
L'avvento degli LLM (Large Language Models) ha permesso al termine "AI" di farsi spazio nel vocabolario ormai giornaliero della maggior parte degli internauti.
Sistemi come ChatGPT vengono interrogati milioni di volte al giorno per rispondere ai quesiti degli utenti, che stanno si stanno gradualmente chiedendo se il paradigma dei motori di ricerca non sia effettivamente una cosa del passato.
Il prompt engineering è un termine che è associato agli LLM ed è anch'esso molto utilizzato oggi dai fruitori di tali sistemi. Consiste nello sviluppare e ottimizzare i prompt (cioè le domande che vengono poste al modello da parte dell'umano) al fine di ottenere risposte più precise da parte dei modelli linguistici.
Mentre i ricercatori utilizzano il prompt engineering per migliorare la capacità dei LLM su un'ampia gamma di compiti comuni e complessi, gli sviluppatori lo utilizzano per progettare tecniche di prompt robuste ed efficaci che si interfacciano con LLM e altri strumenti.
Questo articolo ha l'obiettivo di introdurti a delle tecniche emergenti di prompt engineering che puoi implementare già da subito nel tuo progetto. Infatti, il prompt engineering non è solamente una banale ottimizzazione testuale delle domande da porre al modello, ma una serie di logiche che in alcuni casi si interfacciano proprio al funzionamento interno degli LLM.
- Come progettare un prompt, andando a comprendere requisiti e anatomia degli elementi che lo compongono
- Alcune delle tecniche più efficaci di prompt engineering
- Casi d'uso ed esempi
Iniziamo subito!
Basi del prompting
Iniziamo dai concetti semplici. È possibile ottenere molto da un modello come ChatGPT chiedendo domande semplici, come le si porrebbero ad un essere umano...ma l'esempio che qui in basso mostra come il modello non si comporti come ci si aspetta al prompt Sopra la panca
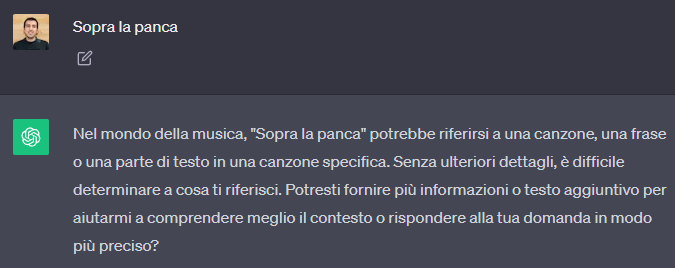
Basta aggiungere un incipit e il modello comprende e risponde correttamente
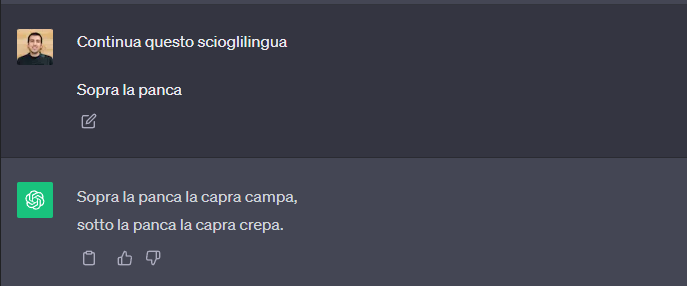
Questo è un esempio molto basilare di prompt engineering, poiché abbiamo ottimizzato la richiesta testuale per ottenere una risposta in linea con le nostre aspettative.
Un prompt non è sempre una domanda - infatti nel caso appena visto si tratta di una istruzione. In una tecnica che vedremo dopo chiamata zero-shot prompting, l'utente può differenziare tra i due tipi di formati e fornire al modello una scaletta da seguire (o meglio, riempire).
R:
Qui formattiamo la domanda con il token di apertura D: e forniamo un template per la risposta che il modello andrà semplicemente a continuare. Questa tecnica funziona anche con altri tipi di richieste, non solo coppie domande-risposta.
Fornendo più esempi stiamo applicando una tecnica chiamata few-shot prompting
Sorriso | Salute
Tosse | Malattia
Sport | Salute
Divertirsi | ?

Vediamo come ChatGPT stesso menzioni la parola correlazione. È di fatto proprio questo il tipo di ragionamento che cerchiamo di stimolare andando a usare il few-shot prompting.
Questi esempi mostrano come delle semplici domande o istruzioni possano essere difficili da interpretare da parte del LLM e che esistono delle tecniche, anche semplici, che permettono al modello di rimuovere ambiguità e fornire delle risposte più adeguate.
Progettazione del prompt
Come praticamente tutto nella data science e nel machine learning, anche il prompt engineering è di fatto una attività iterativa.
Significa che bisogna sperimentare per ottenere il risultato atteso.
Scomporremo la fase di progettazione del prompt in vari requisiti che ti aiuteranno sia a comprendere come ragiona un LLM che a controllare il comportamento del modello.

Requisito # 1: Comprendere l'anatomia del prompt
Uno dei primi passi per ottenere risultati più velocemente è comprendere gli elementi che compongono un buon prompt e che linguaggio usare per massimizzare i risultati.
Analizzando la struttura di un prompt, è possibile estrarre diversi elementi concettuali che si ripetono: entry point, istruzione, contesto, input dell'utente, indicatore di output.
Contesto
Porzione iniziale del prompt. Indica al modello uno scenario rappresentativo che deve assumere per meglio interpretare l'istruzione.
Sei un esperto di negoziazione e sei disponibile a dare consigli a chi te lo chiede. Il tuo obiettivo è quello di aiutarmi a convincere il mio capo a implementare lo smart working nel luogo di lavoro. # <- CONTESTO
...Istruzione
Il secondo step per scrivere un buon prompt è comunicare al LLM quello che deve fare. Usare parole come scrivi, classifica, rimuovi, modifica, riassumi permetterà al modello di performare meglio sul compito.
Sei un esperto di negoziazione e sei disponibile a dare consigli a chi te lo chiede. Il tuo obiettivo è quello di aiutarmi a convincere il mio capo a implementare lo smart working nel luogo di lavoro. # <- CONTESTO
Data questa conversazione, dimmi cosa diresti all'interlocutore da negoziatore esperto. # <- ISTRUZIONE
...Input umano
La componente che si presenta il 100% delle volte, ma che da sola ottiene risultati di qualità variabile. Seguita da un contesto e da istruzioni chiare, l'input umano risulta molto più interpretabile da parte del modello.
Sei un esperto di negoziazione e sei disponibile a dare consigli a chi te lo chiede. Il tuo obiettivo è quello di aiutarmi a convincere il mio capo a implementare lo smart working nel luogo di lavoro. # <- CONTESTO
Data questa conversazione, dimmi cosa diresti all'interlocutore da negoziatore esperto. # <- ISTRUZIONE
Conversazione: # <- INPUT UMANO
...
Indicatore di output
Indicare quando il modello deve restituire un output faciliterà il suo compito durante l'inferenza. È possibile specificare il tipo o il formato della risposta per migliorare la qualità della risposta.
Sei un esperto di negoziazione e sei disponibile a dare consigli a chi te lo chiede. Il tuo obiettivo è quello di aiutarmi a convincere il mio capo a implementare lo smart working nel luogo di lavoro. # <- CONTESTO
Data questa conversazione, dimmi cosa diresti all'interlocutore da negoziatore esperto. # <- ISTRUZIONE
Conversazione: # <- INPUT UMANO
...
---
Nuova conversazione: # <- INDICATORE DI OUTPUTMettendo insieme tutti i pezzi, avremmo un prompt così composto:
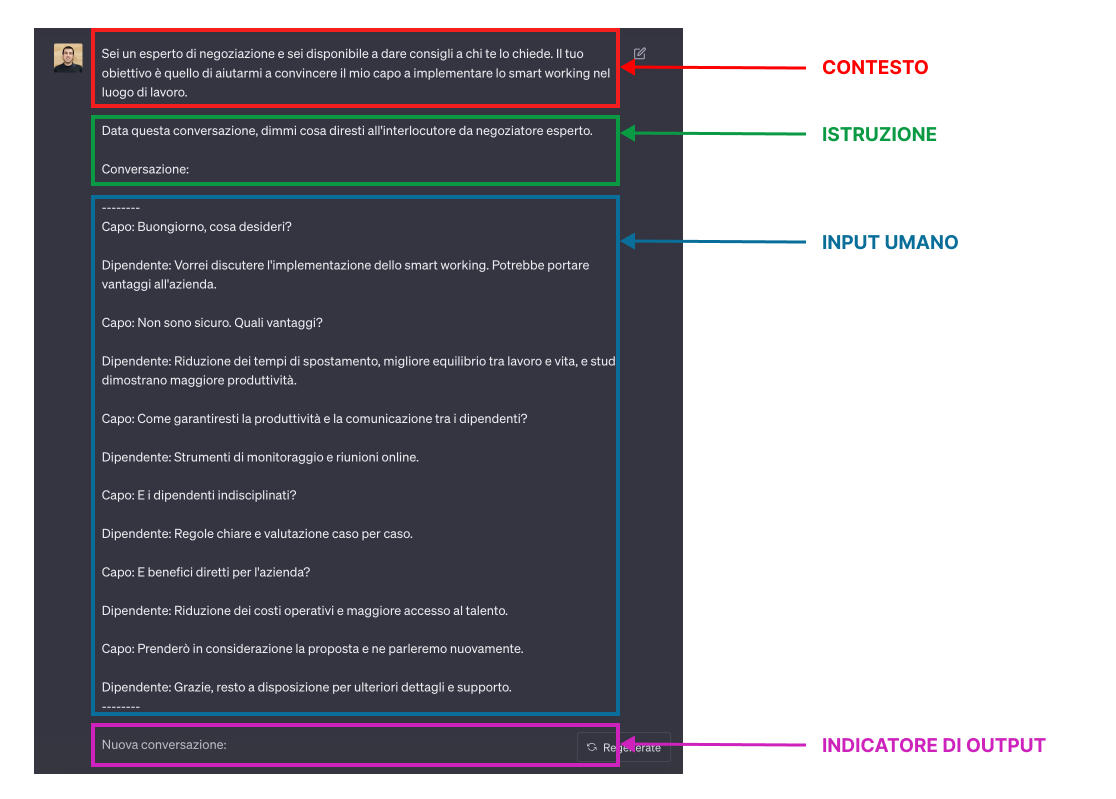
Non tutti questi elementi sono necessari per avere una risposta da parte del modello, ma averli aiuta.
Requisito # 2: Massimizzare la chiarezza minimizzando la lunghezza del testo
Il nostro prompt potrà anche avere tutti gli elementi menzionati, ma se non è chiaro allora il modello interpellato avrà difficoltà a rispondere in maniera soddisfacente.
Occorre essere molto specifici riguardo alle istruzioni e al compito che desideri che il modello esegua. Più il prompt è descrittivo e dettagliato, migliori saranno i risultati.
Aggiungere dettagli ai fini della chiarezza porta con sé un costo: un testo più lungo.
Testi più lunghi sono vincolati dalla context window - il modello troncherà la risposta e non potrà più processare la richiesta.
I dettagli quindi devono essere pertinenti e contribuire al compito da svolgere. Fornire esempi nel prompt è molto efficace per ottenere l'output desiderato in formati specifici.
Requisito # 3: Dire al modello cosa NON fare
È altrettanto utile dire al modello cosa non deve restituire all'utente. Molto spesso, gli LLM tendono ad aggiunere parole in più che rendono il testo più conversazionale. Se non vogliamo questo, dobbiamo espressamente dire al modello cosa non deve fare.
Sei un esperto di negoziazione e sei disponibile a dare consigli a chi te lo chiede. Il tuo obiettivo è quello di aiutarmi a convincere il mio capo a implementare lo smart working nel luogo di lavoro.
Data questa conversazione, dimmi cosa diresti all'interlocutore da negoziatore esperto.
Quando rispondi, non fare mai riferimento agli altri dipendenti. <- VINCOLO ALLA RISPOSTA
Conversazione:
...
---
Nuova conversazione: Tecniche di Prompt Engineering
Abbiamo già visto un esempio di zero-shot e few-shot prompting. Per riassumere, si fornisce al modello una istruzione diretta e si chiede ad esempio di classificare l'input.
Classifica il sentiment della seguente affermazione.
Affermazione: mi sento molto bene oggi!
Sentiment:In questo caso stiamo sfruttando le capacità del modello per l'inferenza, poiché non spieghiamo cosa sia la parola "sentiment". Ha già questa nozione, e noi sfruttiamo questa situazione.
Nel caso in cui lo zero-shot prompting non da buoni risultati, provare con il few-shot tipicamente porta buoni risultati.
Ora passiamo ad una rassegna delle tecniche più efficaci attualmente usate dai prompt engineer per sfruttare al massimo le potenzialità degli LLM.
Tecnica # 1: Chain-of-Thought
Tradotto significa catena di pensieri ed è una tecnica di prompting che aiutare il modello nel ragionamento fornendo degli step intermedi che lo aiutano a comprendere meglio il task.
Gli autori di questa tecnica (Wei et al. 2022), mettono a disposizione questa immagine che aiuta a capire meglio come funziona il CoT.
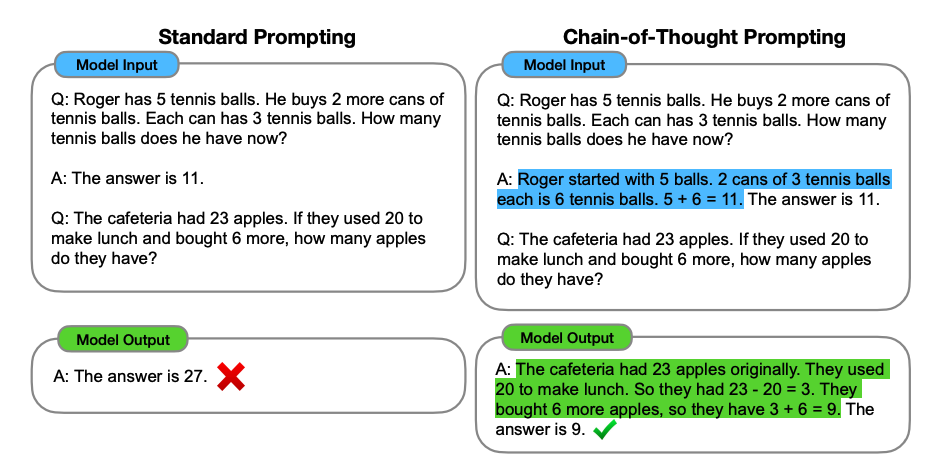
Dall'immagine è possibile vedere come il prompt "standard" di sinistra sia solo una lista di domande e risposte. Il CoT si distingue perché permette al modello di estrarre un pattern di ragionamento dalla risposta alla domanda, che fornisce l'utente. Comprendendo la sequenza di step, il modello è in grado di replicarlo e applicarlo anche ad un problema nuovo.
Il CoT è spesso accompagnato dal few-shot prompting, perché espone al LLM più pattern di ragionamento.
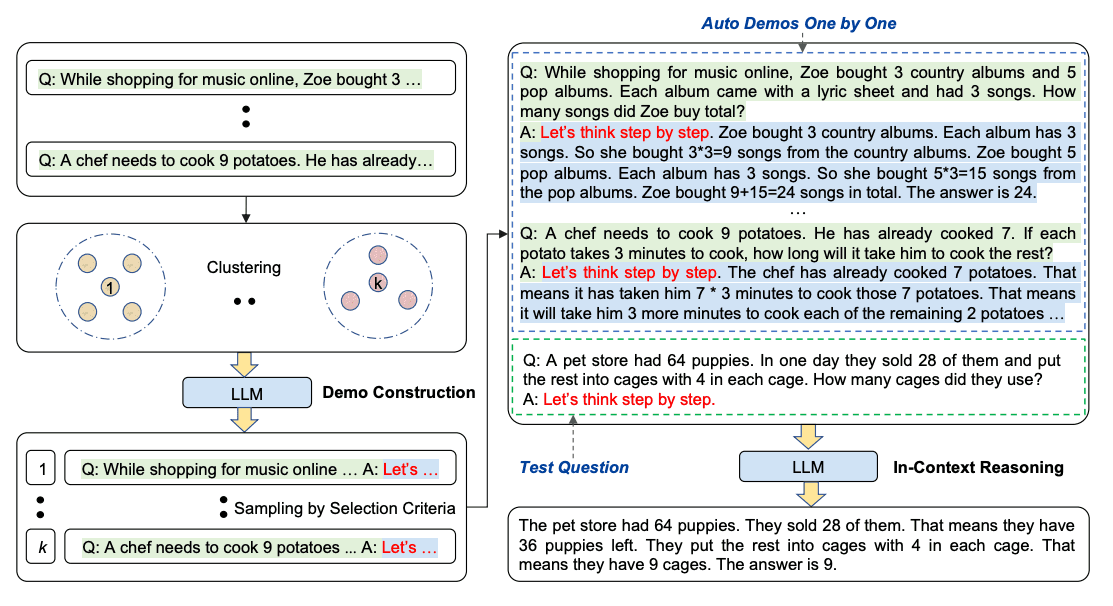
Automatic Chain-of-Thought (AutoCoT)
Questa è una variante del CoT, che semplifica la creazione di prompt basati su questa tecnica.
Aggiungere una frase come "Ragioniamo passo dopo passo" permette al modello di generare step intermedi di ragionamento che portano ad un risultato più accurato.
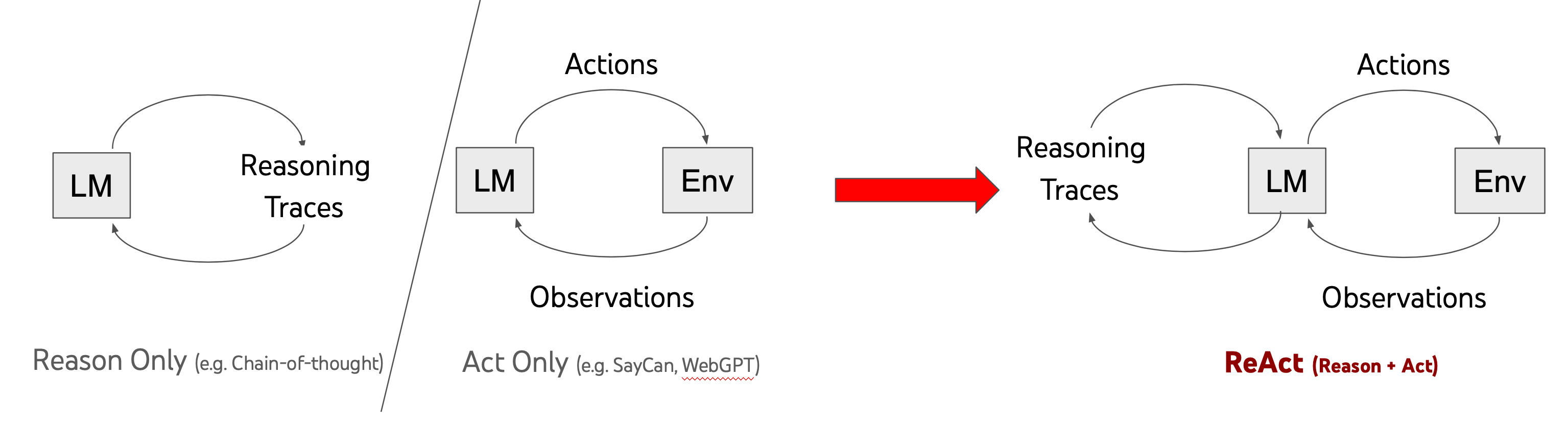
Tecnica # 2: ReAct
ReAct sta per Reason + Act ed è una tecnica pubblicata la prima volta da Yao et al. nel 2022 e si basa sul Chain of Thought.
La tecnica consiste nel fornire al modello tracce di ragionamento (reasoning traces) e azioni da compiere specifiche per il task (task-specific actions).
Le reasoning traces aiutano il modello a indurre, tracciare e aggiornare le strategie di esecuzione mentre le task-specifc action consentono al modello di interfacciarsi con l'utente o fonti esterne per raccogliere informazioni aggiuntive.
Esatto. ReAct presuppone che il nostro modello possa interagire con il mondo esterno.
Ecco un esempio di come un LLM reagisce alla ricerca nel framework ReAct.
Una libreria come LangChain permette all'utente di usare tale framework in maniera semplice.
Prendendo l'esempio dalla pagina linkata, vediamo come sia possibile specificare dei tool per permettere al modello di fare azioni su internet (come navigare una pagina web).
from langchain.llms import OpenAI
from langchain.docstore import Wikipedia
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.agents.react.base import DocstoreExplorer
docstore = DocstoreExplorer(Wikipedia()) # sistema per salvare la ricerca
# definizione degli strumenti
tools = [
Tool(
name="Search",
func=docstore.search,
description="useful for when you need to ask with search",
),
Tool(
name="Lookup",
func=docstore.lookup,
description="useful for when you need to ask with lookup",
),
]
# creazione del modello
llm = OpenAI(temperature=0, model_name="text-davinci-002")
react = initialize_agent(tools, llm, agent=AgentType.REACT_DOCSTORE, verbose=True)
question = "Author David Chanoff has collaborated with a U.S. Navy admiral who served as the ambassador to the United Kingdom under which President?"
react.run(question)La "difficoltà" nell'usare ReAct è che bisogna saper programmare in Python e conoscere le basi della libreria LangChain.
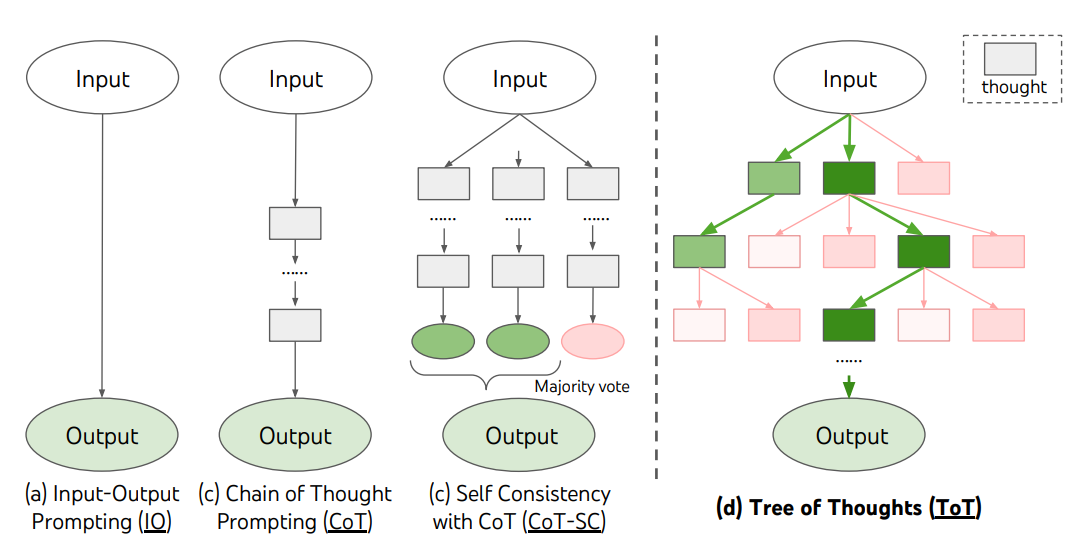
Tecnica # 3: Tree of Thoughts (ToT)
Si basa anch'essa sul Chain of Thoughts, solo che è una tecnica incoraggia l'esplorazione dei pensieri nella CoT che fungono da passaggi intermedi per la risoluzione generale dei problemi da parte degli LLM.
ToT mantiene un albero di ragionamenti fatti dal LLM, dove i pensieri rappresentano sequenze linguistiche coerenti che servono come passaggi intermedi verso la risoluzione di un problema. Questo approccio consente al LLM non solo di dichiarare, ma di valutare come questi step intermedi aiutano a risolvere il problema.
La capacità del LM di generare e valutare gli step intermedi viene combinata con algoritmi di ricerca (ad esempio, ricerca in ampiezza o in profondità) per consentire l'esplorazione sistematica dei pensieri in tutte le direzioni dell'albero.
Per costruire un prompt per un LLM usando il ToT faremo riferimento al repository git di Dave Hulbert:
Ipotizziamo un prompt del genere, che chiede una ricostruzione precisa degli eventi per capire dove si trova la palla,

Vediamo come ChatGPT abbia sbagliato valutazione. Infatti, la palla si trova in camera da letto.
Applichiamo ora il ToT al prompt precedente aggiungendo questo blocco:
Immagina che tre diversi esperti stiano rispondendo a questa domanda.
Tutti gli esperti scrivono 1 passaggio del loro pensiero, e poi lo condividono con il gruppo. In seguito, tutti gli esperti passeranno al passaggio successivo, ecc.
Se qualche esperto si rende conto di aver sbagliato in qualsiasi momento, se ne va.
La domanda è: 
ChatGPT, che è basato in questo caso sulla versione free di GPT-3.5, risponde correttamente. Notevole!
Il ToT performa, ovviamente, meglio con GPT-4 che con GPT-3.5 ma usando un po' di astuzia e seguendo il framework, allora anche quest'ultimo è in grado di dare informazioni corretta a domande complesse.
Tecnica # 4: Optimization by PROmpting (OPRO)
OPRO è una tecnica introdotta da Google DeepMind che mira ad ottimizzare la risposta degli LLM. Fondamentalmente, OPRO sfrutta gli LLM per valutare iterativamente gli output e ottimizzare i prompt.
OPRO ottimizza in modo iterativo i prompt per generare continuamente nuove soluzioni, perfezionando i propri output in base alla descrizione del problema e alle soluzioni scoperte in precedenza.
"OPRO consente al LLM di generare gradualmente nuovi prompt che migliorano la precisione dell'attività durante tutto il processo di ottimizzazione, in cui i prompt iniziali sono associati ad una bassa precisione dell'attività", scrivono gli autori del paper.

Il framework è progettato per integrare 2 LLM (un ottimizzatore e un valutatore) per migliorare in modo iterativo l'output del meta-prompt.
Supponiamo di avere questo prompt per estrarre delle keyword rilevanti da un testo:
Dato del contenuto testuale, estrai le keyword più rilevanti che informano dell'argomento trattato.
Esempio 1:
Nell'ambito della data science e del machine learning un dataset multidimensionale è una raccolta di dati organizzata in modo da includere molteplici colonne o attributi, ciascuna delle quali rappresenta una caratteristica del fenomeno che si sta studiando o cercando di predire.
Keyword: data science, machine learning, dataset, caratteristica, fenomeno
Esempio 2:
In base al numero di componenti che scegliamo, l'algoritmo PCA permette la riduzione del numero di variabili nel dataset originale andando a preservare quelle che spiegano meglio la varianza totale del dataset stesso, andando a combattere la maledizione della dimensionalità (curse of dimensionality).
Keyword: PCA, variabili, dataset, maledizione della dimensionalità
TESTO:
{{ testo in input }}
Ora questo prompt viene in realtà definito come meta-prompt e viene fornito ad un LLM valutatore per analizzarlo e migliorarlo. Questo modello interpreta la richiesta di comprendere il compito di classificazione, rivedendo gli esempi e la tipologia di dati con cui ha a che fare. L'LLM genera una serie di nuovi suggerimenti che ritiene potrebbero migliorare i risultati della classificazione o estrazione di informazioni.
Dato questo meta-prompt, i suoi obiettivi e esempi, genera una serie di nuovi prompt che potrebbero potenzialmente portare a risultati migliori nell'estrazione delle keyword in base al contenuto presente nei testi. Puntare a suggerimenti chiari, concisi e in grado di guidare il modello in modo efficace.
{{ meta-prompt }}Il modello quindi genererà diversi prompt che verranno poi inseriti nel meta-prompt stesso.
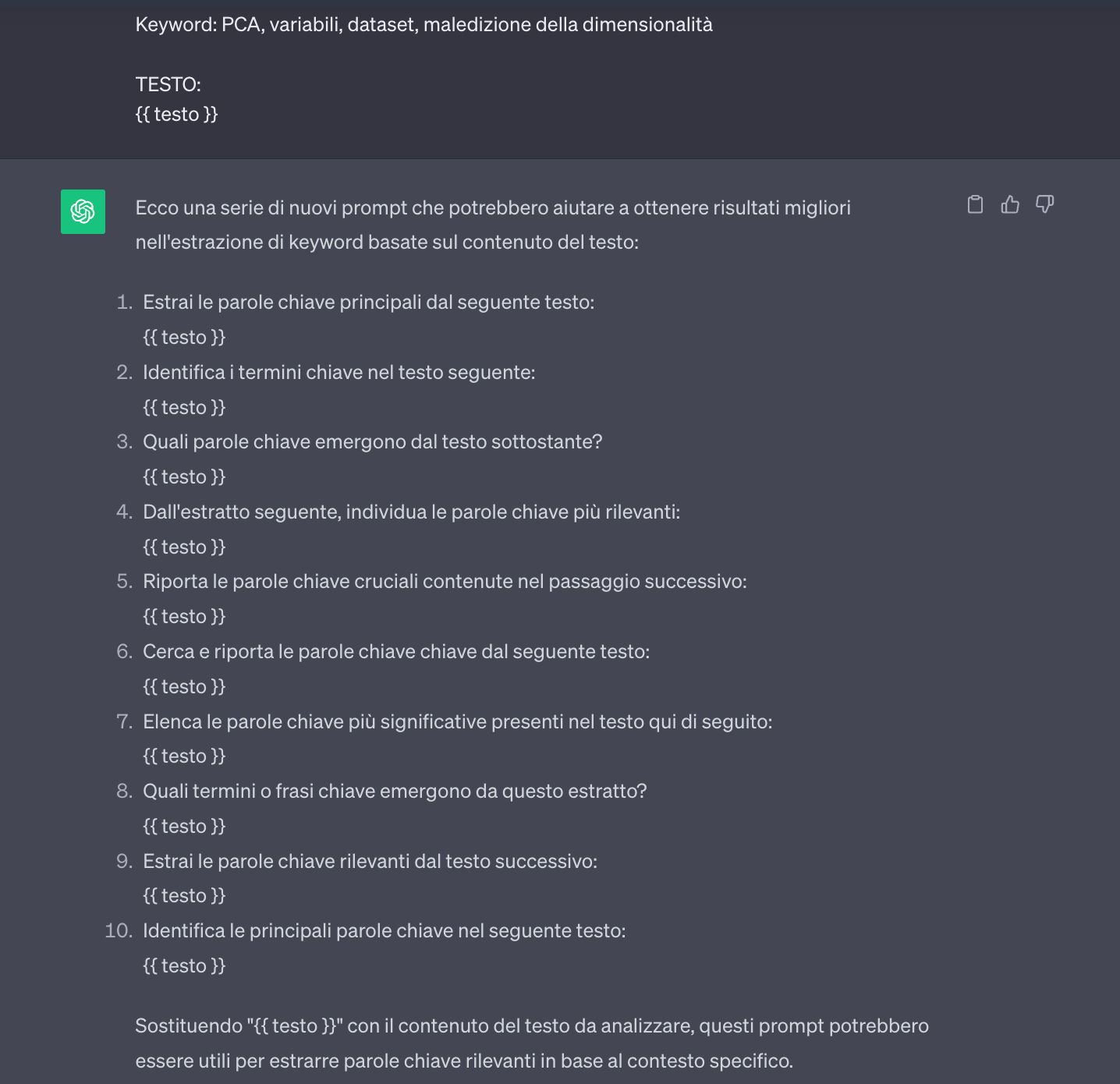
Dopo aver testato questi prompt, i relativi risultati verranno aggiunti al meta-prompt:
Dato del contenuto testuale, estrai le keyword più rilevanti che informano dell'argomento trattato.
Esempio 1:
Nell'ambito della data science e del machine learning un dataset multidimensionale è una raccolta di dati organizzata in modo da includere molteplici colonne o attributi, ciascuna delle quali rappresenta una caratteristica del fenomeno che si sta studiando o cercando di predire.
Keyword: data science, machine learning, dataset, caratteristica, fenomeno
Esempio 2:
In base al numero di componenti che scegliamo, l'algoritmo PCA permette la riduzione del numero di variabili nel dataset originale andando a preservare quelle che spiegano meglio la varianza totale del dataset stesso, andando a combattere la maledizione della dimensionalità (curse of dimensionality).
Keyword: PCA, variabili, dataset, maledizione della dimensionalità
PROMPT GENERATI PRECEDENTEMENTE E RELATIVE PERFORMANCE:
Estrai le parole chiave principali dal seguente testo: 88%
Identifica i termini chiave nel testo seguente: 78%
Quali parole chiave emergono dal testo sottostante? 40%
Dall'estratto seguente, individua le parole chiave più rilevanti: 78%
Riporta le parole chiave cruciali contenute nel passaggio successivo: 80%
Da qui, il processo iterativo continua. Dopo aver valutato i nuovi prompt, viene utilizzato il feedback per perfezionare il meta-prompt e il processo viene ripetuto finché non si è soddisfatti delle prestazioni del prompt.
Di recente questa tecnica è stata parecchio discussa online, sottolineando che gli autori sono arrivati ad inserire una frase del tipo "Take a deep breath and work on this problem step-by-step." (Fai un respiro profondo e lavora su questo problema passo dopo passo). Questa semplice inclusione nel prompt ha migliorato drasticamente la performance degli LLM coinvolti.

La sfida di usare questa tecnica è quella di registrare le varie performance delle risposte ai prompt creati dagli LLM per il modello valutatore. Può valerne sicuramente la pena se pensiamo alle performance che possiamo raggiungere con il prompt finale.
Conclusioni
Hai imparato le basi del prompt engineering e alcune tecniche importanti per aumentare le performance delle risposte degli LLM.
In particolare hai letto di
- basi del prompting, e di come il prompting semplice non porta a risultati eccellenti
- come si progetta un prompt e la sua anatomia
- i requisiti per creare un buon prompt
- alcune delle tecniche più efficaci per massimizzare le performance degli LLM
Questo articolo sarà periodicamente aggiornato per includere le tecniche più valide nello spazio del prompt engineering.
A presto,
Andrea





Commenti dalla community