
La fase di selezione delle feature presenti nel set di addestramento è di fondamentale importanza in qualsiasi progetto di machine learning.
Spiegherò l'algoritmo Boruta, in grado di creare una classifica delle nostre caratteristiche, dalla più importante alla meno impattante per il nostro modello. Boruta è semplice da usare e più potente delle tradizionali tecniche usate per lo stesso compito.
Introduzione
Iniziamo scrivendo che Boruta non è un algoritmo a se stante, ma estende l'algoritmo Random Forest. Infatti, il nome Boruta deriva dal nome dello spirito della foresta nella mitologia slava. Per comprendere come funziona l'algoritmo facciamo una introduzione al Random Forest.
Il Random Forest si basa sul bagging - crea molti campioni casuali del set di addestramento e addestra un modello statistico diverso per ognuno di essi.
Per un task di classificazione il risultato è la maggioranza dei voti da parte dei modelli, mentre per un task di regressione il risultato è la media dei vari modelli. La differenza tra il bagging canonico e quello fatto nel Random Forest è che quest'ultimo utilizza sempre e solo modelli di albero di decisione (decision trees).
Per ogni campione preso in considerazione, l'albero decisionale prende in considerazione un set limitato di feature. Questo permette all'algoritmo Random Forest di poter stimare l'importanza di ogni feature, poiché traccia l'errore nelle predizioni proprio in base allo split di feature considerate.
Prendiamo in considerazione un task di classificazione. Il modo in cui Random Forest stimi l'importanza delle feature funziona in due fasi. Per prima cosa, ogni albero decisionale crea una predizione e questa viene memorizzata. Secondo, i valori di certe feature vengono permutati casualmente attraverso i vari esempi e lo step precedente viene ripetuto, andando a tracciare il risultato delle predizioni nuovamente.
L'importanza di una feature per un singolo albero decisionale è calcolato come la differenza delle performance tra il modello che utilizza le feature originali contro quello che utilizza le feature permutate diviso per il numero di esempi nel set di addestramento. L'importanza di una feature è la media delle misurazioni tra tutti gli alberi per quella feature.
Quello che non viene fatto durante questa procedura è calcolare gli z-score per ogni feature. Qui entra in gioco Boruta.
L'Algoritmo Boruta
L'idea di Boruta è abbastanza semplice: per tutte le feature presenti nel dataset originale, ne andiamo a creare delle copie casuali (chiamate shadow feature - caratteristiche fantasma) e addestrare dei classificatori che si basano su questo dataset esteso. Per comprendere l'importanza di una feature, la compariamo a tutte le shadow feature generate. Solo le feature che sono statisticamente più importanti delle feature sintetiche vengono mantenute poiché contribuiscono di più alle performance del modello.
Ecco gli step principali che effettua Boruta per la selezione delle feature
- Crea una copia delle feature del set di addestramento e le unisce alle feature originali
- Crea permutazioni casuali sulle feature sintetiche per rimuovere ogni tipo di correlazione tra queste e la variabile target y - in pratica, queste feature sintetiche sono combinazioni randomizzate della feature originale dalla quale derivano
- Si comporta come il Random Forest: le feature sintetiche sono randomizzate a ogni nuova iterazione
- Per ogni nuova iterazione, calcola lo z-score di tutte le feature originali e di quelle sintetiche. Una feature è considerata rilevante se la sua importanza è più alta della importanza massima di tutte le feature sintetiche
- Applica un test statistico per tutte le feature originali e traccia i suoi risultati. L'ipotesi nulla è che l'importanza di una feature sia uguale alla importanza massima delle feature sintetiche.
Il test statistico va a testare l'uguaglianza tra le feature originali e quelle sintetiche. L'ipotesi nulla viene respinta quando l'importanza di una feature è significativamente più alta o più bassa di una di quelle delle feature sintetiche - Rimuove le feature che sono considerate non importanti dal dataset, sia dal dataset originale che da quello sintetico
- Ripete tutti gli step per un numero n di iterazioni finché tutte le feature sono rimosse o considerate importanti
Va notato che Boruta agisce come una euristica: vale a dire che non ci sono garanzie della sua performance. È dunque consigliabile lanciare il processo più volte e valutarne i risultati.
Esempio di utilizzo in Python
Vediamo come funziona Boruta in Python con la libreria dedicata. Useremo il dataset load_diabetes() di Sklearn.datasets per testare Boruta su un problema di regressione.
Il feature set X è composto dalle variabili
- age (età in anni)
- sex (sesso)
- bmi (body mass index, indice di massa corporea)
- bp (pressione sanguigna media)
- s1 (tc, colesterolo totale)
- s2 (ldl, low-density lipoproteins)
- s3 (hdl, high-density lipoproteins)
- s4 (tch, colesterolo totale / HDL)
- s5 (ltg, logaritmo del livello di trigliceridi)
- s6 (glu, livello di zucchero nel sangue)
il target y è la progressione del diabete registrata nel tempo.
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from boruta import BorutaPy
import pandas as pd
import numpy as np
# da sklearn, carichiamo il dataset del diabete
X, y = load_diabetes(return_X_y=True, as_frame=True)
# inizializziamo un modello Random Forest
model = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
# inizializziamo Boruta
feat_selector = BorutaPy(
verbose=2,
estimator=model,
n_estimators='auto',
max_iter=10 # numero di iterazioni da fare
)
# addestriamo Boruta
# N.B.: X e y devono essere numpy array
feat_selector.fit(np.array(X), np.array(y))
# stampiamo supporto e ranking per ogni feature
print("\n------Support e Ranking per ogni feature------")
for i in range(len(feat_selector.support_)):
if feat_selector.support_[i]:
print("Passa il test: ", X.columns[i],
" - Ranking: ", feat_selector.ranking_[i])
else:
print("Non passa il test: ",
X.columns[i], " - Ranking: ", feat_selector.ranking_[i])Lanciando lo script vedremo in terminale come Boruta stia costruendo le sue inferenze
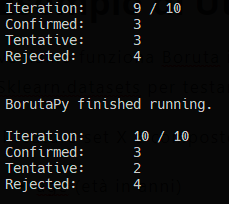
Il nostro report stampa questo risultato, molto comprensibile
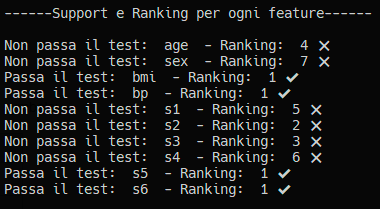
Vediamo come bmi, bp, s5 e s6 siano le feature da usare poiché quelle più importanti. Boruta le ha identificate e ci ha aiutato nella selezione delle feature per il nostro modello.
Per filtrare il nostro dataset e selezionare solo le feature che per Boruta sono importanti basta fare feat_selector.transform(np.array(X)) che restituirà un array Numpy.
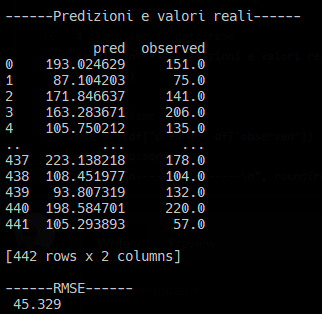
Ora siamo pronti per fornire al nostro modello RandomForestRegressor un set di selezionato di feature X. Addestriamo il modello e stampiamo il Root Mean Squared Error (RMSE).
print("\n------Feature selezionate------\n")
print(X_filtered)
# set di feature selezionate da Boruta
X_filtered = feat_selector.transform(np.array(X))
# addestriamo il modello
model.fit(X_filtered, y)
# calcoliamo la predizione
predictions = model.predict(X_filtered)
# creiamo un dataframe con le predizioni e i valori reali
df = pd.DataFrame({'pred': predictions, 'observed': y})
# stampiamo il dataframe
print("\n------Predizioni e valori reali------\n")
print(df)
# calcoliamo RMSE
mse = ((df['pred'] - df['observed']) ** 2).mean()
rmse = np.sqrt(mse)
print("\n------RMSE------\n", round(rmse, 3))Ecco i risultati dell'addestramento
Il Codice
Il codice completo qui in formato copia-incolla
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from boruta import BorutaPy
import pandas as pd
import numpy as np
# da sklearn, carichiamo il dataset del diabete
X, y = load_diabetes(return_X_y=True, as_frame=True)
# inizializziamo un modello Random Forest
model = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
# inizializziamo Boruta
feat_selector = BorutaPy(
verbose=2,
estimator=model,
n_estimators='auto',
max_iter=10, # numero di iterazioni da fare
random_state=42,
)
# addestriamo Boruta
# N.B.: X e y devono essere numpy array
feat_selector.fit(np.array(X), np.array(y))
# stampiamo supporto e ranking per ogni feature
print("\n------Support e Ranking per ogni feature------\n")
for i in range(len(feat_selector.support_)):
if feat_selector.support_[i]:
print("Passa il test: ", X.columns[i],
" - Ranking: ", feat_selector.ranking_[i], "✔️")
else:
print("Non passa il test: ",
X.columns[i], " - Ranking: ", feat_selector.ranking_[i], "❌")
# set di feature selezionate da Boruta
X_filtered = feat_selector.transform(np.array(X))
print("\n------Feature selezionate------\n")
print(X_filtered)
# addestriamo il modello
model.fit(X_filtered, y)
# calcoliamo la predizione
predictions = model.predict(X_filtered)
# creiamo un dataframe con le predizioni e i valori reali
df = pd.DataFrame({'pred': predictions, 'observed': y})
# stampiamo il dataframe
print("\n------Predizioni e valori reali------\n")
print(df)
# calcoliamo RMSE
mse = ((df['pred'] - df['observed']) ** 2).mean()
rmse = np.sqrt(mse)
print("\n------MSE------\n", round(rmse, 3))




Commenti dalla community