
La domanda sembra scontata: la maggior parte degli internauti conosce ChatGPT e cosa fa, ma molto meno sanno cosa sia a livello tecnico.
Questo articolo vuole rispondere alla domanda generica "cosa è ChatGPT?" andando ad alimentare una argomentazione tecnica degli strati di machine / deep learning che sono alla base del suo funzionamento.
L'obiettivo è fornire una panoramica generale della tecnologia che sta sconvolgendo l'internet, andando dal generale al particolare. Questa introduzione quindi coprirà prima ad ampio raggio cosa sia ChatGPT, ma poi andremo a fare un deep dive tecnico proprio nelle componenti che lo rendono utile come è.
Questa guida ti dirà anche cosa non è ChatGPT e cosa è possibile fare e non fare attraverso il chatbot.
Parleremo della sua genesi, la sua architettura programmatica descrivendo a larghe linee il modello che ha iniziato tutto chiamato transformer, come è stato addestrato ChatGPT e le limitazioni tecniche che sappiamo interessarlo. Infine chiuderemo l'articolo con alcuni consigli per utilizzare meglio il bot conversazionale di OpenAI.
- La genesi di ChatGPT
- Cosa è il modello transformer
- Com'è stato addestrato ChatGPT
- I limiti tecnici di ChatGPT
- Consigli all'utilizzo e prompt engineering
Tutto questo ti porterà ad avere una idea chiara di cosa sia ChatGPT e una intuizione dei blocchi architetturali che sono alla sua base.
Iniziamo.
Introduzione leggera alla genesi di ChatGPT
Per contestualizzare quello che segue, è bene dedicare un piccolo spazio alla storia di ChatGPT andando a menzionare i modelli che lo hanno preceduto.
Creati tutti da OpenAI nell'ormai lontano 2018, i Generative Pre-trained Transformers hanno creato una ondata di innovazione tecnologica praticamente senza pari.
Tutti questi, ChatGPT compreso, si basano sull'architettura transformer, una rete neurale altamente efficiente nell'elaborare dati testuali (se è la prima volta che senti nominare i transformer nel contesto del machine learning ti tolgo subito un dubbio: non hanno niente a che vedere con i film 😄).

È proprio grazie a questa architettura che oggi siamo in grado di beneficiare di strumenti come ChatGPT e vari modelli come BERT, GPT-2 e GPT-3 e tanti altri. Infatti, ChatGPT si basa quasi completamente sull'architettura transformer, con solo alcune piccole differenze.
Questo sviluppo ha portato all'emergere di modelli linguistici di grandi dimensioni (i famigerati LLM, large language models) come BERT nel 2018.
Sempre in quel periodo OpenAI pubblicò il suo articolo intitolato Improving Language Understanding by Generative Pre-Training, in cui introduceva il primo sistema di trasformatore generativo pre-addestrato (GPT-1).
Da qui OpenAI ha iniziato a lavorare constantemente al miglioramento dell'architettura GPT, con conseguente rilascio di versioni sempre migliori alla precedente.
Prima delle architetture basate su transformer, i modelli neurali di elaborazione linguistica più performanti utilizzavano comunemente l’apprendimento supervisionato da grandi quantità di dati etichettati manualmente.
Questo significa che per ogni riga di testo, c'era un umano che manualmente comunicava alla macchina quale fosse la corretta risposta per un determinato task.
La dipendenza dall'apprendimento supervisionato ne limitava l'uso su set di dati che non erano ben annotati e rendeva anche proibitivamente costoso e dispendioso in termini di tempo l'addestramento di modelli linguistici estremamente grandi.
Se alcuni termini ti sembrano troppo specifici, ti consiglio di dare una lettura all'articolo introduttivo al machine learning, che ti spiega in dettaglio cosa è l'apprendimento supervisionato (nonché altri tipi).
 Andrea D’Agostino
Andrea D’Agostino
Di conseguenza, OpenAI ha pensato introdurre una strategia di apprendimento semi-supervisionata, riducendo l'utilizzo della figura umana nel processo di addestramento.
Il processo era diviso in due fasi:
- Il modello veniva prima esposto a grosse quantità di dati linguistici non etichettati, in modo tale da fargli apprendere la struttura della lingua target (ad esempio, la probabilità che dopo la sequenza gatt seguisse la lettera a con una certa percentuale). In questa fase, l'umano non era parte del processo
- Nella seconda fase, l'umano entrava in gioco in una fase di fine-tuning, cioè mostrare al modello i completamenti più "umani" possibili a certe sequenze di testo
Un anno dopo, nel 2019, fu rilasciato GPT-2 che non era altro che un miglioramento dal punto di vista parametrico (cioè quantità di testo processato e connessioni neurali create) rispetto alla release precedente.
Il pubblico iniziò a toccare con mano il lavoro di OpenAI solo nel 2020, con il rilascio di quattro modelli fondamentali: ada, babbage, curie, e davinci.
Questi quattro modelli sono infatti tre declinazioni di GPT-3, ognuno di "potenza" crescente.
Davinci porta con sé anche la variante instruct, cioè una versione del modello refinito con l'aiuto di istruzioni umane.
Apprendimento dalle preferenze umane
L'inserimento della componente umana nell'addestramento non supervisionato dei GPT ha dato grande vantaggio a OpenAI per la creazione di modelli che rispondessero in maniera simile ad un umano ad una determinata query.
Nel paper Deep reinforcement learning from human preferences OpenAI esplora l'apprendimento per rinforzo dal feedback umano (reinforcement learning human feedback, RLHF), una tecnica che addestra un "modello di ricompensa" direttamente dal feedback umano.
Senza entrare nel dettaglio, RLHF migliora la robustezza e l'esplorazione degli agenti di apprendimento per rinforzo - questo permette ai modelli GPT di creare output molto simili a quelli umani, permettendo quindi la conversazione.
L'avvento di ChatGPT
ChatGPT viene rilasciato per la prima volta circa un anno prima della scrittura di questo articolo, a Novembre 2022. La sua prima release vedeva ChatGPT basarsi completamente su text-davinci-003.
Al tempo, text-davinci-003 era il modello più nuovo e più capace, progettato specificamente per attività basate su istruzioni. Ciò gli consentiva di rispondere in modo conciso e più accurato, anche in scenari zero-shot cioè senza la necessità di esempi forniti nel prompt.
La tecnica RLHF ha aiutato molto l'azienda a staccarsi dalla competizione e ad avere il boom che sta avendo online.
Al momento della scrittura di questo articolo, ChatGPT offre il piano Plus e Enterprise, che permette agli utenti abilitati di sfruttare GPT-4, il primo modello di OpenAI con funzionalità multimodali (quindi non solo basati su testo, ma anche su immagini).
Panoramica del modello transformer
Per capire ChatGPT bisogna capire come funziona il modello transformer.
Andrebbe dedicato un intero articolo focalizzato solo sul transformer (e arriverà, ve lo prometto), ma per ora andremo a fare una panoramica tecnica della sua architettura e spiegare come funziona la sua proprietà più importante: il meccanismo di attenzione.
Introdotto per la prima volta nel 2017 nel paper Attention Is All You Need (Vaswani et al.) da Google, il transformer è stato inserito nel contesto dei modelli Sequence-to-Sequence (chiamati anche Seq2Seq), cioè nei modelli che data una sequenza di input, produce una sequenza di output.
I modelli Seq2Seq sono particolarmente adatti alla traduzione, in cui la sequenza di parole di una lingua viene mappata in una sequenza di parole diverse in un'altra lingua. Una scelta popolare per questo tipo di modello sono i modelli basati su memoria a breve termine (long-short term memory neural network, LSTM).
Con i dati dipendenti dalla sequenza, i modelli LSTM possono dare significato alla sequenza "ricordando" le parti che ritiene importanti. Le frasi, ad esempio, dipendono dalla sequenza poiché l'ordine delle parole è cruciale per comprendere la frase.
I modelli seq2seq sono comunemente costituiti da un codificatore (encoder) e un decodificatore (decoder).
L'encoder prende la sequenza di input e la mappa in uno spazio dimensionale superiore (vettore n-dimensionale). Quel vettore astratto viene immesso nel decodificatore che lo trasforma in una sequenza di output. La sequenza di output può essere in un'altra lingua, simboli, una copia dell'input, ecc.
Il codificatore e il decodificatore hanno in comune lo spazio n-dimensionale, nel senso che entrambi sono in grado di astrarre da quello stesso spazio. Questo permette al codificatore di proiettare l'input nello spazio dimensionale, mentre al decodificatore permette di leggere da quello spazio dimensionale e mappare quei valori ad una sequenza di output.
Inizialmente, né il codificatore né il decodificatore hanno conoscenza dello spazio n-dimensionale. Per impararlo, vengono di fatto addestrati.
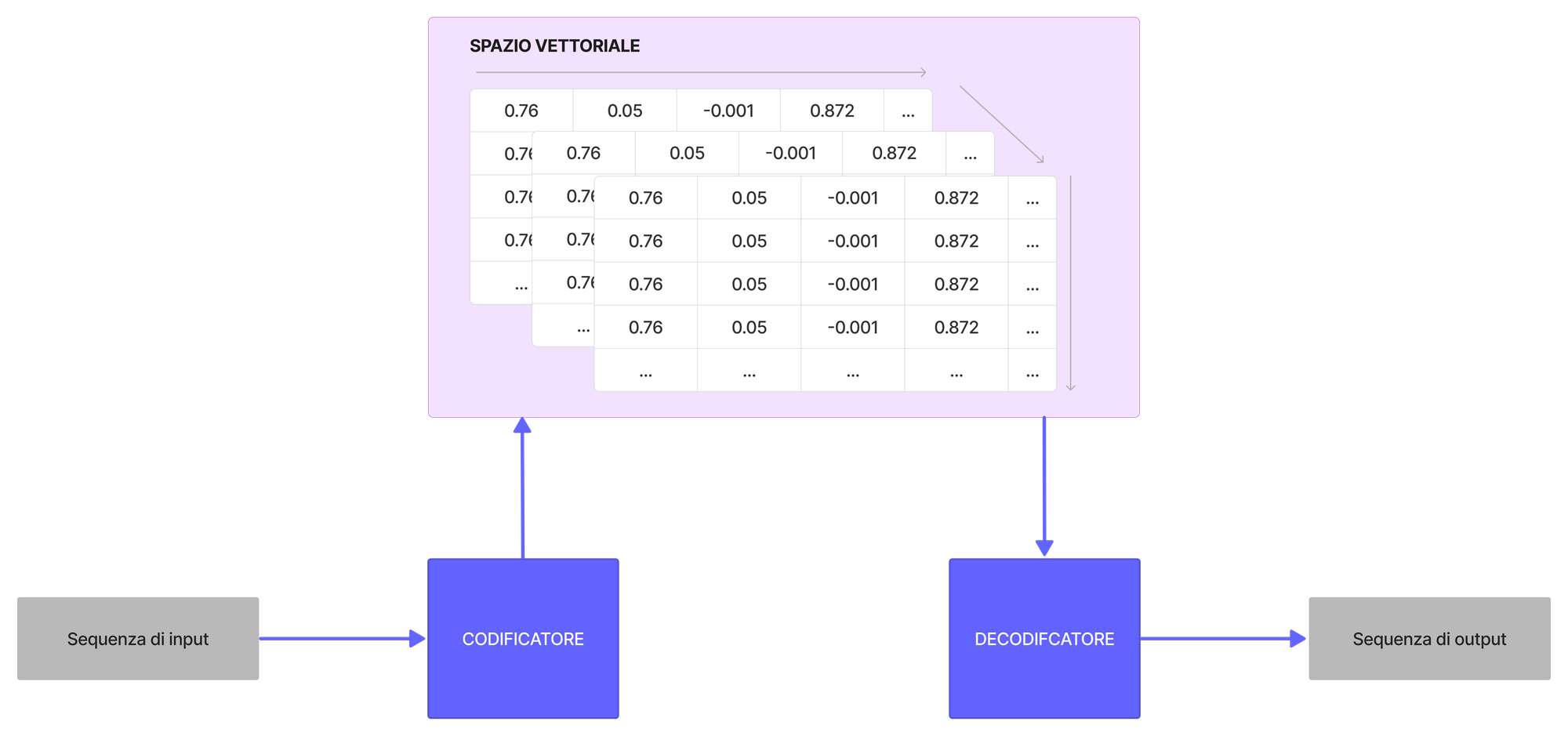
Ora andremo ad esplorare l'anatomia e l'architettura del modello al fine di comprendere come funzionano encoder e decoder.
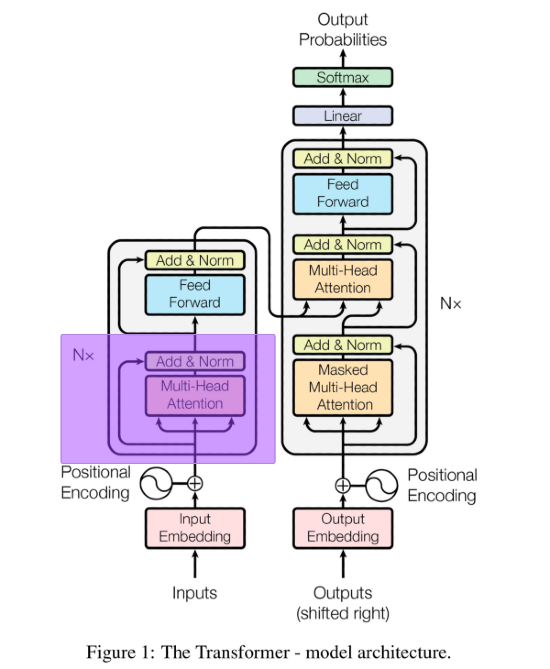
Anatomia e architettura del transformer
L'architettura del transformer è presente nell'immagine in basso. Prenditi un minuto per esaminarla a livello visivo prima di andare nel tecnico. Cercherò di spiegare al meglio delle mie possibilità i seguenti componenti:
- Blocco di input embedding
- Encoding posizionale
- Encoder
- Attenzione multi-head
- Decoder
- Attenzione multi-head mascherata
- Strato softmax di output
Per chiarezza, ecco una immagine della architettura del transformer presa dal paper:
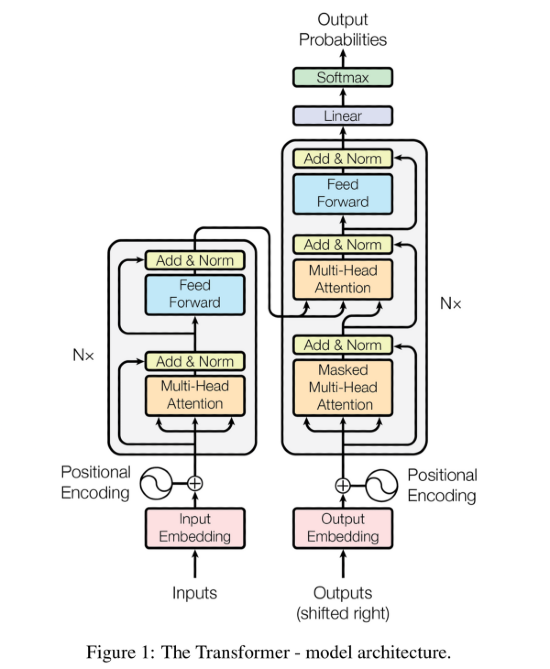
Un transformer, per essere addestrato, deve ricevere testo in input e testo come output. Nel blocco di encoding (quello a sinistra), vengono passate le nostre feature (quindi il testo in input). Nel decoder (quello a destra) vengono passate le sequenze di output (quindi il testo che deve restituire il transformer).
Partiamo spiegando il blocco di input embedding.
Input embedding del transformer
Ho già parlato più volte in questo blog di rappresentazioni vettoriali nel machine learning - gli embedding (traducibili in italiano con il termine incorporamenti) sono solo alcune delle più complesse di queste rappresentazioni che oggi sono alla base del deep learning (proprio grazie al loro utilizzo nel modello transformer).
Per riferimento, ecco la parte alla quale mi sto riferendo
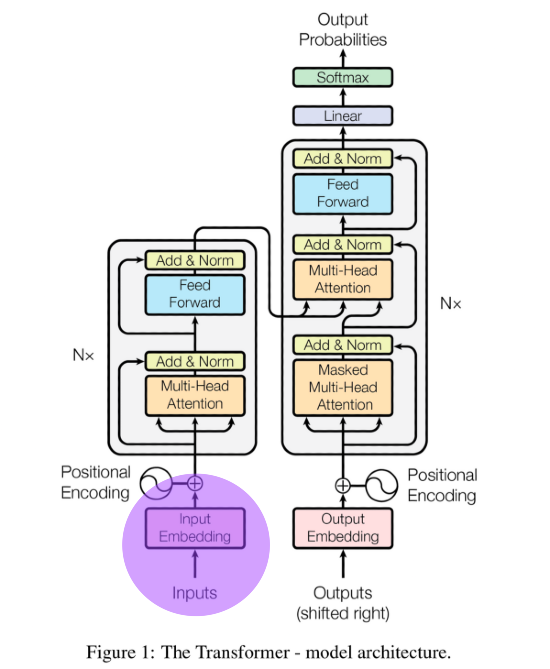
I computer non possono processare stringhe testuali. Queste devono essere convertite in numeri, vettori, matrici - gli incorporamenti servono proprio a questo.
Parole relazionate tra loro dovrebbero apparire vicine in un spazio vettoriale, mentre parole non relazionate tra loro dovrebbero apparire lontane.
Riferiamoci a questa immagine:
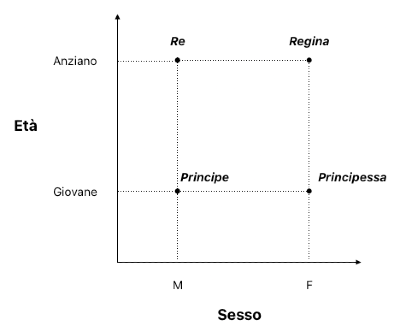
Vediamo come le parole "principe" e "principessa" siano vicine tra di loro, proprio come come "re" e "regina".
Ponendo che la variabile genere possa assumere solo due valori, M e F (usiamo 0 e 1), e che la variabile età possa assumere solo tre valori [Giovane, Mezz’età, Anziano] (usiamo 0, 1, 2), vediamo come degli embedding possano rappresentare queste relazioni in maniera accurata in uno spazio bidimensionale.
Questa rappresentazione riesce a catturare lo status nobiliare di un individuo andando a usare le dimensioni di genere e l’età.
Muovendoci sull’asse delle X possiamo osservare come i due nobili siano equidistanti da una dimensione che rappresenta la differenza di genere (0: maschio, 1: femmina). Muovendoci sull’asse delle Y invece, possiamo osservare come l’età sia rappresentato dalla distanza dell’embedding dall’asse Y.
Nel machine learning, questi spazi vettoriali possono essere appresi oppure usati in nuovi modelli, sfruttando il transfer learning o pretraining. Una rete neurale quindi, può sfruttare lo spazio vettoriale di un altro modello che ha precedentemente appreso le relazioni tra parole e usare tali relazioni per un task nuovo.
Nel transformer, il meccanismo di embedding non è diverso, tranne per il fatto che viene arricchito con un encoding posizionale.
Encoding posizionale del transformer
Nella rete neurale del transformer, l'encoding posizionale è evidenziato come nell'immagine qui sotto
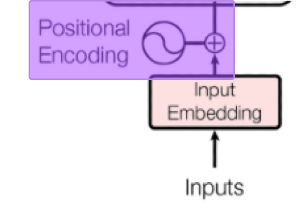
L'encoding posizionale aggiunge agli embedding testuali informazioni riguardo la posizione del token nell'input.
Concretamente parlando, questo è un vettore che contiene la posizione (e quindi distanze) delle parole in una frase.

Aggiungendo quindi le informazioni posizionali delle parole agli embedding testuali otteniamo degli embedding che contengono sia le relazioni semantiche tra le parole che informazioni contestuali presenti nella frase in input.
Meccanismo di attenzione del transformer
Plausibilmente la caratteristica che rende il transformer il modello rivoluzionario che è, il meccanismo dell'attenzione esamina una sequenza di input e decide ad ogni passaggio quali altre parti della sequenza sono importanti.
Nell'architettura, è evidenziato così, come primo componente del blocco encoder:
L'obiettivo del blocco di attenzione è quindi quello di selezionare le parti importanti di una frase, in base al suo significato e al suo contesto (facendo leva quindi sulle rappresentazioni vettoriali create dagli strati che lo precedono).
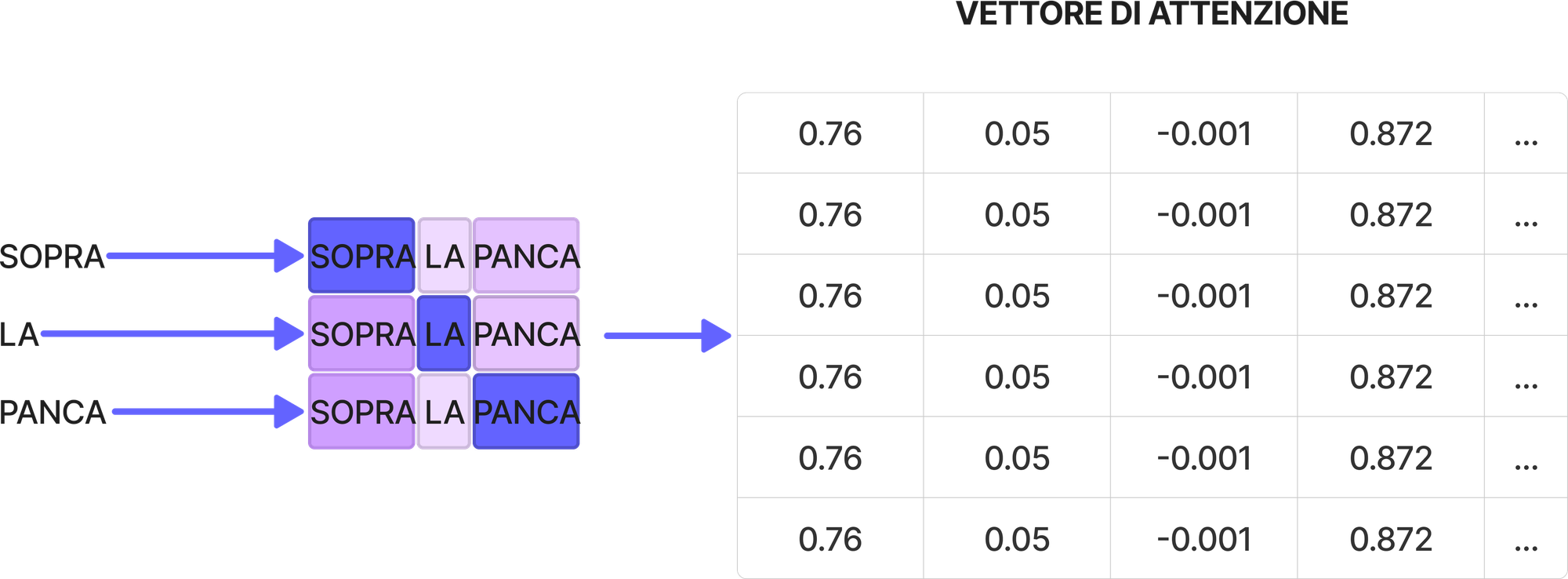
Il meccanismo di attenzione crea in output un vettore di attenzione per ogni parola all'interno della frase.
Nell'immagine in basso, il mio tentativo è quello di farti capire come, durante l'addestramento, il meccanismo di attenzione del transformer associa sempre più rilevanza alle parole sopra e panca. Questo perché processando grosse moli di dati è in grado di trovare le correlazioni rilevanti attraverso le informazioni semantiche e posizionali delle parole.
Ogni vettore passa parallelamente in nel blocco feed-forward, che non è altro che una rete neurale classica. Questo trasforma l'output del meccanismo di attenzione in una matrice di informazioni facilmente comprensibile per l'unità di decodifica.
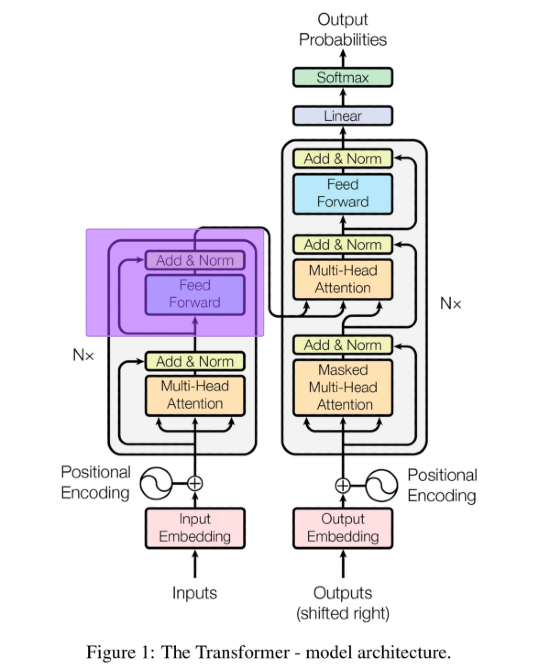
Meccanismo di attenzione mascherata del transformer
Nell'unità di decodifica, il blocco di embedding e codifica posizionale funzionano allo stesso modo come nel blocco di encoding. Il primo cambiamento fondamentale si nota con l'unità di attenzione mascherata.
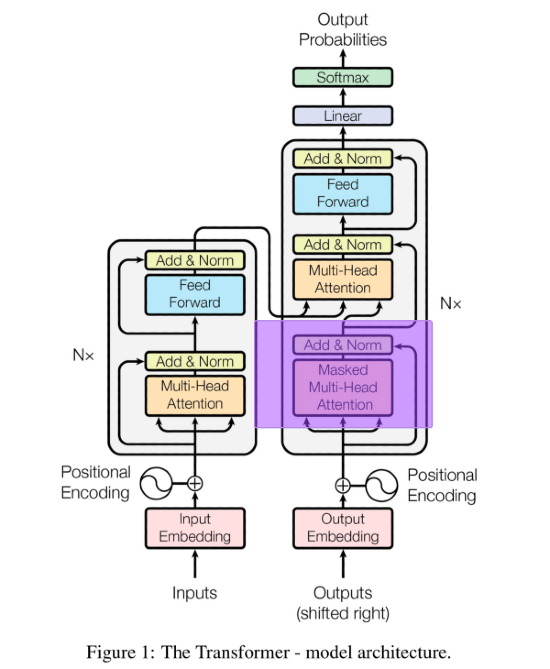
Ponendo che la sequenza di input sia sopra la panca e la sequenza di output sia la capra campa, per addestrare il transformer a predire la prossima parola dobbiamo andare a mascherare tutte le parole che seguono la parola di output, che in questo caso è "la". Se non facessimo ciò, il transformer non avrebbe nulla da imparare, in quanto la soluzione è già fornita dalla sequenza stessa.
A questo punto c'è un'altra unità di attenzione multi-head, chiamata anche attenzione encoder-decoder. Questa riceve input sia dal decodificatore che dal codificatore e il suo compito è quello di valutare entrambe le matrici di attenzione e comprendere le relazioni tra la sequenza di input e di output.
Questo è uno dei blocchi più importanti, perché permette al transformer di mappare input a output, comprendendo le relazioni tra token e quindi sequenze.
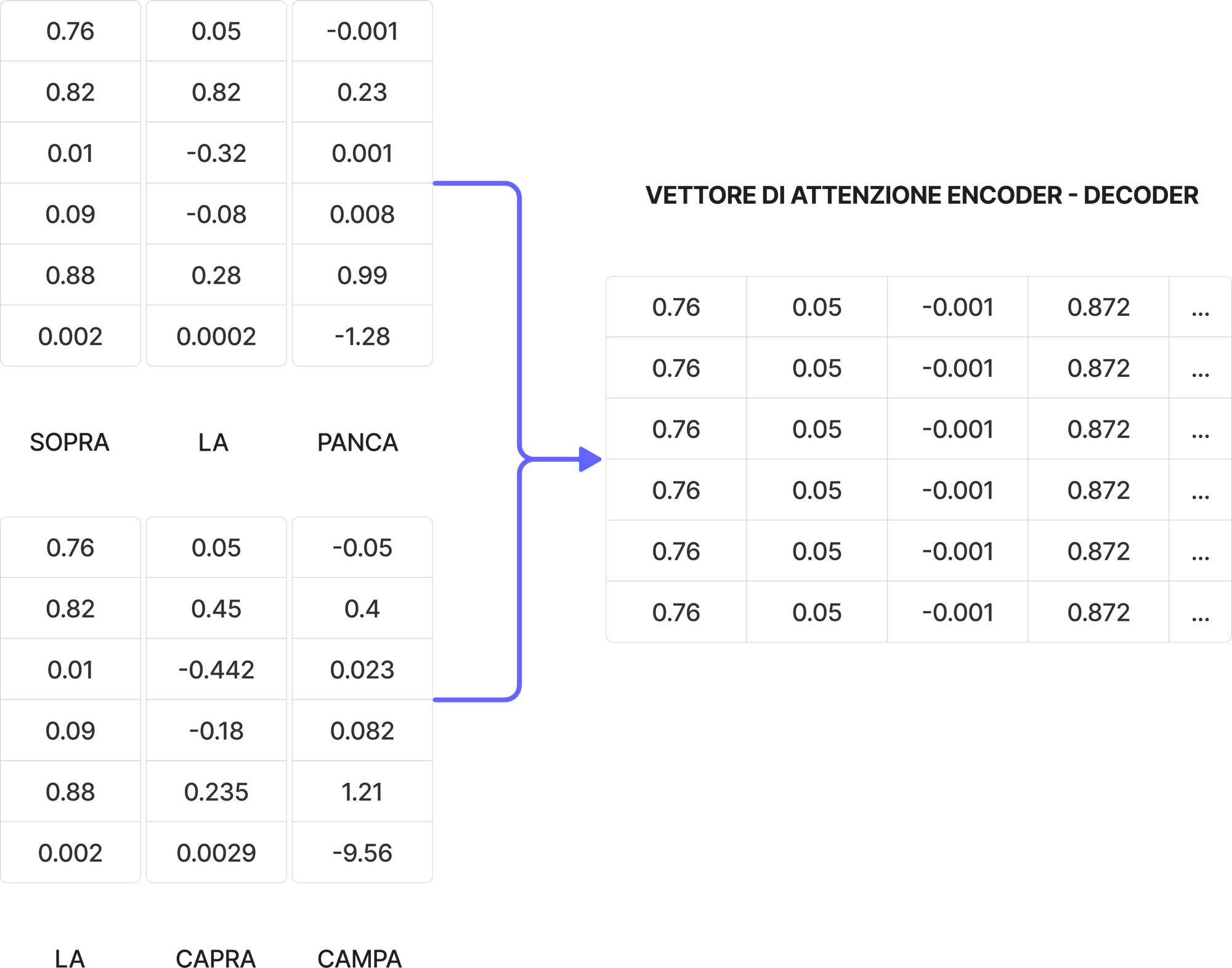
Questa ultima rappresentazione attentiva viene passata attraverso un'altra feedforward neural network, per poi essere trasformata linearmente dallo strato che precede la softmax. Poiché stiamo parlando di linguaggio, il numero di token da generare è tipicamente uguale al numero di vocaboli di quella lingua.
Funzione softmax del transformer
Per i non addetti ai lavori, la funzione softmax converte un vettore di \( K \) numeri reali in una distribuzione di probabilità di \( K \) possibili risultati la cui somma fa 1.
L'ultima parte del transformer sfrutta proprio la funzione softmax per restituire la distribuzione di probabilità di un token rispetto a tutti quelli presenti in addestramento.
Tra tutti i possibili token che il transformer può scegliere di restituire, la softmax permette di scegliere quello con la probabilità più alta di essere scelto.
Questo permette a qualsiasi software che legge l'output di un transformer di avere a disposizione la distribuzione di token, con relative percentuali.
Cosa eredita ChatGPT dal transformer?
Non abbiamo idea di quale sia l'architettura di ChatGPT, essendo fondato su GPT-3.5 e GPT-4. Questo perché OpenAI ha deciso (al momento) di non pubblicare tali informazioni al pubblico.
Partendo da GPT-1 però, possiamo dire che OpenAI ha usato parte dell'architettura transformer (in particolare solo il suo decoder) per addestrare il suo primo modello.
L'architettura GPT-1 è composta da architetture transformer decoder-only a dodici strati, ognuna con le sue meccaniche di attenzione mascherate.
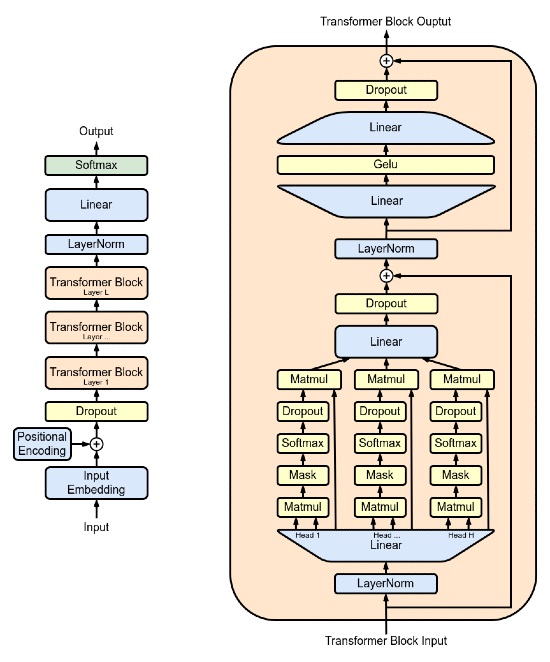
OpenAI ha apportato alcune piccole modifiche al componente decoder del transformer per permettere a GPT-1 si essere task-indepedent, cioè capace di risolvere problemi aperti, non specifici. Queste modifiche si vedono nell'inserimento di alcune componenti aggiuntive, come dropout e strati di attivazione GeLu.
L'immagine in basso, presa da Wikipedia EN, mostra le informazioni pubbliche a disposizione per comprendere la relazione transformer-GPT.
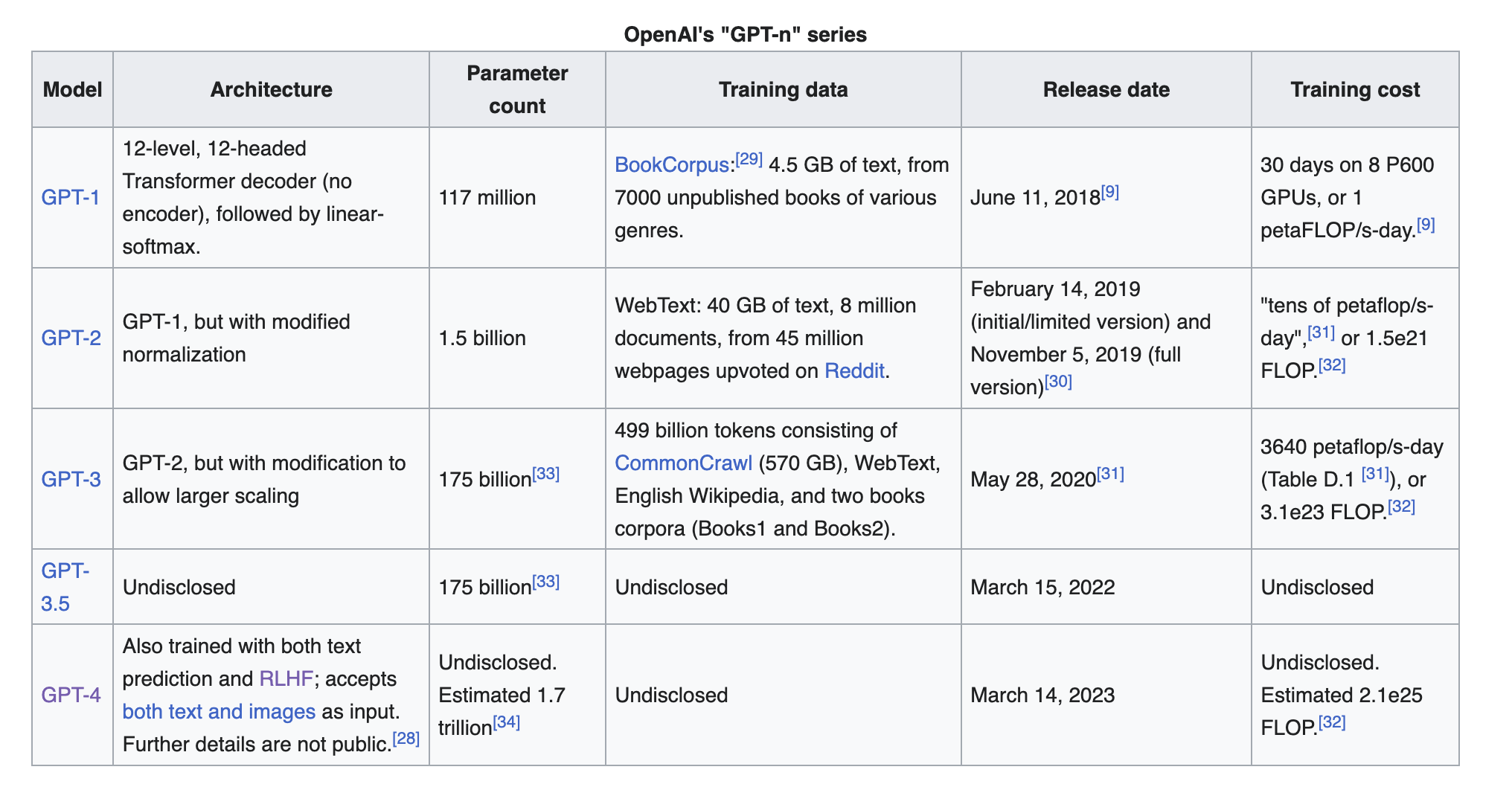
Essendo GPT-3 basato su poche modifiche rispetto alle versioni precedenti, è plausibile pensare che l'architettura decoder-only sia presente anche in GPT-3.5 e 4.
Com'è stato addestrato ChatGPT?
Come abbiamo appena visto, OpenAI non ha rilasciato i dettagli tecnici di GPT-4 - l'azienda si è astenuta esplicitamente dal specificare le dimensioni del modello, l'architettura o l'hardware utilizzato durante l'addestramento o l'inferenza.
Dal blog di OpenAI è possibile però comprendere diverse dinamiche attorno al suo addestramento.
ChatGPT è stato addestrato, come menzionato, utilizzando la tecnica RLHF. Il modello di partenza, (InstructGPT, probabilmente davinci-text-003) è stato sottoposto a fine-tuning supervistionato, dove l'umano forniva conversazioni dove interpretava sia il chatbot che l'umano stesso. Questo nuovo set di dati è stato poi mescolato con il set di dati originale di InstructGPT, che è stato poi trasformato in un formato di dialogo per addestrare il modello a conversare.
La componente di reinforcement learning entra in gioco quando si parla di modello di ricompensa, cioè un modello che seleziona la risposta migliore generata da un chatbot dato un prompt.
Per creare un modello di ricompensa, OpenAI ha raccolto dati di confronto, che consistevano in due o più risposte del modello classificate per qualità. Per raccogliere questi dati, sono state prese le conversazioni tra umani e chatbot dello step precedente, campionato casualmente delle risposte date dal modello e chiesto agli etichettatori di creare una classifica di qualità.
È stata usato l'algoritmo di reinforcement learning chiamato PPO (proximal policy optimization) per ottimizzare il modello.
Nell'immagine in basso il processo descritto da OpenAI per addestrare ChatGPT.

Quindi, secondo OpenAI, esiste un modello fine-tunato per la conversazione via chat, poi esiste un modello di ricompensa che è in grado di giudicare la bontà di una risposta del primo modello.
Ogni giudizio del modello di ricompensa aggiorna la politica dell'algoritmo di reinforcement learning attraverso PPO, il quale diventa quindi sempre più abile a trovare risposte adeguate dato un prompt in input a mano a mano che le iterazioni di training aumentano.
I parametri "nascosti" di ChatGPT
Ogni modello di machine learning ha dei parametri che possono essere modificati per alterare la qualità del suo risultato.
Guardare l'API di OpenAI per la chat ci permette di vedere come esistano una serie di parametri che possono alterare notevolmente le risposte di GPT-3.5 durante la conversazione.
Questi parametri non sono direttamente modificabili via interfaccia chat su chat.openai.com, ma se ci colleghiamo via API invece possono essere utilizzati senza problemi.
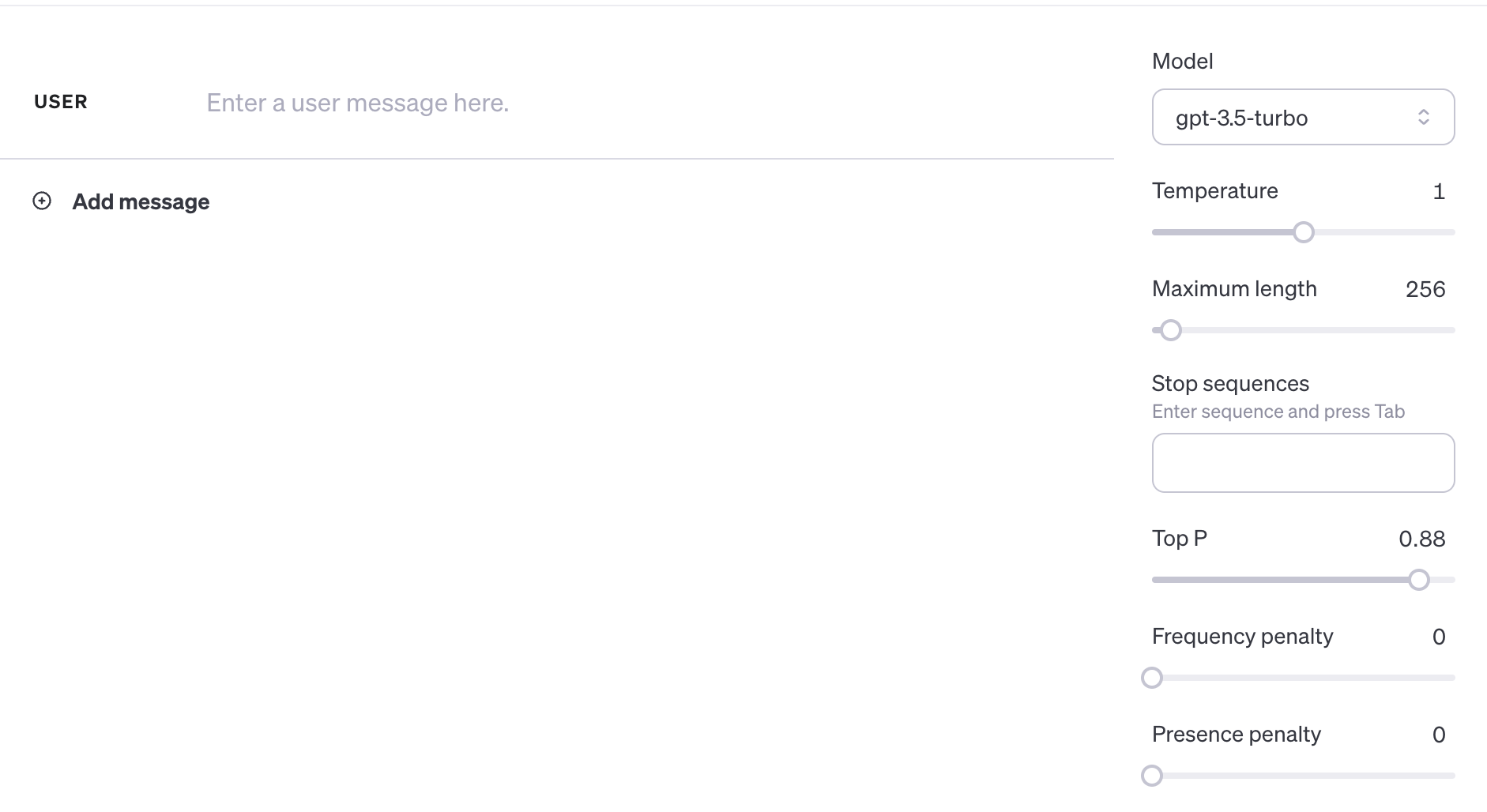
Esploriamo cosa sono e l'effetto che hanno sulla generazione dei token.
Temperatura
Regola l'imprevedibilità dell'output. Con temperature più elevate, gli output diventano più creativi e meno prevedibili poiché amplifica la probabilità di token meno probabili riducendo quella per quelli più probabili.
Maximum Length
Il numero massimo di token da generare tra prompt e completamento del testo.
Stop Sequences
La stop sequence è serie di stringhe che impediscono al modello di generare token. Specificare tali sequenze è un altro modo per controllare la lunghezza e la struttura della risposta del modello.
Top P
Parametro simile alla temperature, ma che agisce invece sul campionamento dei token da parte del modello.
Frequence Penalty
La frequence penalty applica una penalità sul token successivo proporzionale a quante volte quel token è già apparso nella risposta e nel prompt. Maggiore è la penalità di frequenza, minore è la probabilità che una parola appaia di nuovo. Questa impostazione riduce la ripetizione delle parole nella risposta del modello assegnando ai token che appaiono di più una penalità più elevata.
Presence Penalty
Applica anch'esso una penalità sui token ripetuti ma, a differenza della frequency penalty, la penalità è la stessa per tutti i token ripetuti. Questa impostazione impedisce al modello di ripetere le frasi troppo spesso nella sua risposta.
Teniamo a mente che l'interfaccia Chat di OpenAI permette di implementare ChatGPT nei nostri software.
I limiti tecnici di ChatGPT
Ecco una lista di limitazioni di ChatGPT pubblicate proprio da OpenAI nel suo blog:
- Il modello ha una finestra temporale fissa. Ad ogni update questa approccia la data odierna, ma tenderà ad avere sempre buchi conoscitivi riguardo gli eventi di cronaca
- Allucinazioni: esiste la possibilità che ChatGPT risponda in maniera plausibile, ma in maniera anche completamente errata. Questo accade perché fondamentalmente durante il training non è possibile verificare la veridicità di ogni affermazione e perché il modello è tarato per rifiutare completamente di rispondere ad alcune domande ostiche
- ChatGPT è prompt-sensitive, cioè date piccole modifiche del prompt umano può rispondere in maniera diversa
- Eccessivamente verboso, con stile e tono riconoscibile. Questo è dovuto proprio ai bias degli etichettatori in fase di training
- Fa salti pindarici ingiustificatamente - sempre a causa di bias durante il training, se ChatGPT non "capisce" bene la domanda dell'umano, tende il più delle volte a rispondere e non a chiedere chiarimenti
E ovviamente...i bug. Da poco è stato infatti identificato e risolto un grave bug di ChatGPT, dove se si chiedeva di ripetere all'infinito una parola ad un certo punto il modello iniziava a restituire informazioni private di individui o aziende.
Consigli all'utilizzo e Prompt Engineering
Impossibile non scrivere di prompt engineering in un articolo incentrato su ChatGPT.
Non andrò nel dettaglio del prompt engineering perché ho già scritto un pezzo dedicato ai metodi più efficaci che puoi trovare qui 👇
Andrea D’Agostino
Voglio invece darti un consiglio molto utile per rendere le tue interazioni con ChatGPT più produttive e precise.
Si tratta di implementare le custom instructions - istruzioni che alterano completamente il comportamento del bot durante la conversazione.
Il repository chiamato AutoExpert mette a disposizione delle custom instruction che cambiano radicalmente le risposte di ChatGPT, migliorandole nettamente facendo interpretare al bot la posizione di un esperto in maniera automatica.
Ogni volta che facciamo una domanda, questo risponderà in maniera sempre coerente e precisa, seguendo una scaletta logica definita all'interno delle istruzioni.
Nello screenshot in basso, un esempio di risposta. Quel template, come menzionato, sarà propagato per ogni domanda che facciamo a GPT, senza bisogno di duplicare il "framing" della domanda.

Puoi trovare il repository Git e relative istruzioni all'installazione (è semplicissimo), qui 👇
 spdustin
spdustinConclusioni
Spero che questo articolo abbia gettato le basi intuitive di cosa sia veramente ChatGPT dal punto di vista tecnico.
Questa panoramica non ha l'obiettivo di sostituire un paper scientifico oppure di fornire le intuizioni informatiche, matematiche e di design dietro a ChatGPT, anche perché non le conosciamo precisamente e non sarei nemmeno in grado.
Riassumendo, hai imparato
- come siamo arrivati a ChatGPT, andando ad esplorare i primi modelli GPT
- la spina dorsale del NLP moderno: il modello transformer
- le informazioni a disposizione riguardo l'addestramento e il funzionamento di ChatGPT dal punto di vista tecnico
- alcuni consigli su come migliorare la tua interazione con ChatGPT attraverso le custom instruction e il prompt engineering
Cercherò di tenere aggiornato questo articolo ad ogni aggiornamento significativo di ChatGPT oppure a release nuove degne di nota da parte di OpenAI.
Alla prossima,





Commenti dalla community