
In ogni progetto di machine learning saremo posti di fronte all'esigenza di dover selezionare un modello per iniziare migliorare quella che è la nostra baseline di partenza.
Infatti, se la baseline ci da un modello di partenza utile per capire cosa possiamo aspettarci da una soluzione molto semplice, un modello selezionato attraverso una metodologia specifica ci aiuta entrare nella fase di ottimizzazione del progetto.
La metodologia
Poniamo che abbiamo un problema di regressione da risolvere. Iniziamo importando tre librerie fondamentali
from sklearn import linear_model
from sklearn import ensemble
from sklearn import tree
from sklearn import svm
from sklearn import neighbors
from lightgbm import LGBMRegressor
from xgboost import XGBRegressorUseremo questo tipo di metodologia per selezionare il modello:
- creeremo una lista vuota e la popoleremo con la coppia (nome_modello, modello)
- definiremo i parametri per lo split dei dati attraverso il cross-validatore KFold di Scikit-Learn
- creeremo un ciclo for dove andremo a cross-validare ogni modello e a salvare la sua performance
- visualizzeremo la performance di ogni modello per poter scegliere quello che ha performato meglio
Definiamo una lista e inseriamo i modelli che vogliamo testare.
models = []
models.append(('Lasso', linear_model.Lasso()))
models.append(('Ridge', linear_model.Ridge()))
models.append(('EN', linear_model.ElasticNet()))
models.append(('RandomForest', ensemble.RandomForestRegressor()))
models.append(('KNR', neighbors.KNeighborsRegressor()))
models.append(('DT', tree.DecisionTreeRegressor()))
models.append(('ET', tree.ExtraTreeRegressor()))
models.append(('LGBM', LGBMRegressor()))
models.append(('XGB', XGBRegressor()))
models.append(('GBM', ensemble.GradientBoostingRegressor()))
models.append(("SVR", svm.LinearSVR()))Per ogni modello appartenente alla lista models, andremo a valutarne la performance attraverso model_selection.KFold.
Il suo funzionamento è semplice: il nostro set di dati di addestramento (X_train, y_train) verrà diviso in parti uguali (quelle che vengono chiamate folds) che verranno testate singolarmente.
Quindi la KFold cross-validation fornirà una metrica di performance media per ogni split anziché una metrica singola basata sull'intero dataset di addestramento. Questa tecnica è molto utile perché permette di misurare più accuratamente la performance di un modello.
Poiché si tratta di un problema di regressione, useremo la metrica dell'RMSE (root mean squared error).
Definiamo così i parametri per la cross-validazione inizializziamo il ciclo for.
n_folds = 5 # numero di split
results = [] # lista dove salvare le performance
names = [] # lista dove salvare i nomi dei modelli per la visualizzazione
# iniziamo il ciclo dove andremo a testare ogni modello
for name, model in models:
kfold = model_selection.KFold(n_splits=n_folds)
print("Testing model:", name)
cv_results = model_selection.cross_val_score(
model,
X_train,
y_train,
cv=kfold,
scoring="neg_mean_absolute_error",
verbose=0,
n_jobs=-1)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg+"\n")Ogni modello verrà quindi sottoposto a cross-validazione, testato, e la sua performance salvata in results.
La visualizzazione è molto semplice, e verrà fatta attraverso boxplot.
# Modelli messi a confronto
fig = plt.figure(figsize=(12,7))
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()Il risultato della selezione
Il risultato finale sarà questo:
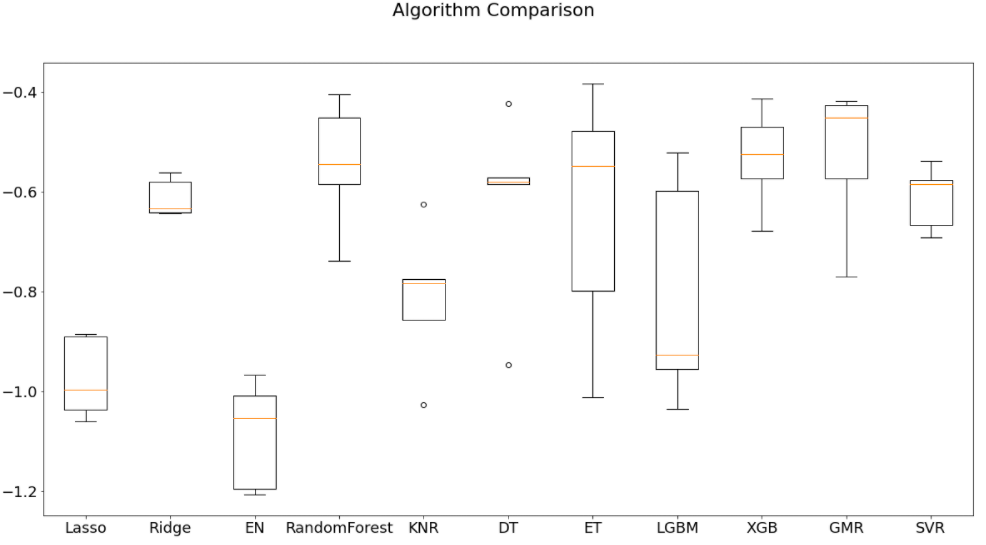
Da qui si nota come RandomForest e GradientBoostingMachine siano i più performanti. Possiamo quindi iniziare a creare nuovi esperimenti e a testare ulteriormente questi due modelli.





Commenti dalla community