
Il modello più comune per rappresentare numericamente del testo è il modello bag of words.
L'idea è molto semplice: ogni documento del nostro corpus viene rappresentato contando quante volte ogni parola appare in esso.
Questa rappresentazione numerica è la base per i modelli linguistici multinomiali e il modello vettoriali.
Prendiamo ad esempio due frasi inerenti al cinema prese da Wikiquote. Ogni frase qui viene considerato un documento estratto da un corpus di testi più grande.
Chiunque controlli il cinema, controlla il mezzo più potente di penetrazione delle masse!
Con un'espressione sintetica si può dire che il cinema scientifico ci ha permesso di "vedere l'invisibile"
Rappresentiamo questi due testi in una matrice, in questo modo

Questa viene chiamata matrice documento-caratteristica (document-feature matrix): ogni riga rappresenta un diverso documento e ogni colonna definisce la caratteristica usata per rappresentare il documento.
Questa matrice offre una rappresentazione parsimoniosa dei testi processati che può essere di fatto molto al ricercatore.
Supponendo di non sapere nulla dei testi da processare, calcolare una document-feature matrix permette di estrarre facilmente l'argomento principale dei testi andando a sommare le colonne per ogni termine presente nel corpus.

cinema è la parola più comune e infatti i nostri testi sono proprio inerenti al cinema.
Questo, in soldoni, è il modello bag of words e sebbene questo sia abbastanza semplice alla base, permette di estrarre informazioni rilevanti da un corpus di testi come abbiamo appena visto.
L'algoritmo per modello bag of words
Ecco l'algoritmo per implementare da zero il modello bag of words:
- Scegliere l'unità di analisi
- Tokenizzare il testo
- Ridurre la complessità
- Creare la matrice documento-caratteristica
1. Scegliere l'unità di analisi
In questa fase il ricercatore deve decidere che unità logica analizzare col modello BoW. Spesso e volentieri si tratta del documento stesso, come abbiamo visto prima.
A volte però l'esigenza del ricercatore può essere diversa, e potrebbe aver bisogno di studiare un documento più corto o più lungo.
Ad esempio potrebbe essere utile usare come unità di analisi solamente il titolo oppure i primi paragrafi dell'articolo.
A volte invece potrebbe essere utile considerare come documento l'unione di diversi articoli, uno dopo l'altro.
Nell'esempio che ho usato sopra, un documento è una frase estratta da Wikiquote nell'ambito del cinema.
Sembra molto semplice come concetto, ma in realtà questa è una delle fasi più delicate che si estende anche ad altri modelli linguistici.
Non sempre abbiamo idea di come sia fatto il testo dalla quale vogliamo estrarre informazioni.
Questa considerazione apre importanti riflessioni sulla struttura del testo e sulla domanda di ricerca.
- Tra i nostri testi tipicamente ben strutturati ce ne sono alcuni che non hanno un titolo. Come ci comportiamo in questo caso?
- Stiamo processando dei testi fisici e scannerizziamo questi documenti per avere una rappresentazione digitale. Come trattiamo le porzioni di testo che si trovano nei pressi della cornice o nell'intestazione?
Queste sono solo alcune domande rilevanti che dovremmo porci quando vogliamo estrarre informazioni da un testo, ed esulano il singolo modello bag of words.
2. Tokenizzare il testo
Tokenizzare significa dividere il testo in unità discrete. Queste unità sono solitamente le parole che compongono un documento. Tipicamente viene effettuata una separazione a livello di spazio tra una parola e l'altra, ma esistono tokenizzatori che applicano regole di divisione anche più complesse.
Ogni singola parola viene chiamata token.
Tokenizzare ci permette di contare efficacemente le parole all'interno di un documento e creare la document-term matrix.
A volte la tokenizzazione può includere anche più di una parola, come nel caso degli n-grammi. Un n-gramma è un insieme di più parole che hanno senso. Ad esempio, un bigramma è l'unione di due token, mentre un trigramma è l'unione di tre token.
Un esempio di bigramma può essere l'unione tra due nomi propri di persona, primo e secondo nome, in modo da mantenere in una singola unità logica il nome dell'individuo.
Esempio: Mattia Lorenzo E. -> Tokenizzazione -> [Mattia, Lorenzo] -> Bigramma: mattia_lorenzo
La creazione di n-grammi avviene solitamente attraverso l'utilizzo di mezzi statistici che calcolano la probabilità di occorrenza del primo token con il secondo.
3. Ridurre la complessità
Teoricamente, una volta tokenizzati i nostri documenti, potremmo già passare alla creazione della matrice documento-caratteristica.
Tuttavia, è molto utile andare a ridurre la complessità delle unità logiche selezionate per aiutarci nel lavoro di ricerca e analisi. Il motivo è che andremmo a lavorare con un set di token molto grande e gran parte di questi risulterebbero rumorosi e non utili.
Prendiamo nuovamente come esempio questa frase
Chiunque controlli il cinema, controlla il mezzo più potente di penetrazione delle masse!
Se prestiamo attenzione alla matrice vediamo come alcuni termini non siano presenti (come gli articoli) e come tutte le parole siano in minuscolo.

Queste sono solo due tecniche di riduzione della complessità. Vediamone alcune delle più comuni.
- ridurre a minuscolo
- rimozione della punteggiatura
- rimozione delle stop word
- lemmatizzazione
- filtro frequenza
Ridurre a minuscolo
Ridurre a minuscolo rimuove le differenze tra token uguali ma scritti interpretati dalla macchina in modo diverso a causa della lettera maiuscola. È lo strato di riduzione della complessità sicuramente più semplice e facile da implementare.
Rimozione della punteggiatura
Un segno di punteggiatura come una virgola potrebbe essere inclusa come token e fare quindi parte del vocabolario. Vogliamo evitare questo scenario. Rimuovere la punteggiatura aiuta a ridurre drasticamente il vocabolario senza perdere significato.
Rimozione delle stop word
Una stop word è una parola bannata dal nostro vocabolario. Tipicamente queste parole includono articoli determinativi e indeterminativi, preposizioni e altro. Nella nostra lista di stop word possiamo anche inserire parole che non vogliamo nel nostro vocabolario per motivi di ricerca.
Lemmatizzazione
Anche se non lo abbiamo visto nell'esempio menzionato prima, la lemmatizzazione trasforma una token nel suo lemma. Un lemma è una unità linguistica che isola la base di una parola.
Prendendo l'esempio del verbo camminare, non vogliamo nel nostro vocabolario siano presenti camminavo, camminai, camminerò. Di fatto, si parla sempre del verbo camminare. Il lemma quindi sarà camminare.
Filtro frequenza
L'ultimo step diventa quello di rimuovere token che appaiono molto raramente (o, a volte, molto spesso) nel corpus di dati. Diventa difficile fare ragionamenti su un token che appare una sola volta nel corpus e in base al modello che usiamo possiamo andare a risparmiare parecchia potenza computazionale.
4. Creare la matrice documento-caratteristica
Dopo che abbiamo tokenizzato e ridotto la complessità siamo pronti a creare la matrice documento-caratteristica.
Questa sarà una matrice \( W = N \times J \) dove ogni elemento \( W_{ij} \) è il numero di volte che un token appare all'interno del corpus di dati.
La matrice è spesso sparsa - vuol dire che contiene molti 0. Questo perché ogni documento contiene solo una piccola parte dei token unici contenuti in tutto il corpus.
Text as Data: A New Framework for Machine Learning and the Social Sciences
Justin Grimmer
Unendo diversi campi (informatica e scienze sociali, qualitativo e quantitativo, industria e mondo accademico), Text as Data è una risorsa ideale per chiunque voglia analizzare grandi raccolte di testo in un'epoca in cui i dati sono abbondanti e l'elaborazione è economica, ma le sfide durature delle scienze sociali permangono.

Limitazioni del modello bag of words
Il modello bag of words è il modello più basilare che c'è per rappresentare testo in formato numerico.
Il suo algoritmo è semplice e facile da comprendere, ma queste due caratteristiche positive vengono bilanciate da diverse limitazioni, quali
- difficoltà ad interpretare il contesto: avendo solo la frequenza di ogni token, diventa difficile comprendere il significato di tale token. Il contesto è una informazione importante che perdiamo con questo modello
- grossa richiesta computazionale per corpus molto grandi. Il fatto che la matrice documento-caratteristica sia sparsa di natura rende difficile lavorare con questo oggetto per corpus molto
Implementare il modello bag of words in Python
Implementare il modello bag of words in Python è molto semplice. Useremo sklearn e il suo CountVectorizer, che è la sua implementazione del BoW model.
Implementeremo anche tutti gli step che portano alla creazione del modello, quali tokenizzazione, riduzione della complessità e creazione della matrice...vedremo perché lavorare con sklearn renda tutto più semplice 🙂
Iniziamo col definire il nostro corpus e le librerie da importare.
import pandas as pd
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer
ita_stopwords = stopwords.words('italian')
corpus = [
'''Chiunque controlli il cinema, controlla il mezzo più potente di penetrazione delle masse!''',
'''Con un'espressione sintetica si può dire che il cinema scientifico ci ha permesso di "vedere l'invisibile''',
]Definiamo il modello
bow_model = CountVectorizer(
lowercase=True, # riduzione a minuscole
stop_words=ita_stopwords, # rimozione delle stop word italiane
analyzer='word', # identificazione delle unità logiche e tokenizzazione sullo spazio tra parole
ngram_range=(1, 2) # estrazione di unigrammi e bigrammi
)Vediamo come gli argomenti passati al modello diano indicazioni su come vogliamo trattare gli step menzionati in questo articolo. Dichiariamo esplicitamente la conversione a minuscole, l'utilizzo di stopword con NLTK, il tipo di tokenizzazione e il range di n-grammi, che qui contiene unigrammi e bigrammi.
Applichiamolo sui nostri documenti
X = bow_model.fit_transform(corpus)
Usando .get_feature_names_out() possiamo vedere gli elementi creati nella matrice finale. Notiamo gli unigrammi e bigrammi, l'assenza di punteggiatura, di stop word italiane e le parole in minuscolo.
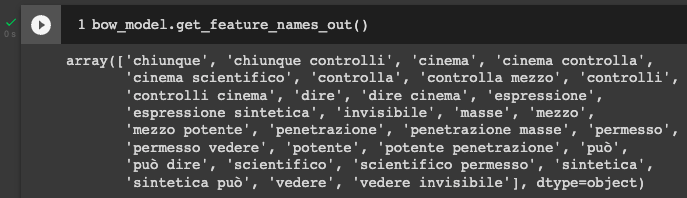
Per ottenere una matrice documento-caratteristica formattata, useremo Pandas
bow_df = pd.DataFrame(X.todense(), columns=bow_model.get_feature_names_out())
bow_df
E abbiamo la nostra matrice, molto simile a quella prima creata in Excel a inizio articolo. La differenza qui è che abbiamo anche i bigrammi.
Conclusioni
Il modello Bag of Words è uno dei modelli più semplici e intuitivi per convertire testo in formato numerico.
Questa conversione permette di sfruttare l'informazione contenuta nella frequenza dei token, ma ha lo svantaggio di essere difficile da computare per grossi corpus di dati e che non ci sono informazioni relativi al contesto.
Nell'articolo Raggruppamento (clustering) di testi con TF-IDF utilizzo il modello TF-IDF, che nasce sempre dal BoW model, per applicare una tecnica di clustering chiamata KMeans. Questo modello è più complesso del bag of words, ma il clustering sarebbe stato possibile anche con quest'ultimo.
Il BoW model è un modello fondamentale, che permette la creazione di tanti altri modelli più complessi, come il TF-IDF o i modelli multinomiali, che tratteremo in articoli futuri.





Commenti dalla community