
Tabella dei Contenuti
L'addestramento di modelli di Deep Learning non si basa unicamente su architetture neurali all'avanguardia o su algoritmi di ottimizzazione sofisticati. Molto spesso, il fattore che determina il successo o il fallimento di un progetto risiede in un'area meno celebrata ma assolutamente cruciale: l'efficienza della pipeline di dati.
Un'infrastruttura di training inefficiente si traduce in uno spreco di tempo, risorse e denaro, lasciando le potenti Unità di Elaborazione Grafica (GPU) inattive, un fenomeno noto come GPU starvation. Tale inefficienza non solo ritarda lo sviluppo, ma aumenta anche i costi operativi, sia su infrastrutture cloud che on-premise.
Questo articolo si propone come una guida pratica e approfondita per identificare e risolvere i colli di bottiglia più comuni nel ciclo di addestramento in PyTorch.
L'analisi si concentrerà sulla gestione dei dati, il cuore pulsante di ogni loop di training, dimostrando come un'ottimizzazione mirata possa sbloccare il pieno potenziale dell'hardware, partendo dagli aspetti teorici fino alla sperimentazione pratica.
- Colli di bottiglia comuni che rallentano lo sviluppo e l'addestramento di una rete neurale
- Principi fondamentali per ottimizzare il training loop in PyTorch
- Parallelismo e gestione della memoria in addestramento
Motivazioni per ottimizzazione del training
Efficientare l'addestramento di modelli di deep learning è una necessità strategica. In primo luogo, essa si traduce direttamente in un significativo risparmio di risorse economiche e di tempo di calcolo.
Un training più rapido consente:
- cicli di sperimentazione più veloci
- validazione di nuove idee
- esplorazione di diverse architetture e l'affinamento degli iperparametri
Questo accelera il ciclo di vita del modello, permettendo alle organizzazioni di innovare e portare le loro soluzioni sul mercato con maggiore rapidità.
Ad esempio, l'ottimizzazione del training permette a un'azienda di analizzare rapidamente grandi volumi di dati per identificare trend e pattern, un'attività fondamentale per il riconoscimento di pattern o per la manutenzione predittiva nel settore manifatturiero.
Analisi dei colli di bottiglia più comuni
I rallentamenti si manifestano spesso in un'interazione complessa tra CPU, GPU, memoria e dispositivi di archiviazione.
Ecco i principali colli di bottiglia che possono rallentare l'addestramento di una rete neurale:
- I/O e Dati: Il problema principale è la "GPU starvation", dove la GPU è inattiva in attesa che la CPU carichi e pre-processi il lotto di dati successivo. Questo è comune con set di dati di grandi dimensioni che non possono essere caricati interamente in RAM. La velocità del disco è fondamentale: le unità SSD NVMe possono essere fino a 35 volte più veloci degli HDD tradizionali.
- GPU: Si verifica quando la GPU è satura (modello computazionalmente pesante) o, più spesso, è sotto-utilizzata per mancanza di dati forniti dalla CPU. Le GPU, con i loro numerosi core a bassa velocità, sono ottimizzate per l'elaborazione parallela, a differenza delle CPU che eccellono nell'elaborazione sequenziale .
- Memoria: L'esaurimento della memoria, spesso manifestato come
RuntimeError: CUDA out of memory, costringe a ridurre la dimensione del batch. La tecnica di accumulo dei gradienti può simulare un batch size maggiore, ma non aumenta il throughput.
Perché CPU e I/O sono spesso i limiti principali ?
Un aspetto fondamentale dell'ottimizzazione risiede nella comprensione del "collo di bottiglia a cascata".
In un tipico sistema di training, la GPU è il motore di calcolo, mentre la CPU è responsabile della preparazione dei dati. Se il disco è lento, la CPU passa la maggior parte del tempo ad attendere i dati, diventando il collo di bottiglia primario. Di conseguenza, la GPU, non avendo dati da elaborare, rimane inattiva.
Questo comportamento porta a credere, erroneamente, che il problema sia l'hardware della GPU, quando invece l'inefficienza risiede nella catena di approvvigionamento dei dati. Aumentare la potenza di calcolo della GPU senza risolvere il collo di bottiglia a monte è una spesa inutile, poiché le performance di training non supereranno mai la velocità del componente più lento del sistema. Pertanto, il primo passo per un'ottimizzazione efficace è individuare e risolvere il problema alla radice, che molto spesso risiede nell'I/O o nella pipeline dei dati.
Strumenti e librerie per l’analisi e l’ottimizzazione
Un’ottimizzazione efficace richiede un approccio basato sui dati, non su tentativi. PyTorch mette a disposizione strumenti e primitive pensati per diagnosticare i colli di bottiglia e migliorare il ciclo di training. Ecco i tre ingredienti fondamentali della nostra sperimentazione:
- Dataset e DataLoader
- TorchVision
- Profiler
Dataset e DataLoader in PyTorch
La gestione efficiente dei dati è il cuore di ogni loop di training. PyTorch fornisce due astrazioni fondamentali chiamate Dataset e dataloader

Ecco una breve infarinatura
torch.utils.data.Dataset
È la classe base che rappresenta un insieme di campioni e relative etichette.
Per creare un dataset personalizzato, basta implementare tre metodi:__init__: inizializza percorsi o connessioni ai dati,__len__: restituisce la lunghezza del dataset,__getitem__: carica ed eventualmente trasforma un singolo campione.
torch.utils.data.DataLoader
È l’interfaccia che avvolge il dataset e lo rende iterabile in modo efficiente.
Gestisce automaticamente:- batching (
batch_size), - rimescolamento (
shuffle=True), - caricamento in parallelo (
num_workers), - gestione della memoria (
pin_memory)
- batching (
TorchVision: dataset ed operazioni standard per la Computer Vision
TorchVision è la libreria di dominio PyTorch per la Computer Vision, pensata per accelerare prototipazione e benchmark.
Le sue principali utilità sono:
- Dataset predefiniti: CIFAR-10, MNIST, ImageNet e molti altri, già implementati come sottoclassi di
Dataset. Perfetti per test rapidi senza dover costruire un dataset personalizzato. - Trasformazioni comuni: ridimensionamento, normalizzazione, rotazioni, data augmentation. Queste operazioni possono essere composte con
transforms.Composeed eseguite on-the-fly durante il caricamento, alleggerendo il preprocessing manuale. - Modelli pre-addestrati: disponibili per compiti di classificazione, rilevamento e segmentazione, utili come baseline o per il transfer learning.
Esempio d’uso:
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
train_data = datasets.CIFAR10(root="./data", train=True, download=True, transform=transform)
PyTorch Profiler: diagnosi avanzata delle prestazioni
Il PyTorch Profiler permette di capire precisamente dove viene speso il tempo di esecuzione, sia su CPU che su GPU.
Funzionalità chiave:
- Analisi dettagliata di operatori e kernel CUDA.
- Supporto multi-dispositivo (CPU/GPU).
- Esportazione dei risultati in formato
.jsono visualizzazione interattiva con TensorBoard.
Esempio d’uso:
import torch
import torch.profiler as profiler
def train_step(model, dataloader, optimizer, criterion):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
with profiler.profile(
activities=[profiler.ProfilerActivity.CPU,
profiler.ProfilerActivity.CUDA],
on_trace_ready=profiler.tensorboard_trace_handler("./log")
) as prof:
train_step(model, dataloader, optimizer, criterion)
print(prof.key_averages().table(sort_by="cuda_time_total"))
Costruzione e analisi del ciclo di addestramento
Un ciclo di training in PyTorch è un processo iterativo che, per ogni batch di dati, ripete una sequenza di step essenziali per il insegnare alla rete di tre fasi fondamentali:
- Forward Pass: Il modello calcola le predizioni a partire dal batch di input. PyTorch costruisce dinamicamente il grafo computazionale (
autograd) in questa fase per tenere traccia delle operazioni e preparare il calcolo dei gradienti . - Backward Pass: La retropropagazione (backpropagation) calcola i gradienti della funzione di perdita rispetto a tutti i parametri del modello, utilizzando la regola della catena . Questo processo viene attivato con la chiamata
loss.backward(). Prima di ognibackward pass, è fondamentale azzerare i gradienti conoptimizer.zero_grad(), poiché per impostazione predefinita PyTorch li accumula . - Aggiornamento dei pesi: L'ottimizzatore (
torch.optim) utilizza i gradienti calcolati per aggiornare i pesi del modello, minimizzando la perdita. La chiamata aoptimizer.step()esegue questo aggiornamento finale per il batch corrente .
Se vuoi leggere di più sul training loop di PyTorch, raggiungi questo articolo 👇

I rallentamenti possono insorgere in vari punti del ciclo. Se il caricamento del batch da parte del DataLoader è lento, la GPU rimane inattiva. Se il modello è computazionalmente pesante, la GPU è satura. I trasferimenti di dati tra CPU e GPU sono un'altra potenziale fonte di inefficienza, visibile come un tempo di esecuzione lungo per le operazioni cudaMemcpyAsync nel profiler.
L'obiettivo primario è garantire che la GPU non sia mai affamata, mantenendo una fornitura costante di dati.
L'ottimizzazione sfrutta il contrasto tra l'architettura della CPU (ottima per l'I/O e l'elaborazione sequenziale) e della GPU (eccellente per il calcolo parallelo) . Se il dataset è troppo grande per la RAM, un generator basato su Python può diventare una barriera significativa per l'addestramento di modelli complessi.
Un esempio può essere un ciclo di training in cui quando la GPU è in funzione, la CPU è inattiva e quando la CPU è in funzione, la GPU è inattiva, come illustrato di seguito:
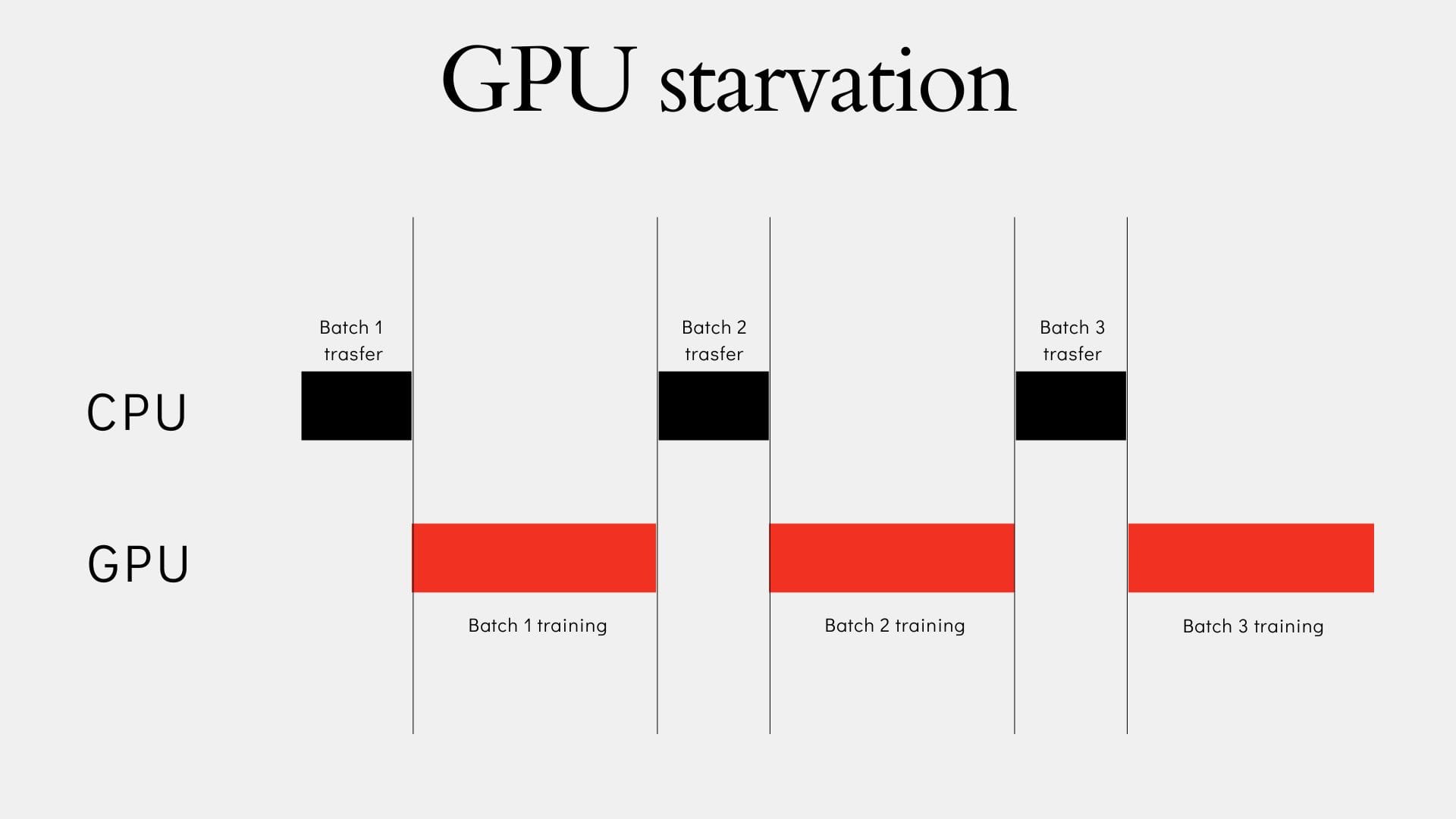
Gestione dei batch tra CPU e GPU
Il processo di ottimizzazione si basa sul concetto di sovrapposizione (overlap): il DataLoader, utilizzando worker multipli (num_workers > 0), prepara il prossimo batch in parallelo (sulla CPU) mentre la GPU elabora quello corrente.
L'ottimizzazione del DataLoader assicura che CPU e GPU lavorino in modo asincrono e simultaneo. Se il tempo di pre-elaborazione di un batch è approssimativamente uguale al tempo di calcolo della GPU, il processo di training può teoricamente raddoppiare in velocità.
Questo comportamento di precaricamento può essere controllato tramite il parametro prefetch_factor del DataLoader, che determina il numero di batch caricati in anticipo da ciascun worker .
Metodologie per diagnosticare i colli di bottiglia
L'uso del PyTorch Profiler è fondamentale per trasformare il processo di ottimizzazione in una diagnosi data-driven. Analizzando le metriche di tempo trascorso, è possibile individuare la causa principale dell'inefficienza:
| Sintomo rilevato dal Profiler | Diagnosi (Collo di Bottiglia) | Soluzione raccomandata |
|---|---|---|
Alto Self CPU total % per DataLoader |
Lento pre-processing e/o caricamento dati lato CPU | Aumentare num_workers |
Tempo di esecuzione elevato per cudaMemcpyAsync |
Lento trasferimento dati tra CPU e memoria GPU | Abilitare pin_memory=True |
Tecniche di ottimizzazione del caricamento dei dati
Le due tecniche più efficaci implementate nel DataLoader di PyTorch sono il parallelismo dei worker e l'uso della memoria bloccata (pinned_memory).
Parallelismo con workers
Il parametro num_workers nel DataLoader abilita il multiprocessing, creando sottoprocessi che caricano e pre-elaborano i dati in parallelo. Questo aumenta significativamente il throughput del caricamento dati, sovrapponendo efficacemente il training e la preparazione del batch successivo.
- Benefici: Riduce il tempo di attesa della GPU, specialmente con set di dati di grandi dimensioni o con pre-elaborazione complessa (es. trasformazioni di immagini).
- Best Practice: Iniziare con
num_workers=0per il debugging e aumentare gradualmente, monitorando le performance. Un'euristica suggeriscenum_workers = 4 * num_GPU. - Attenzione: Un numero eccessivo di worker aumenta il consumo di RAM e può causare contese per le risorse della CPU, rallentando l'intero sistema .
Pin Memory per velocizzare i trasferimenti CPU - GPU
L'impostazione di pin_memory=True nel DataLoader alloca una speciale "memoria bloccata" (page-locked memory) sulla CPU .
- Meccanismo: Questa memoria non può essere scambiata su disco dal sistema operativo. Ciò consente trasferimenti asincroni e diretti dalla CPU alla GPU, evitando un'ulteriore copia intermedia e riducendo i tempi di inattività .
- Benefici: Accelera i trasferimenti di dati al dispositivo CUDA, permettendo alla GPU di lavorare e ricevere dati simultaneamente .
- Quando non usarlo: Se non si utilizza una GPU,
pin_memory=Truenon offre alcun beneficio e consuma solo RAM aggiuntiva non paginabile. Sui sistemi con RAM limitata, può esercitare una pressione non necessaria sulla memoria fisica .
Implementazione pratica e benchmarking
A questo punto entriamo nella fase di sperimentazione degli approcci per ottimizzare il training di modelli PyTorch, mettendo a confronto il loop di training standard con tecniche avanzate di caricamento dei dati.
Per dimostrare l'efficacia delle metodologie discusse, consideriamo un setup di sperimentazione che coinvolge una rete neurale FeedForward su un set di dati standard MNIST.
Tecniche di ottimizzazione trattate:
- Training standard (Baseline): ciclo base di addestramento in PyTorch (
num_workers=0, pin_memory=False). - Data loading multi-worker: caricamento parallelo dei dati con più processi (
num_workers=N). - Pinned Memory + Non-blocking Transfer: ottimizzazione della memoria GPU e dei trasferimenti CPU–GPU (
pin_memory=Trueenon_blocking=True). - Analisi delle performance: confronto dei tempi di esecuzione e best practices.
Configurazione dell'ambiente di sperimentazione
STEP 1: Importare le librerie
Il primo passo consiste nell'importare tutte le librerie necessarie e verificare la configurazione dell'hardware:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from time import time
import warnings
warnings.filterwarnings('ignore')
print("=" * 60)
print("STUDIO DI OTTIMIZZAZIONE DELL'ADDESTRAMENTO ML")
print("=" * 60)
print(f"Versione PyTorch: {torch.__version__}")
print(f"CUDA disponibile: {torch.cuda.is_available()}")
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"Dispositivo GPU: {torch.cuda.get_device_name(0)}")
print(f"Memoria GPU: {torch.cuda.get_device_properties(0).total_memory / 1e9:.1f} GB")
else:
device = torch.device("cpu")
print("Uso della CPU - Considera l'uso della GPU per prestazioni migliori")
print(f"Dispositivo per l'addestramento: {device}")
print("=" * 60)
Risultato Atteso :
============================================================
STUDIO DI OTTIMIZZAZIONE DELL'ADDESTRAMENTO ML
============================================================
Versione PyTorch: 2.8.0+cu126
CUDA disponibile: True
Dispositivo GPU: NVIDIA GeForce RTX 4090
Memoria GPU: 25.8 GB
Dispositivo per l'addestramento: cuda
============================================================STEP 2: Analisi e Caricamento del Dataset
Il dataset MNIST è un punto di riferimento fondamentale, costituito da 70.000 immagini 28x28 in scala di grigi. La normalizzazione dei dati è un punto fondamentale per l'efficienza del training.
Definiamo la funzione per il caricamento del dataset:
# Definizione delle trasformazioni dei dati: conversione in tensor e normalizzazione
transform = transforms.Compose(
)
# Caricamento del dataset MNIST
train_dataset = datasets.MNIST(root='./data',
train=True,
download=True,
transform=transform)
test_dataset = datasets.MNIST(root='./data',
train=False,
download=True,
transform=transform)
STEP 3: Implementazione di una rete neurale semplice per MNIST
Definiamo una semplice rete neurale FeedForward per la nostra sperimentazione:
class SimpleFeedForwardNN(nn.Module):
def __init__(self):
super(SimpleFeedForwardNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
STEP 4: Definizione del classico ciclo di addestramento (Funzione)
Definiamo la funzione di training riutilizzabile che incapsula le tre fasi chiave (Forward Pass, Backward Pass e Parameter Update):
def train(model,
device,
train_loader,
optimizer,
criterion,
epoch,
non_blocking=False):
model.train()
loss_value = 0
for batch_idx, (data, target) in enumerate(train_loader):
# Trasferimento dati su dispositivo (GPU) con opzione non_blocking
data = data.to(device, non_blocking=non_blocking)
target = target.to(device, non_blocking=non_blocking)
optimizer.zero_grad() # Preparazione al Backward Pass
output = model(data) # 1. Forward Pass
loss = criterion(output, target)
loss.backward() # 2. Backward Pass
optimizer.step() # 3. Parameter Update
loss_value += loss.item()
print(f'Epoch {epoch} | Average Loss: {loss_value:.6f}')
Analisi 1: Ciclo di addestramento senza ottimizzazione (Baseline)
Configurazione con caricamento dati sequenziale (num_workers=0, pin_memory=False):
model = SimpleFeedForwardNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# DataLoader di BASE: num_workers=0, pin_memory=False
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
start = time()
num_epochs = 5
print("\n==================================================\nEXPERIMENT: Standard Training (Baseline)\n==================================================")
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, optimizer, criterion, epoch, non_blocking=False)
total_time_baseline = time() - start
print(f"✅ Experiment completed in {total_time_baseline:.2f} seconds")
print(f"⏱️ Average time per epoch: {total_time_baseline / num_epochs:.2f} seconds")
Risultato Atteso (Scenario Baseline):
==================================================
EXPERIMENT: Standard Training (Baseline)
==================================================
Epoch 1 | Average Loss: 0.240556
Epoch 2 | Average Loss: 0.101992
Epoch 3 | Average Loss: 0.072099
Epoch 4 | Average Loss: 0.055954
Epoch 5 | Average Loss: 0.048036
✅ Experiment completed in 22.67 seconds
⏱️ Average time per epoch: 4.53 seconds
Analisi 2: Ciclo di addestramento con ottimizzazione: Workers
Introduciamo il parallelismo nel caricamento dati con num_workers=8:
model = SimpleFeedForwardNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# DataLoader con ottimizzazione WORKERS
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=8)
start = time()
num_epochs = 5
print("\n==================================================\nEXPERIMENT: Multi-Worker Data Loading (8 workers)\n==================================================")
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, optimizer, criterion, epoch, non_blocking=False)
total_time_workers = time() - start
print(f"✅ Experiment completed in {total_time_workers:.2f} seconds")
print(f"⏱️ Average time per epoch: {total_time_workers / num_epochs:.2f} seconds")
Risultato Atteso (Scenario Workers):
==================================================
EXPERIMENT: Multi-Worker Data Loading (8 workers)
==================================================
Epoch 1 | Average Loss: 0.228919
Epoch 2 | Average Loss: 0.100304
Epoch 3 | Average Loss: 0.071600
Epoch 4 | Average Loss: 0.056160
Epoch 5 | Average Loss: 0.045787
✅ Experiment completed in 9.14 seconds
⏱️ Average time per epoch: 1.83 seconds
Analisi 3: Ciclo di addestramento con ottimizzazione: Worker + Pin Memory
Aggiungiamo pin_memory=True nel DataLoader e non_blocking=True nel ciclo train per il trasferimento asincrono:
model = SimpleFeedForwardNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# DataLoader con ottimizzazione WORKERS + PIN MEMORY
train_loader = DataLoader(train_dataset,
batch_size=64,
shuffle=True,
pin_memory=True, # Attiva la memoria bloccata
num_workers=8)
start = time()
num_epochs = 5
print("\n==================================================\nEXPERIMENT: Pinned Memory + Non-blocking Transfer (8 workers)\n==================================================")
# non_blocking=True per il trasferimento asincrono
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, optimizer, criterion, epoch, non_blocking=True)
total_time_optimal = time() - start
print(f"✅ Experiment completed in {total_time_optimal:.2f} seconds")
print(f"⏱️ Average time per epoch: {total_time_optimal / num_epochs:.2f} seconds")
Risultato Atteso (Scenario Ottimale):
==================================================
EXPERIMENT: Pinned Memory + Non-blocking Transfer (8 workers)
==================================================
Epoch 1 | Average Loss: 0.269098
Epoch 2 | Average Loss: 0.123732
Epoch 3 | Average Loss: 0.090587
Epoch 4 | Average Loss: 0.073081
Epoch 5 | Average Loss: 0.062543
✅ Experiment completed in 9.00 seconds
⏱️ Average time per epoch: 1.80 secondsAnalisi e interpretazione e dei risultati
L'analisi dei risultati dimostra chiaramente l'impatto dell'ottimizzazione della pipeline di dati sul tempo totale di addestramento. Passare dal caricamento sequenziale (Baseline) al caricamento parallelo (Multi-Worker) riduce il tempo totale di oltre il 50%. L'aggiunta di Pinned Memory e trasferimento non-bloccante offre un ulteriore piccolo ma significativo miglioramento.
| Metodo | Tempo Totale (s) | Speedup |
| Standard Training (Baseline) | 22.67 | baseline |
| Multi-Worker Loading (8 workers) | 9.14 | 2.48x |
| Optimized (Pinned + Non-blocking) | 9.00 | 2.52x |
Riflessioni sui Risultati:
- Impatto di
num_workers: L'introduzione di 8 worker ha ridotto il tempo totale di addestramento da 22.67 secondi a 9.14 secondi, con un aumento della velocità di 2.48x. Questo dimostra che il collo di bottiglia principale nel caso baseline era il caricamento dei dati (CPU starvation della GPU). - Impatto di
pin_memory: L'aggiunta dipin_memory=Trueenon_blocking=Trueha ridotto ulteriormente il tempo a 9.00 secondi, fornendo un leggero aumento delle prestazioni totali fino a 2.52x. Questo miglioramento, sebbene modesto, riflette l'eliminazione dei piccoli ritardi sincroni durante il trasferimento dei dati tra la memoria bloccata della CPU e la GPU (operazionecudaMemcpyAsync).
I risultati ottenuti non sono universali. L'efficacia delle ottimizzazioni dipende da fattori esterni:
- Batch Size: Un batch più grande può migliorare l'efficienza di calcolo della GPU, ma può causare errori di memoria (
OOM). Se si verifica un collo di bottiglia I/O, l'aumento della dimensione del batch potrebbe non portare a un training più veloce. - Hardware: L'efficacia di
num_workersè direttamente correlata al numero di core della CPU e alla velocità di I/O (SSD vs. HDD). - Dataset/Pre-processing: La complessità delle trasformazioni applicate ai dati influenza il carico di lavoro della CPU e, di conseguenza, il valore ottimale di
num_workers
Conclusioni
L'ottimizzazione delle prestazioni di una rete neurale non si limita alla scelta dell'architettura o dei parametri di training. Monitorare costantemente la pipeline e identificare i colli di bottiglia (CPU, GPU o trasferimenti dati) permette di ottenere significativi guadagni in efficienza.
Best practice da ricordare
La diagnostica tramite strumenti come PyTorch Profiler è fondamentale. L'ottimizzazione del DataLoader rimane il miglior punto di partenza ("Biggest Bang for Buck") per risolvere i problemi di inattività della GPU.
| Parametro (DataLoader) | Effetto sull'efficienza | Quando usarlo |
|---|---|---|
num_workers |
Parallelizza pre-processing e caricamento, riducendo l'attesa della GPU. | Quando il profiler indica un collo di bottiglia lato CPU. |
pin_memory |
Velocizza i trasferimenti asincroni CPU-GPU. | Sempre se si usa una GPU, per eliminare un potenziale collo di bottiglia. |
Possibili sviluppi futuri oltre il DataLoader
Per un'ulteriore accelerazione, è possibile esplorare tecniche avanzate:
- Automatic Mixed Precision (AMP): utilizzo di tipi di dato a precisione ridotta (FP16) per accelerare i calcoli e dimezzare l'utilizzo della memoria GPU.
- Accumulo del Gradiente: tecnica per simulare un batch size più grande quando la memoria della GPU è limitata.
- Librerie Specializzate: uso di soluzioni come NVIDIA DALI per spostare l'intera pipeline di pre-processing sulla GPU, eliminando il collo di bottiglia della CPU.
- Ottimizzazioni Hardware-specifiche: utilizzo di estensioni come Intel® Extension for PyTorch per sfruttare al meglio l'hardware sottostante.





Commenti dalla community