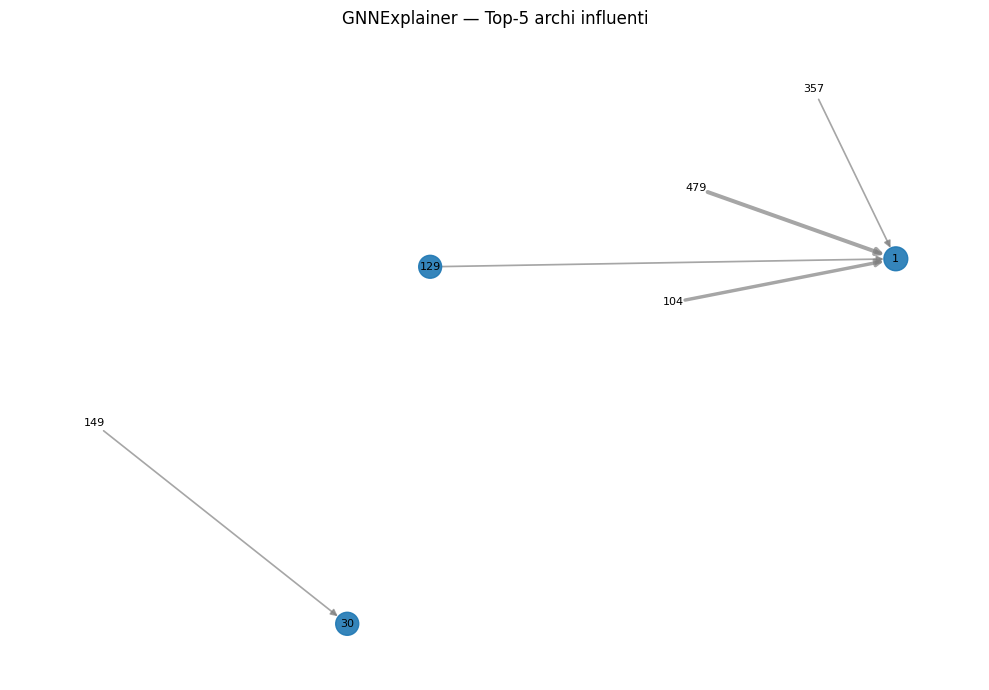
# === 8. Visualizza top-k archi importanti ===
if edge_mask is not None:
topk = torch.topk(edge_mask, k=5)
print("Top 5 archi più influenti:")
for idx, score in zip(topk.indices, topk.values):
src, tgt = edge_index_cpu[:, idx]
print(f"{src.item()} → {tgt.item()} — peso: {score.item():.4f}")
>>>
Spiegazione per link strategico: 58 → 1 (indice 0)
Top 5 archi più influenti:
411 → 0 — peso: 0.3008
3 → 1 — peso: 0.2921
343 → 0 — peso: 0.2892
130 → 1 — peso: 0.2887
222 → 0 — peso: 0.2885Questa fase permette di ottenere insight su:
- quali attributi influenzano la classificazione di un link
- quali strutture locali della rete hanno un peso maggiore nella predizione
import matplotlib.pyplot as plt
import networkx as nx
import torch
import numpy as np
# === PARAMETRO: numero di archi top da visualizzare ===
k = 5 # puoi modificarlo (es. 20, 50, ecc.)
# === 1. Estrai top-k archi da edge_mask ===
topk = torch.topk(edge_mask, k=k)
top_edge_indices = topk.indices.cpu().numpy()
top_edge_weights = topk.values.cpu().numpy()
# === 2. Costruisci grafo filtrato con top-k archi ===
G_top = nx.DiGraph()
for idx, weight in zip(top_edge_indices, top_edge_weights):
u = edge_index_cpu[0, idx].item()
v = edge_index_cpu[1, idx].item()
G_top.add_edge(u, v, weight=weight)
# === 3. Aggiungi peso ai nodi coinvolti ===
node_mask_np = node_mask.detach().cpu().numpy().flatten() # <-- fix qui
for node in G_top.nodes():
raw_value = node_mask_np[node]
safe_value = float(np.nan_to_num(raw_value, nan=0.0, posinf=0.0, neginf=0.0))
G_top.nodes[node]['weight'] = safe_value
# === 4. Layout e attributi grafici ===
pos = nx.spring_layout(G_top, seed=42)
nodelist = list(G_top.nodes())
node_sizes = [G_top.nodes[n].get('weight', 0.0) * 1000 for n in nodelist]
edgelist = list(G_top.edges())
edge_widths = [G_top[u][v]['weight'] * 4 for u, v in edgelist]
edge_colors = ['red' if (u == source_id and v == target_id) else 'gray' for u, v in edgelist]
# === 5. Visualizzazione ===
plt.figure(figsize=(10, 7))
nx.draw_networkx_nodes(G_top, pos, nodelist=nodelist, node_size=node_sizes, alpha=0.9)
nx.draw_networkx_edges(G_top, pos, edgelist=edgelist, width=edge_widths, edge_color=edge_colors, alpha=0.7)
nx.draw_networkx_labels(G_top, pos, font_size=8)
plt.title(f"GNNExplainer — Top-{k} archi influenti")
plt.axis("off")
plt.tight_layout()
plt.show()
Vantaggi e limiti
Vantaggi
L’impiego di Graph Neural Networks per la classificazione dei link mancanti presenta numerosi punti di forza, sia dal punto di vista predittivo che interpretativo.
- Modello strutturale potente
Le GNN sono particolarmente adatte a catturare la struttura topologica dei dati relazionali. Nel nostro caso, il modello è stato in grado di apprendere rappresentazioni latenti dei nodi che incorporano informazione non solo sulle feature individuali, ma anche sul contesto strutturale locale, come la presenza di vicini, la connettività e i pattern di interazione. Questo consente di superare i limiti dei modelli basati su caratteristiche tabellari indipendenti, permettendo inferenze più informate e coerenti con l’architettura del grafo. - Considerazione delle relazioni tra link
A differenza di metodi basati su regole locali (es. similarità tra nodi o co-occorrenze), il nostro approccio considera esplicitamente le dipendenze tra archi. Questo è fondamentale quando le relazioni osservate sono collegate a meccanismi sistemici, ad esempio vincoli organizzativi, gerarchie o flussi informativi latenti. Inoltre, la struttura a grafo permette di modellare anche archi indiretti o catene di relazioni che non emergerebbero in una visione riduzionista. - Supporto all’interpretazione
L’integrazione diGNNExplainerrappresenta un passo importante verso la spiegabilità. La possibilità di identificare feature e sotto-grafi rilevanti per una predizione consente di validare i risultati e individuare eventuali bias o pattern inattesi. Questo è particolarmente utile in contesti decisionali, dove la trasparenza del modello può fare la differenza tra un output usabile e uno opaco.
Limiti
Nonostante i vantaggi, l’approccio presenta anche diverse criticità operative e concettuali.
- Complessità computazionale
L’addestramento di GNN e l’uso di metodi di spiegazione come GNNExplainer richiedono risorse computazionali rilevanti. La complessità cresce rapidamente con il numero di nodi, archi e feature. Inoltre, molte operazioni (come la costruzione di batch o la normalizzazione del grafo) richiedono attenzione specifica per garantire efficienza e stabilità numerica. - Scalabilità limitata
Sebbene il modello sia adatto per grafi di medie dimensioni, il suo utilizzo diretto su reti molto grandi (es. grafi di siti nazionali o internazionali) può essere proibitivo. Sono necessarie strategie di compressione, campionamento o partizionamento per renderlo applicabile in scenari reali su larga scala. Tuttavia, queste tecniche possono introdurre distorsioni o perdita di informazione strutturale. - Rischio di overfitting concettuale (dataset sintetico)
L’uso di un dataset simulato presenta il vantaggio del controllo e della validazione interna, ma limita la generalizzabilità. Il modello può imparare pattern specifici del processo di generazione anziché dinamiche reali. Questo introduce il rischio di overfitting concettuale, ovvero l’adattamento eccessivo a una struttura “ideale” che potrebbe non riflettere la complessità dei dati osservati sul campo. È quindi cruciale validare il modello anche su dataset empirici o semi-sintetici che riproducano vincoli e rumore realistico.
Conclusioni e prospettive
Questo studio ha dimostrato la fattibilità e l’efficacia dell’uso delle Graph Neural Networks (GNN) per la predizione di link strategici mancanti in una rete complessa. La pipeline sviluppata ha integrato:
- la generazione di un dataset sintetico con caratteristiche simili a quelle delle reti organizzative reali;
- l’addestramento supervisionato di un modello GCN-based;
- la valutazione delle prestazioni predittive;
- e l’uso del modulo
GNNExplainerper analizzare l’importanza delle feature e delle connessioni.
I risultati ottenuti mostrano che un modello basato su GNN può raggiungere un’elevata accuratezza (≈85%) nel classificare correttamente archi mancanti, distinguendo quelli strategici da quelli rumorosi. Inoltre, l’utilizzo di metodi di interpretazione ha permesso di identificare sotto-grafi e attributi locali rilevanti per le decisioni del modello, aumentando la trasparenza del processo predittivo.


Commenti dalla community