
Spesso i junior del data science si concentrano sul funzionamento di librerie come Scikit-Learn, Numpy e Pandas. Parecchi MOOC presenti online premono molto su concetti che girano intorno a questi ultimi, tralasciando la componente gestionale di un progetto di data science.
Per quanto un junior possa saperne di algoritmi, librerie e programmazione in generale, il successo di un progetto è anche legato alla sua struttura.
Una struttura confusionaria può impattare significativamente sulle performance dell'analista, che deve orientarsi continuamente tra il mare-magnum di file e TO-DOs. Questo è ancora più enfatizzato se nel progetto sono coinvolte più persone.
In questo articolo vi condividerò il mio boilerplate per la strutturazione di progetti di data science. Questa organizzazione prende spunto dal lavoro di Abhishek Thakur (@abhi1thakur), noto Grandmaster di Kaggle, dal suo libro Approaching Almost Any Machine Learning Problem (lettura molto consigliata).
Mentre molti data scientist utilizzano Jupyter per lavorare ai loro progetti, noi useremo un IDE come VSCode oppure PyCharm. Jupyter e i suoi notebook verranno usati solamente per l'analisi esplorativa e la generazione di grafici. In questo modo possiamo focalizzarci sul creare un template che definiamo plug & play in quanto con piccole modifiche potrà essere adattato a qualsiasi problema di data science.
Struttura del progetto
Vediamo la struttura dei file e delle cartelle. Creiamo una cartella con il nome del nostro progetto - nel nostro caso la chiameremo progetto. In progetto, avremo questa struttura:
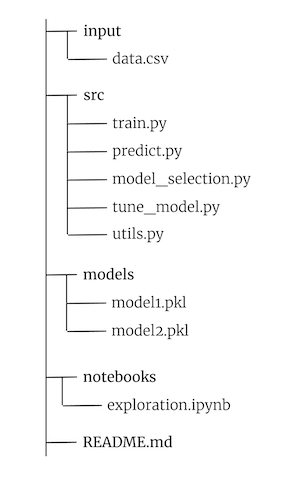
La cartella input conterrà i file di sorgente dati e materiale relativo al dataset del progetto.
La cartella src (source in inglese) conterrà invece tutti i file di lavoro vero e proprio.
- train.py: lo script che si preoccuperà di addestrare il modello scelto da tune_model.py. Restituirà un modello salvato su disco in formato pickle.
- predict.py: è lo script da chiamare per effettuare una predizione con il modello generato da train.py
- model_selection.py: in questo script inseriremo il codice che andrà a darci un riferimento per il modello più performante per il nostro dataset.
- tune_model.py: servirà a passare il risultato di model_selection.py alla pipeline di ottimizzazione degli iperparametri
- utils.py: conterrà tutte le nostre funzioni helper che ci serviranno durante il progetto
La cartella models conterrà i modelli che salveremo restituiti da train.py in formato pickle.
Notebooks sarà il nostro ambiente di esplorazione dove inseriremo tutti i nostri notebook .ipynb.
README.md invece sarà il nostro "manuale di istruzioni" - qui inseriremo la documentazione necessaria per comunicare il comportamento del nostro software.
Come approcciarsi all'utilizzo del boilerplate
Tipicamente inizio un progetto di data science / ML creando il file README.md. È di fondamentale importanza usare quest'ultimo per documentare ogni step del nostro processo.
Nelle fasi iniziali lo uso come raccoglitore di idee, partendo da un brainstorming, e poi pian piano vado a scremarlo, giungendo alla fine ad avere una documentazione semplice ma dritta al punto.
In parallelo o subito dopo passo ai notebook. Qui esploro il dato e cerco di capire se ci sono particolari condizioni a cui fare attenzione (valori mancanti, pattern particolari, presenza di outlier, e così via).
All'interno del notebook stesso mi dedico sempre delle celle tra i vari snippet di codice per commentare o creare del markdown esplicativo di quello che sto facendo. Inizio a riempire il file utils.py con le varie funzioni che so che mi aiuteranno a livello di script.
Quando sento di aver preso confidenza con il dataset passo a model_selection.py per testare baseline e trovare il modello più performante (leggere questo articolo per la metodologia di scelta del modello).
tune_model.py è strettamente legato a model_selection.py, in quanto il modello selezionato viene fornito direttamente ad una pipeline di ottimizzazione degli iperparametri, spesso effettuata con GridSearchCV oppure con Optuna.
Da qui poi è semplice - train.py si occupa di addestrare il modello ottimizzato e di valutarne la performance, predict.py viene invece chiamato per fare inferenze.
Con questo boilerplate avrete un punto di partenza per strutturare i vostri progetti di data science. Sentitevi liberi di espandere e di modificare la logica di questa struttura per adeguarla alle vostre esigenze.





Commenti dalla community