
Se sei qui è perché vuoi saperne di più sul machine learning e scoprire cosa si intende per con il termine "algoritmo" o "modello".
A differenza dell'articolo già presente su questo blog intitolato Cos'è il Machine Learning: come spiego il concetto ad un neofita, qui mi focalizzerò a darti una introduzione ai principali algoritmi che compongono lo spazio del machine learning tradizionale e non.
Questi algoritmi sono il cuore pulsante di molte applicazioni moderne - di fatto, permettono ai computer di apprendere dai dati e prendere decisioni intelligenti senza essere esplicitamente programmati.
- a categorizzare gli algoritmi del machine learning
- quali sono i principali algoritmi e perché dovresti conoscerli
- come scegliere uno o più algoritmi per il tuo caso d'uso
- risorse per iniziare a scrivere codice Python per implementare l'algoritmo scelto
Questo articolo, insieme a quello linkato sopra, rappresenta un buon punto di ingresso nel mondo della data science e machine learning.
Ti condivido anche la pagina Inizia Qui che contiene una lista curata di link di blog da seguire in ordine per iniziare il tuo percorso anche programmatico.
 Andrea D’Agostino
Andrea D’Agostino
Iniziamo!
Categorizzazione degli Algoritmi di Machine Learning
Prima di addentrarci nei dettagli degli algoritmi e modelli, è importante comprendere la tassonomia di tali concetti.
I software basati sul machine learning ossono essere suddivisi in diverse categorie, quali:
Apprendimento Supervisionato
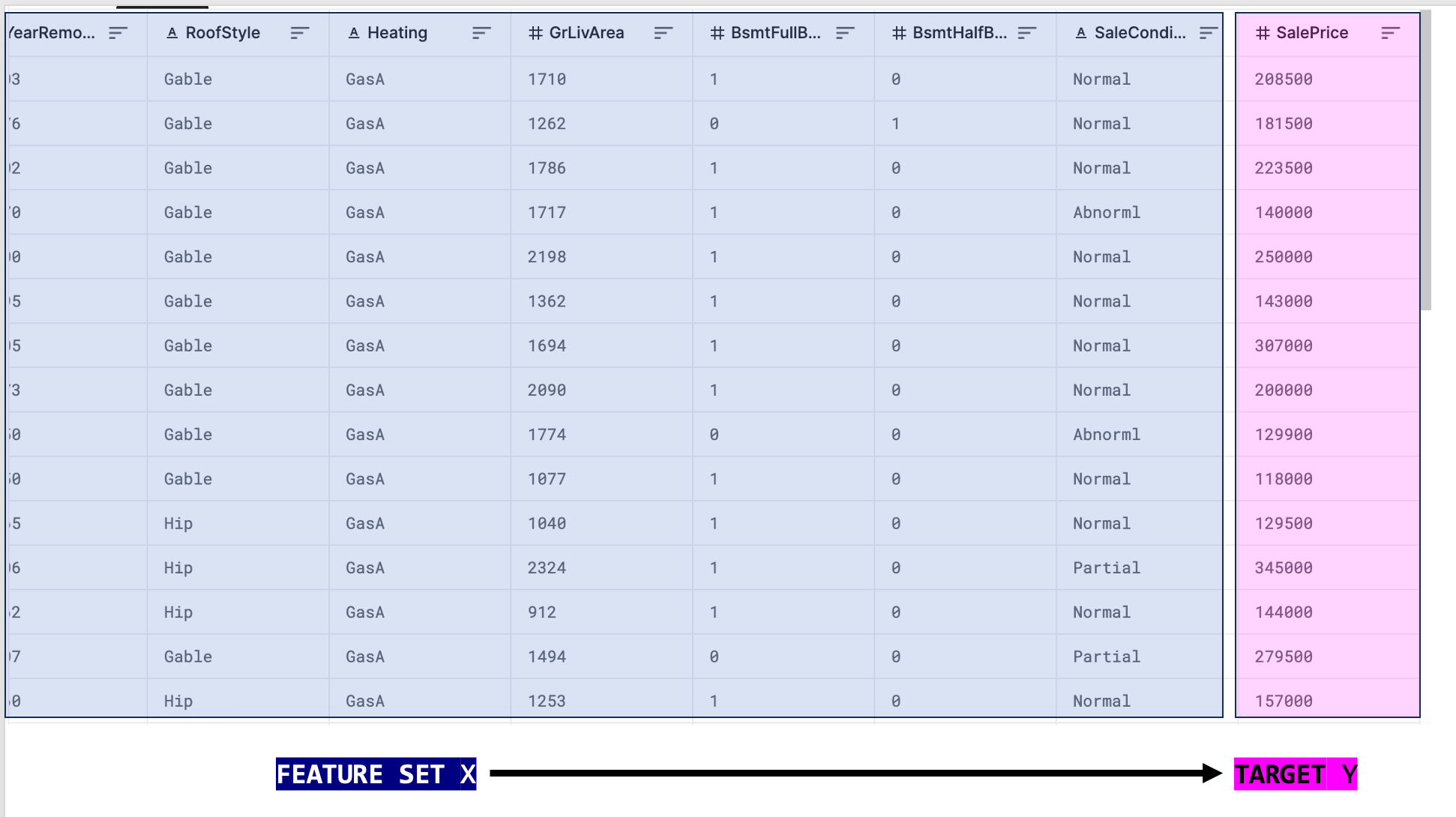
In questo tipo di apprendimento, il modello viene addestrato su un set di dati in cui sono presenti sia le variabili di input che quelle di output desiderate. L'obiettivo è imparare una mappatura tra input e output in modo che il modello possa fare previsioni accurate su nuovi dati.
Apprendimento Non Supervisionato
Qui, il modello viene addestrato su dati senza etichette. L'obiettivo principale è scoprire pattern o strutture nascoste nei dati, come clustering o riduzione della dimensionalità.
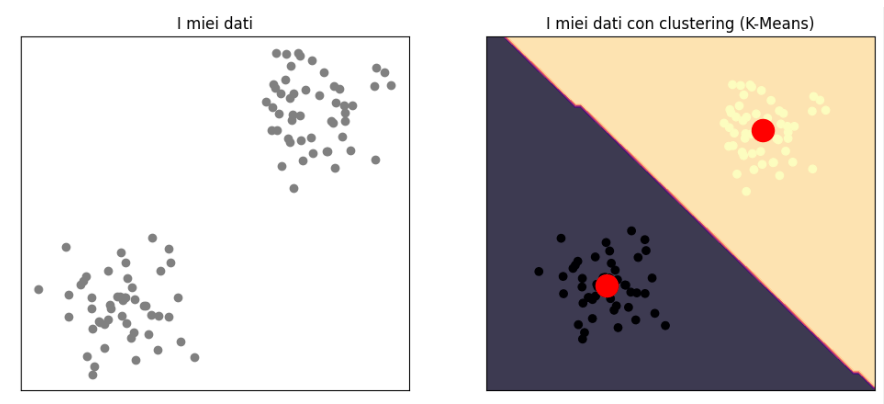
Nell'immagine in alto vediamo come un algoritmo di clustering sia in grado di esprimere due gruppi: quello in alto e quello in basso. Questo avviene senza la presenza di etichette di addestramento.
Apprendimento per Rinforzo
Questo tipo di apprendimento è simile all'apprendimento supervisionato, ma il modello apprende attraverso l'interazione con un ambiente in cui prende decisioni e riceve feedback in base alle sue azioni. È ampiamente utilizzato in applicazioni di intelligenza artificiale come i giochi.
Esistono anche altre categorie (come l'approccio evolutivo o genetico) ma non verranno trattati in questo articolo.
Ecco un breve video in inglese di Udacity che spiega il paradigma del reinforcement learning
Algoritmo vs Modello di Machine Learning: qual è la differenza?
Un altro ingrediente fondamentale per la tua comprensione dell'articolo è differenziare adeguatamente cosa si intende, nella data science e ML, per algoritmo e modello.
Definizione di algoritmo
Un algoritmo è una sequenza di istruzioni logicamente organizzate e definite che descrive un processo o una procedura computazionale.
Nient'altro. Un algoritmo non è altro che una ricetta che un PC segue per raggiungere un risultato.
Uno script Python è un algoritmo, un albero decisionale è un algoritmo, una ricerca binaria è un algoritmo.

Definizione di modello
Un modello è un software che viene inserito nell'algoritmo e che ci serve per trovare la soluzione al nostro problema. Poiché spesso non conosciamo la vera soluzione, queste vengono chiamate predizioni.
Quindi, un modello di machine learning è spesso contenuto o implementato all'interno di un algoritmo. L'insieme viene chiamato conveniente mente algoritmo.
Come menziono nel mio articolo introduttivo al machine learning (link sopra):
Un algoritmo non è altro che una serie di istruzioni seguite da un computer. [...]
Un modello invece è un software che viene inserito nell'algoritmo e che ci serve per trovare la soluzione al nostro problema.
Ora hai le basi per comprendere quello che segue: i principali algoritmi di Machine Learning tradizionale.
Principali Algoritmi di Machine Learning
Copriremo, per comodità e perché fondamentalmente accessibili a tutti, gli algoritmi principali di Scikit-Learn. In particolare copriremo gli algoritmi di regressione, classificazione e clustering.
Per ultimo, menzionerò anche XGBoost, LightGBM e CatBoost - alcuni dei modelli di machine learning tradizionali più famosi e utilizzati grazie alle loro performance su dati tabellari. Questi non fanno parte di Scikit-Learn.
Algoritmi di Regressione
Partiremo con gli algoritmi di regressione - cioè quelli che creano previsioni numeriche continue sui dati in input. Ad esempio, un algoritmo di regressione può predire il prezzo di un oggetto oppure quanti giorni occorrono ad un progetto per raggiungere un certo obiettivo.
Regressione Lineare
La regressione lineare è l'algoritmo introduttivo al machine learning. L'algoritmo classico si chiama OLS (Ordinary Least Squares), che adatta un modello lineare con coefficienti \( w = (w_{1}, ..., w_{n}) \) per ridurre al minimo la somma residua dei quadrati tra gli i dati osservati e le previsioni fatte dall'approssimazione lineare.
Quando si parla di algoritmo lineare significa che esiste una equazione che descrive la relazione tra le variabili dipendente y e indipendente X.
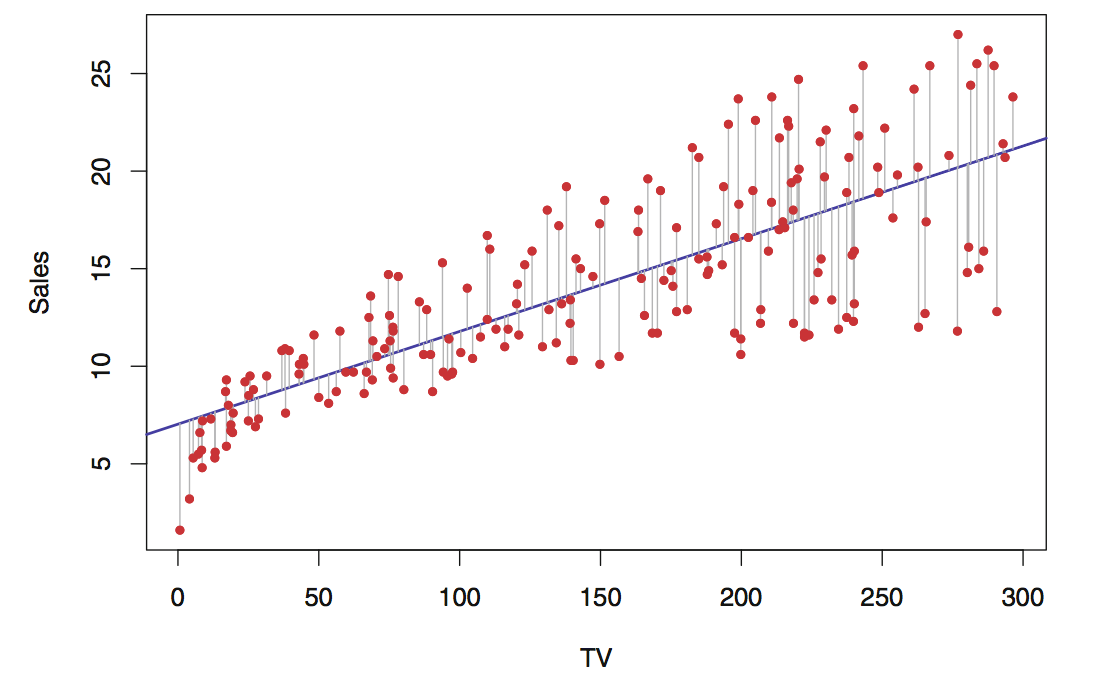
La linea blu rappresenta la previsione del modello, in nero invece i punti del dataset osservati. Il modello vuole ridurre la distanza tra i punti neri e i punti in blu. Quando i punti neri sono sulla linea blu allora l'errore è 0 e l'osservazione reale è uguale alla predizione del modello.
L'espressione matematica è espressa con una retta \( y = mx + b \) la quale vuole sempre minimizzare la distanza tra i punti e la retta stessa.
Ci sono molti tipi di algoritmo di regressione e non sarà necessario documentarli tutti in questo articolo. Di fatto, ognuno di questi algoritmi ha qualcosa che l'altro non ha e che lo rende adatto in base al contesto.
Alcuni dei più comuni algoritmi lineari per la regressione sono:
- Regressione Lasso, che applica una regolarizzazione L1
- Regressione Ridge, che applica una regolarizzazione L2
- Elastic Net, che applica entrambe le regolarizzazioni
- Stocastic Gradient Descent (SGD), che applica l'algoritmo della discesa del gradiente
Se vuoi saperne di più sulla regolarizzazione, ho scritto un articolo per te qui
Andrea D’Agostino
Regressioni non lineari
Esistono algoritmi che non vogliono adattare una linea ai dati, bensì approssimare le osservazioni con logiche non lineari.
Alcuni di questi algoritmi sono gli alberi decisionali e le reti neurali. Questi algoritmi usano logiche uniche per esprimere la relazione tra caratteristiche e target.
Vediamo in basso l'immagine di come un albero decisionale vada a descrivere tale relazione, che è molto diversa da una linea come nell'immagine in alto.
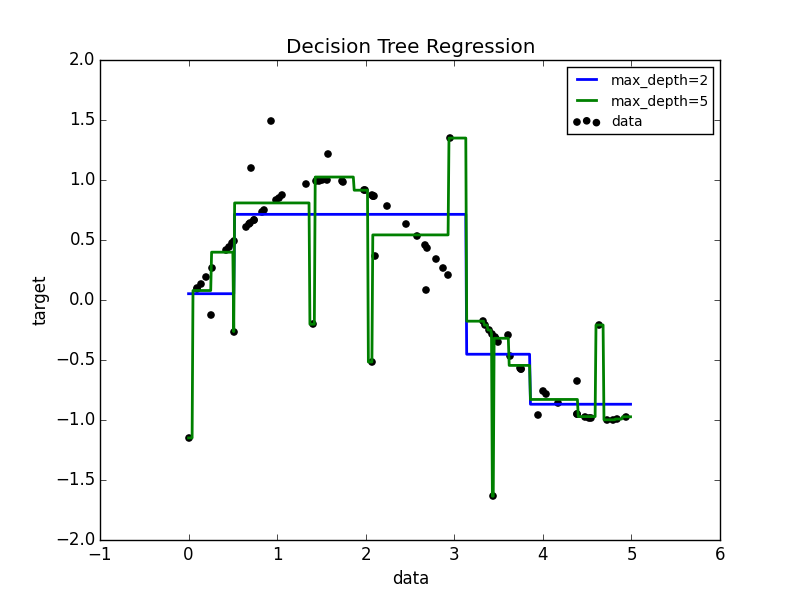
Mentre un modello lineare creerebbe una relazione del genere
\[ Prezzo\ della\ frutta = m_{1}Freschezza + \newline m_{2}Freschezza + b_{0} \]
Un albero farebbe un ragionamento basato su nodi: Nodi: Maturi - Sì o no | Fresco - Sì o No | Taglia - <5, >5 ma <10 e >10 e così via.
Una rete neurale invece ha proprietà molto particolari che si basano fondamentalmente sulle funzioni di attivazione. Sostanzialmente, una rete neurale è lineare nelle variabili ma può restituire mappature non lineari proprio grazie alle funzioni di attivazione, come ad esempio ReLU.
Se vuoi leggere di più sulle reti neurali e su come funzionano, ti linko un articoo interessante
Andrea D’Agostino
Alcuni dei modelli di regressione non lineari più comuni sono:
- KNN (K-Nearest Neighbors)
- Regressione Gaussiana
- Alberi decisionali
- Reti Neurali
Algoritmi di Classificazione
Quello che differenzia un compito di regressione da uno di classificazione è il tipo di previsione che il modello deve fare.
Nel caso della regressione abbiamo detto che l'output è un numero continuo reale, come il prezzo di una casa in vendita.
Nel caso della classificazione abbiamo, per l'appunto, delle classi. Ad esempio, un classificatore è un modello di machine learning che può prevedere le classi spam o non spam quando riceve in input il testo di una email.
Dietro le quinte, un modello di classificazione è in realtà uno di regressione, poiché ad ogni classe corrisponde un numero...ma questo viene poi convertito in una etichetta come spam o non spam.
Parecchi degli algoritmi che fanno regressione quindi possono fare anche classificazione. In Sklearn tipicamente un modello di regressione la forma nome_modello + Regressor oppure nome_modello + Classifier.
Regressione Logistica
La regressione logistica è il modello di machine learning di classificazione più comune.
Nonostante il suo nome, il modello è implementato come modello lineare per la classificazione piuttosto che per la regressione in termini di nomenclatura.
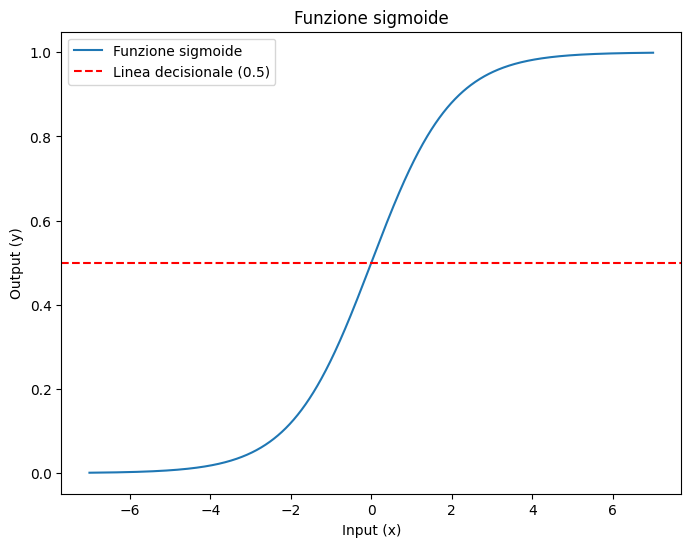
La regressione logistica è nota in letteratura anche come regressione logit. In questo modello, le probabilità che descrivono i possibili risultati sono modellate utilizzando una funzione logistica.
La funzione logistica crea la famosa curva sigmoide, dove tipicamente i valori maggiori di 0.5 vengono convertiti come 1, mentre quelli inferiori a 0.5 vengono convertiti come 0. Questo rende la sigmoide utile per modellare decisioni binarie.
Macchine a vettori di supporto (Support Vector Machines, SVM)
Le SVM sono dei modelli di machine learning molto comuni per la classificazione, nonostante esista anche la versione dedicata alla regressione.
La matematica dietro le SVM è complessa, ma l'idea è quella di trovare le equazioni che disegnano delle linee rette tra i vettori più vicini alla linea di demarcazione tra le diverse classi, chiamati proprio vettori di supporto.
L'obiettivo delle SVM è trovare un iperpiano nello spazio delle caratteristiche che può separare in modo ottimale le diverse classi di punti. L'iperpiano può essere una linea in 2D, piano in 3D o iperpiano in spazi superiori che massimizza la distanza tra i punti più vicini delle diverse classi. Questi punti più vicini sono chiamati vettori di supporto.
La distanza tra l'iperpiano e il vettore di supporto più vicino è chiamata margine. Le SVM cercano di massimizzare questo margine poiché una maggiore distanza offre una migliore generalizzazione e una maggiore capacità dell'algoritmo di classificare nuovi dati in modo accurato.
A volte, i dati non sono linearmente separabili, il che significa che non possono essere separati da un singolo iperpiano. Una delle particolarità delle SVM è la abilità di affrontare dataset non linearmente separabili grazie al trucco del kernel (kernel trick).
In questo caso, le SVM utilizzano provano a mappare i dati in uno spazio di dimensioni superiori, dove potrebbero essere linearmente separabili. Questo consente alle SVM di affrontare problemi di separazione più complessi.
Per questo motivo però le SVM sono tipicamente pesanti da usare poiché richiedono più memoria e tempi di esecuzione rispetto agli algoritmi menzionati.
Naïve Bayes
Gli algoritmi Bayesiani naïve sono molto utili per classificare documenti e in generale del testo.
Si basano sul teorema di Bayes, che è una formula per calcolare la probabilità condizionata di un evento basandosi su altre informazioni correlate all'evento.
Il teorema di Bayes afferma che
\[ P(A | B) = \frac{P(B | A) \times P(A)}{P(B)} \]
Dove:
- \( P(A | B) \) rappresenta la probabilità condizionata che l'evento A si verifichi dato che l'evento B si è verificato.
- \( P(B | A) \) rappresenta la probabilità condizionata che l'evento B si verifichi dato che l'evento A si è verificato.
- \( P(A) \) rappresenta la probabilità a priori dell'evento A.
- \( P(B) \) rappresenta la probabilità a priori dell'evento B.
La componente naïve del Naive Bayes deriva dall'assunzione che le caratteristiche utilizzate per la classificazione siano indipendenti tra loro, cioè che la presenza o l'assenza di una caratteristica non influisce sulla presenza o l'assenza di altre caratteristiche. Questa assunzione semplifica i calcoli e rende il modello più efficiente.
Il modello calcola le probabilità a priori per ciascuna classe (\(C \)) e le probabilità condizionali per ciascuna caratteristica (\(X \)) dato che l'istanza appartiene a una classe.
Per classificare una nuova istanza, il classificatore calcola la probabilità \( P(C | X) \) per ciascuna classe possibile. La classe con la probabilità massima diventa la predizione del modello.
Random Forest
Entriamo nel merito degli ensemble: gruppi di logiche e modelli che sono deboli presi singolarmente, ma che lavorando insieme raggiungono performance migliori.
Come prima, algoritmi del genere possono soddisfare sia compiti di regressione che di classificazione.
La particolarità del random forest (tradotto foresta di alberi casuali) è che è l'algoritmo che molto spesso fornisce i migliori risultati di benchmark per la maggior parte dei task di classificazione su dati tabellari.
Il random forest utilizza una "foresta" di alberi decisionali. Ogni albero crea una predizione indipendenti su un sottoinsieme casuale dei dati e fa delle previsioni basate su di essi.
Ogni albero nella foresta fa una previsione. Nel nostro esempio, uno potrebbe dire "Sì, penso che pioverà domani" e un altro potrebbe dire "No, penso che non pioverà". Quindi, ogni albero vota per la sua previsione.
Il risultato finale del Random Forest è ottenuto prendendo la previsione che ottiene più voti tra tutti gli alberi. In altre parole, si prende la votazione di maggioranza tra gli alberi.
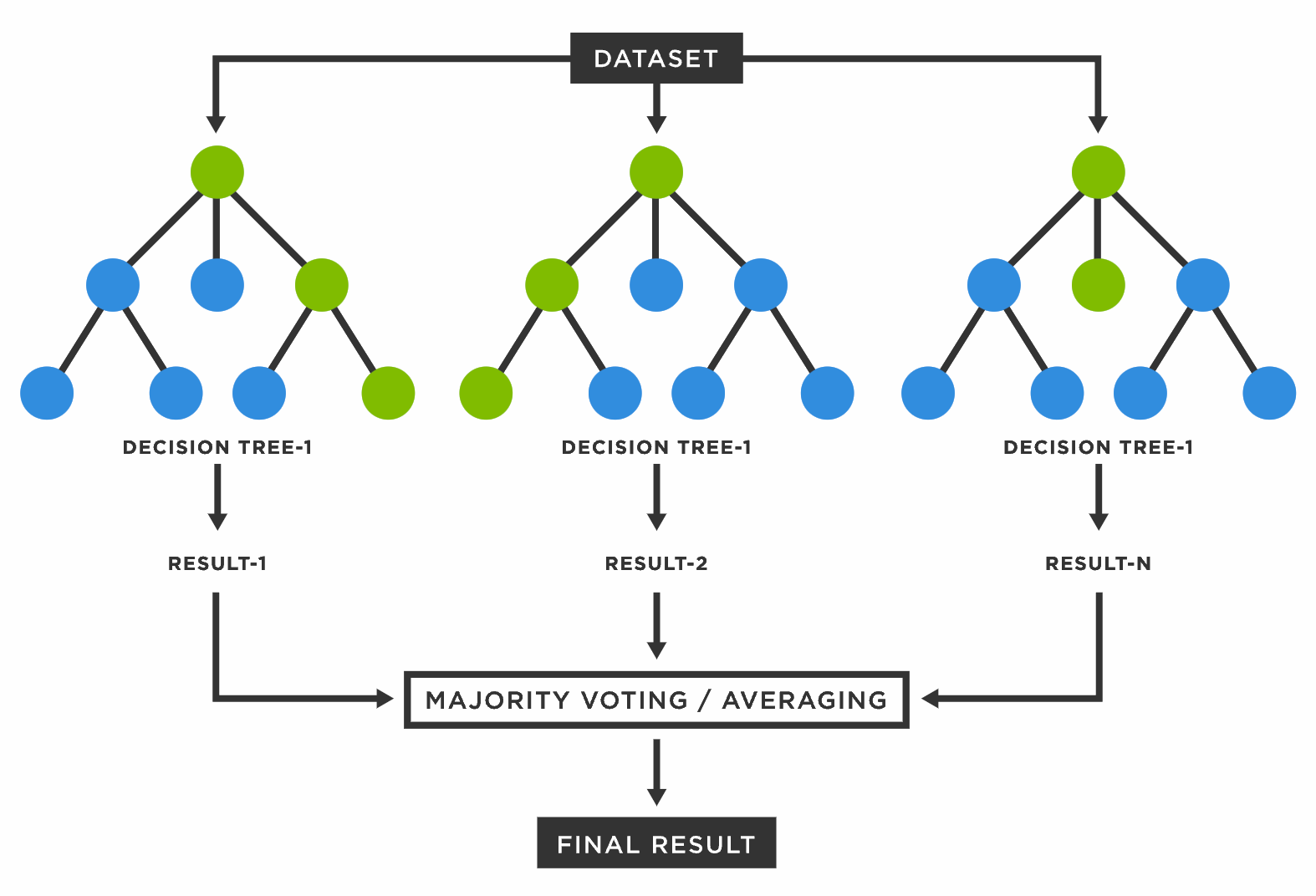
L'idea chiave qui è che combinando le opinioni di molti alberi diversi, si ottiene una previsione più affidabile e robusta, che è proprio il concetto dell'ensemble. Questo rende il Random Forest molto potente perché riduce il rischio che un singolo albero prenda decisioni errate a causa di dati casuali o rumore.
Oltre Sklearn: XGBoost
XGBoost (Extreme Gradient Boosting) è un algoritmo di machine learning molto potente, che è considerato come lo stato dell'arte della predizione su dati tabellari.
L'obiettivo principale di XGBoost è trovare il miglior equilibrio tra la complessità degli alberi (quanto sono profondi e complessi) e la precisione della previsione.
L'algoritmo cerca di ottenere alberi che siano abbastanza complessi da adattarsi ai dati, ma non così complessi da soffrire di overfitting (ovvero, adattarsi troppo ai dati di allenamento e non generalizzare bene a nuovi dati).
XGBoost è basato su alberi di decisione, simili a quanto abbiamo discusso per il random forest. La differenza sta nel fatto che XGB addestra questi alberi uno alla volta. Inizia con un albero e poi ne aggiunge altri in modo incrementale. Ogni nuovo albero cerca di correggere gli errori commessi dai precedenti.
Gli alberi deboli hanno dei pesi associati - questi pesi rappresentano quanto ciascun albero è abile nel risolvere il problema. XGBoost assegna un peso maggiore agli alberi che contribuiscono di più alla riduzione dell'errore complessivo.
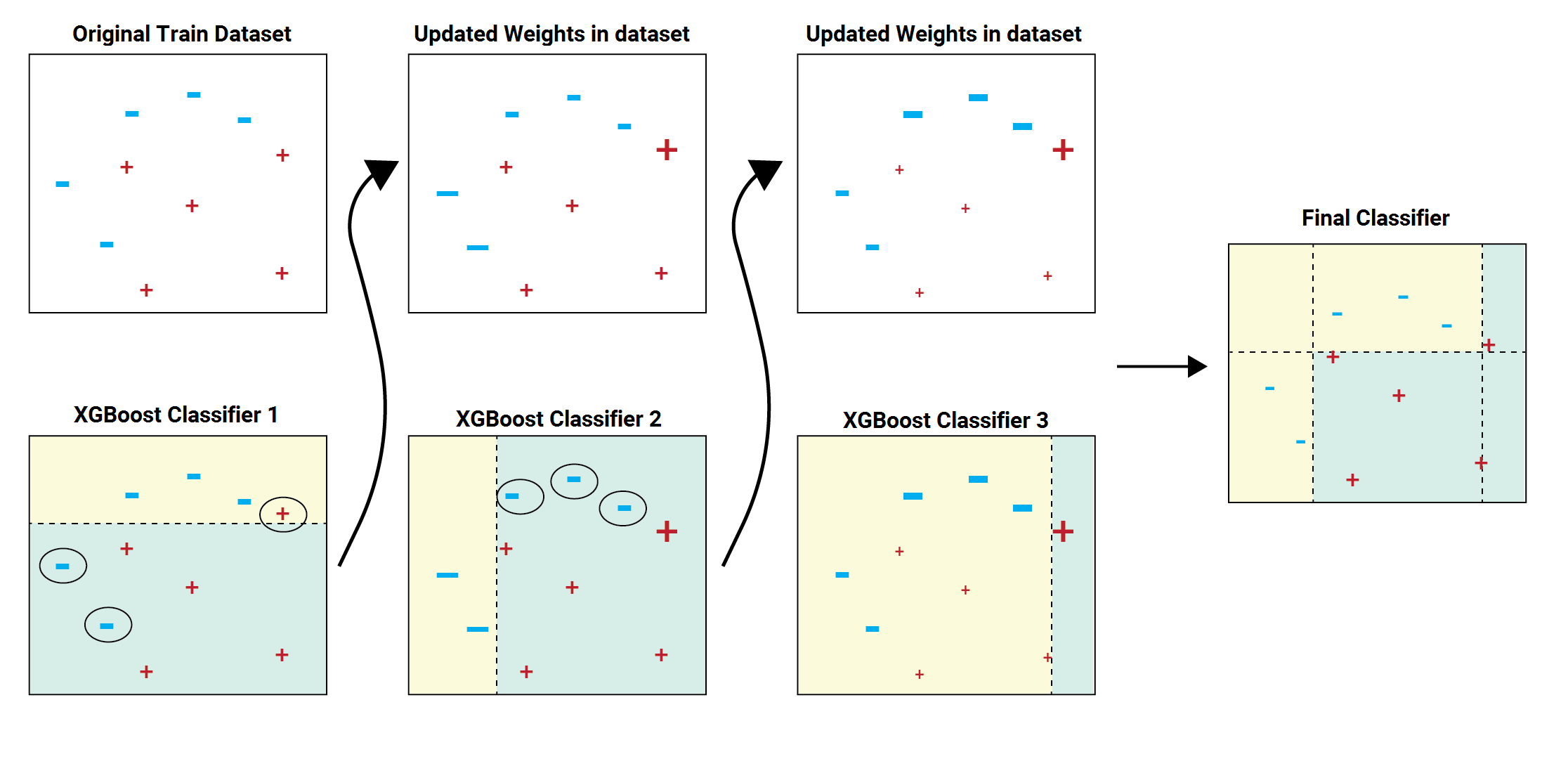
Per fare una previsione, XGBoost combina le previsioni di tutti gli alberi deboli, ponderate in base ai loro pesi. In questo modo, si ottiene una previsione finale che è una combinazione delle previsioni di tutti gli alberi.
Attraverso questo meccanismo, XGBoost è l'algoritmo più comune e gettonato per risolvere problemi tabellari di classificazione principalmente.
LightGBM
Acronimo di Light Gradient Boosting Machine, LGBM è considerato l'erede di XGBoost grazie alla sua abilità di essere addestrato e fare inferenze più velocemente.
La caratteristica chiave di LightGBM è che cerca di creare alberi più leggeri rispetto ad XGBoost. Invece di espandere l'albero in modo completo durante l'addestramento, LightGBM lo espande in modo graduale. Questo significa che l'albero ha meno profondità e meno nodi, rendendolo più leggero e più veloce da addestrare.
LGBM offre quindi performance simili e a volte superiori a XGBoost perché fondamentalmente applica delle logiche simili a quest'ultimo, preferendo performance più veloci.
Per questo motivo, LightGBM sta superando XGBoost in popolarità come algoritmo per modellare i dati tabellari più performante sia per task di regressione che classificazione.
CatBoost
CatBoost è simile a XGBoost e LightGBM, ma ha alcune caratteristiche uniche.
Come XGBoost e LightGBM, CatBoost si basa sulla creazione di alberi di decisione, la differenza sta nella gestione delle variabili categoriali. Le variabili categoriali sono quelle che rappresentano categorie, come il genere (maschio o femmina).
CatBoost è progettato per trattare automaticamente queste variabili, senza richiedere una codifica speciale. Questo semplifica notevolmente il processo di preparazione dei dati.
Come altri algoritmi di boosting, CatBoost combina le previsioni di tutti gli alberi nel modello per ottenere una previsione finale. Questo processo di combinazione produce una previsione complessiva più accurata.
Dove puoi imparare praticamente il machine learning?
Passiamo ora ai next step. Hai imparato in linea teorica cosa sia un modello, un algoritmo e il machine learning in generale.
Hai anche imparato a classificare i compiti in supervisionato e non supervisionato e ti è chiaro quali siano gli algoritmi più comuni nel settore.
Cosa fare ora?
Il mio consiglio è di seguire questa scaletta:
- Continua a leggere navigando la pagina introduttiva agli argomenti trattati in questo blog - in questa pagina raccolgo i temi trattati in livelli da principiante ad esperto.
- Registrati su Kaggle - Kaggle è la casa dei data scientist e permette di muovere i primi step tra corsi, competizioni fittizie e reali e di conversare con persone di tutti i livelli sui forum
- Unisciti ai server Discord che più ti interessano. Basta fare una breve ricerca per trovare alcnui dei server dedicati al machine learning più importanti.
Questi step ti porteranno a poter affrontare qualsiasi progetto di data science o machine learning da principiante per lanciarti nel settore.
Conclusioni
Grazie per aver letto questo articolo. Spero ti abbia intrigato abbastanza da navigare di più lo spazio del machine learning!
Leggendolo, hai imparato alcuni dei concetti introduttivi alla disciplina e alcuni dei suoi algoritmi fondamentali "tradizionali" appartenenti alla famosa libreria Scikit-Learn.
Oltre a questi, ti ho esposto a tre dei modelli più rilevanti nello spazio che non fanno parter di sklearn quali XGBoost, LightGBM e CatBoost. Ognuno di questi ha vantaggi notevoli quando si vogliono addestrare modelli tradizionali allo stato dell'arte sui dati tabellari.
I prossimi step che ti ho suggerito sono quelli di continuare l'apprendimento navigando il materiale educativo, la pagina introduttiva agli argomenti trattati in questo blog oppure Kaggle, dove puoi unirti a migliaia di appassionati di data science e ML per competere su progetti reali oppure scambiare opinioni sul forum.
Buona fortuna nel tuo viaggio!





{kind=link}
Commenti dalla community