
Tabella dei Contenuti
Chi ha lavorato in passato con il paradigma NER (named entity recognition, riconoscimento delle entità nominate) che classificare token, sa bene il valore di avere un modello performante per il task su cui è stato addestrato.
Infatti, i modelli NER sono estremamente utili per le attività di data mining e di analisi testuale - sono alla base di ogni attività di intelligence digitale e in una miriade di attività collegate a pipeline di data science più ampie e complesse.
Chi fa NER sa anche quanto è complesso addestrare un tale modello a causa dell'enorme quantità di etichette da specificare durante la fase di training. Librerie come SpaCy e i modelli presenti su Hugging Face basati su transformer hanno aiutato parecchio i data scientist a sviluppare modelli NER in maniera sempre più efficiente, che comunque migliorano il processo fino ad un certo punto.
In questo articolo vedremo insieme il paradigma GLiNER, una nuova tecnica per l'estrazione delle entità che unisce il classico paradigma NER alla potenza degli LLM.
Per la fine di questo articolo saprai cosa è GLiNER e come usarlo in Python per fare classificazione di qualsiasi token, su qualsiasi testo.
- Cosa è GLiNER
- Perché è potenzialmente rivoluzionario
- Come implementarlo in Python
- Limitazioni di GLiNER
GLiNER è stato pubblicato in un paper scientifico, presente al link di seguito 👇
Inoltre, gli autori del paper hanno pubblicato un repository Github pubblico
 urchade
urchadeCosa è GLiNER?
GLiNER è un modello NER in grado di identificare qualsiasi tipo di entità utilizzando un codificatore di trasformatore bidirezionale (simile a BERT). Fornisce un’alternativa pratica ai tradizionali modelli NER, che sono limitati a entità predefinite, e ai Large Language Models (LLM) che, nonostante la loro flessibilità, sono costosi e di grandi dimensioni per scenari con risorse limitate.
GLiNER utilizza un BiLM (Bidirectional Transformer Language Model) e accetta come input prompt di tipo entità e una frase/testo.
Andando brevemente nel tecnico, ogni entità è separata da un token appreso [ENT] e il BiLM genera rappresentazioni vettoriali (embedding) per ciascun token. Gli embedding vengono passati in una rete neurale FeedForward, mentre le rappresentazioni delle parole di input vengono passate in uno strato neurale dedicato ad apprendere le finestre di caratteri che racchiudono il token in questione). Queste finestre vengono chiamate span.
Infine, viene calcolato un punteggio di similarità tra le rappresentazioni delle entità e le rappresentazioni degli span utilizzando il prodotto scalare e l'attivazione del sigmoide.
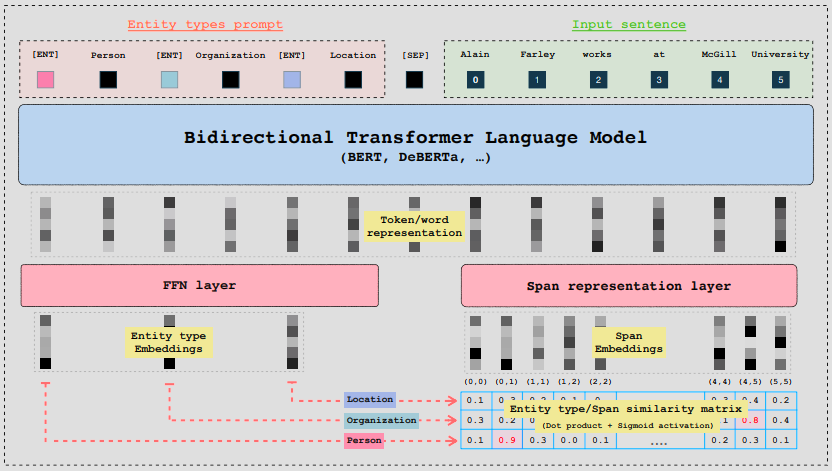
Invece di fare affidamento su modelli autoregressivi di grandi dimensioni (come GPT-3.5 e 4), vengono utilizzati dei modelli linguistici bidirezionali su scala ridotta (i BiLM menzionati), come ad esempio come BERT o deBERTa.
Questo approccio risolve naturalmente i problemi di scalabilità dei modelli autoregressivi e consente l'elaborazione bidirezionale del contesto, che consente una maggiore ricchezza rappresentazioni.
Al momento della pubblicazione, GLiNER supera sia ChatGPT che LLM ottimizzati set di dati NER zero-shot.
Perché GLiNER è potenzialmente rivoluzionario?
Avrai capito che GLiNER è più leggero, scalabile, veloce e preciso di un approccio basato su LLM, incluso ChatGPT.
La cosa che più stupisce è che è possibile ora fare NER a costo ZERO, in maniera veloce ed efficiente. Si è passati quindi dal dover addestrare un modello NER da zero oppure a spendere soldi per una soluzione basata su LLM, ad un modello che unisce entrambe le soluzioni e lo fa nella maniera più efficiente possibile, sia dal punto di vista tecnico che economico.
Le performance di GLiNER sono esposte nell'immagine sui sotto:
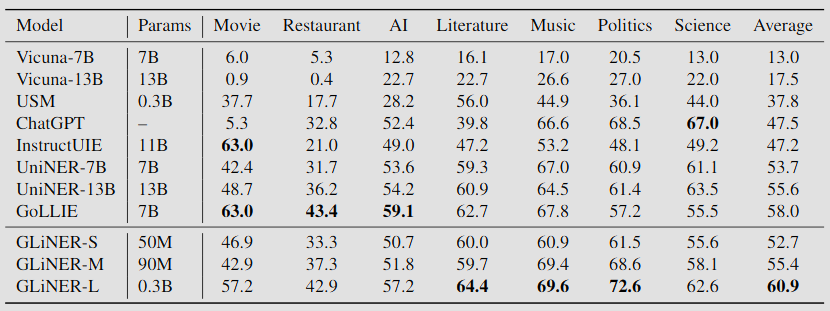
Viene superato solo in alcuni domini specifici da altri modelli, ma il gap numerico non è ampio.
Di seguito un benchmark solo contro ChatGPT su 20 dataset pubblici di NER su un task di zero-shot token classification:
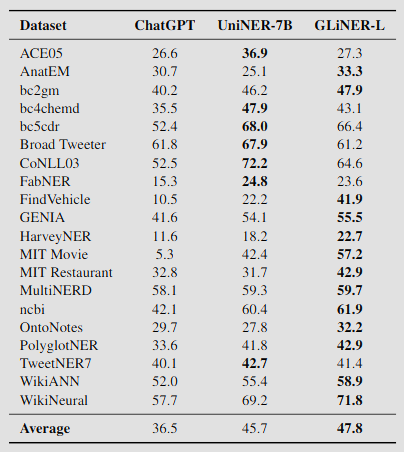
GLiNER è disponibile in varie dimensioni, ma già la versione small è in grado di superare le performance di ChatGPT. La versione small ha una dimensione pari a 50 milioni di parametri, che corrispondono a circa 600MB.
Il modello risulta quindi impressionante dal punto di vista dei risultati, e ha il potenziale di diventare la soluzione principale ai problemi NER più comuni.

Come implementare GLiNER in Python
Gli autori del progetto hanno messo a disposizione un comodo pacchetto installabile attraverso pip.
pip install gliner
A differenza di un altro modello NER, non dobbiamo addestrare oppure fare fine-tune di nulla. Occore solo specificare in una lista Python che entità vogliamo estrarre dal nostro testo.
Quindi gli occorrenti sono due:
- Le entità (leggi etichette) che vogliamo estrarre
- Il testo dalla quale vogliamo estrarre le entità
Usando l'esempio nel repository Git del progetto, è possibile vedere quanto è semplice usare GLiNER in Python.
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = """
Cristiano Ronaldo dos Santos Aveiro (Portuguese pronunciation: [kɾiʃˈtjɐnu ʁɔˈnaldu]; born 5 February 1985) is a Portuguese professional footballer who plays as a forward for and captains both Saudi Pro League club Al Nassr and the Portugal national team. Widely regarded as one of the greatest players of all time, Ronaldo has won five Ballon d'Or awards,[note 3] a record three UEFA Men's Player of the Year Awards, and four European Golden Shoes, the most by a European player. He has won 33 trophies in his career, including seven league titles, five UEFA Champions Leagues, the UEFA European Championship and the UEFA Nations League. Ronaldo holds the records for most appearances (183), goals (140) and assists (42) in the Champions League, goals in the European Championship (14), international goals (128) and international appearances (205). He is one of the few players to have made over 1,200 professional career appearances, the most by an outfield player, and has scored over 850 official senior career goals for club and country, making him the top goalscorer of all time.
"""
labels = ["person", "award", "date", "competitions", "teams"]
entities = model.predict_entities(text, labels, threshold=0.5)
for entity in entities:
print(entity["text"], "=>", entity["label"])
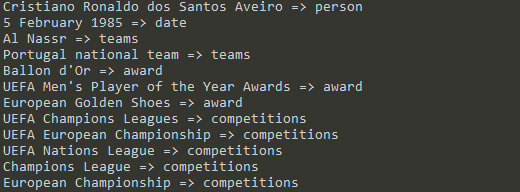
È possibile cambiare la lista a piacimento, e avviare il modello nuovamente per avere altre entità.
Modifichiamo le label da
labels = ["person", "award", "date", "competitions", "teams"]
a queste
labels = ["event", "location"]
Questo è l'output

Limitazioni di GLiNER
Nel paper gli autori sottolineano diversi aspetti su cui GLiNER può migliorare
- il modello soffre da un addestramento fatto su classi sbilanciate: alcune classi sono più frequenti di altre e vorrebbero migliorare l'identificazione e la gestione di queste classi con una funzione di perdita dedicata
- bisogna migliorare le capacità multilinguistiche: occore un training su più lingue (al momento l'italiano è supportato male)
- si basa su una threshold di similarità: nel futuro gli autori vorrebbero renderla dinamica così da catturare quante più entità possibili senza stravolgere i risultati
Conclusioni
GLiNER è assolutamente da esplorare e usare per task di data mining e analitica dati.
La mia opinione è che sarà un progetto che prenderà sempre più piede nel settore, con possibili fork che faranno nascere novità ancora più grandi.
Magari il paradigma RAG può essere migliorato grazie alla identificazione veloce ed efficiente delle entità?





Commenti dalla community