
Di recente mi sono trovato a lavorare su attività di estrazione di parole chiave. L'obiettivo era trovare un algoritmo in modo efficiente, bilanciando la qualità dell'estrazione e il tempo di esecuzione, poiché il mio corpus di dati stava aumentando raggiungendo rapidamente milioni di righe. Uno dei KPI era estrarre parole chiave che avevano sempre senso da sole anche contesto.
Ciò mi ha portato a testare e sperimentare diversi meccanismi di estrazione conosciuti nell'ambiente. Eccomi condividere con voi il mio piccolo viaggio.
Le Librerie
Ho utilizzato le seguenti librerie per condurre lo studio
- NLTK, per aiutarmi nelle fasi di preprocessing e per alcune funzioni di helper
- RAKE
- YAKE
- PKE
- KeyBERT
- Spacy
Sono stati utilizzati anche Pandas e Matplotlib, insieme ad altre librerie fondamentali.
Struttura dell'Esperimento
Il modo in cui funziona il benchmark è il seguente

Per prima cosa importeremo il set di dati che contiene i nostri dati testuali. Creeremo quindi funzioni separate che applicano la logica di estrazione
__nome_algoritmo__(str: testo) → [keyword1, keyword2, …, keywordn]
Quindi creeremo una funzione che applica il meccanismo di estrazione all'intero corpus.
extract_keywords_from_corpus(algoritmo, corpus) → {algoritmo, keyword_del_corpus, tempo_impiegato}
Spacy ci aiuterà a definire un oggetto matcher che restituirà True o False se una parola chiave corrisponde a un modello sintattico che abbia senso per il nostro compito.
Infine raggrupperemo tutto in una funzione che emette il nostro rapporto finale.
Il Dataset
Il dataset contiene dei testi brevi presi online da diverse risorse, in lingua inglese. Ecco un esempio
['To follow up from my previous questions. . Here is the result!\n',
'European mead competitions?\nI’d love some feedback on my mead, but entering the Mazer Cup isn’t an option for me, since shipping alcohol to the USA from Europe is illegal. (I know I probably wouldn’t get caught/prosecuted, but any kind of official record of an issue could screw up my upcoming citizenship application and I’m not willing to risk that).\n\nAre there any European mead comps out there? Or at least large beer comps that accept entries in the mead categories and are likely to have experienced mead judges?',
'Orange Rosemary Booch\n',
'Well folks, finally happened. Went on vacation and came home to mold.\n',
'I’m opening a gelato shop in London on Friday so we’ve been up non-stop practicing flavors - here’s one of our most recent attempts!\n',
"Does anyone have resources for creating shelf stable hot sauce? Ferment and then water or pressure can?\nI have dozens of fresh peppers I want to use to make hot sauce, but the eventual goal is to customize a recipe and send it to my buddies across the States. I believe canning would be the best way to do this, but I'm not finding a lot of details on it. Any advice?",
'what is the practical difference between a wine filter and a water filter?\nwondering if you could use either',
'What is the best custard base?\nDoes someone have a recipe that tastes similar to Culver’s frozen custard?',
'Mold?\n']
Per lo più sono articoli legati al cibo. Prenderemo un campione di 2000 documenti per testare i nostri algoritmi. Non andremo ancora a fare preprocessing sui nostri testi perché alcuni algoritmi basano i loro risultati sulla presenza di stopword e punteggiatura.
Gli Algoritmi
Definiamo le funzioni di estrazione keyword
# inizializziamo BERT fuori dalle funzioni
bert = KeyBERT()
# 1. RAKE
def rake_extractor(text):
r = Rake()
r.extract_keywords_from_text(text)
return r.get_ranked_phrases()[:5]
# 2. YAKE
def yake_extractor(text):
keywords = yake.KeywordExtractor(lan="en", n=3, windowsSize=3, top=5).extract_keywords(text)
results = []
for scored_keywords in keywords:
for keyword in scored_keywords:
if isinstance(keyword, str):
results.append(keyword)
return results
# 3. PositionRank
def position_rank_extractor(text):
# definiamo i pattern grammaticali da considerare
pos = {'NOUN', 'PROPN', 'ADJ', 'ADV'}
extractor = pke.unsupervised.PositionRank()
extractor.load_document(text, language='en')
extractor.candidate_selection(pos=pos, maximum_word_number=5)
extractor.candidate_weighting(window=3, pos=pos)
# selezioniamo le top 5 keyword
keyphrases = extractor.get_n_best(n=5)
results = []
for scored_keywords in keyphrases:
for keyword in scored_keywords:
if isinstance(keyword, str):
results.append(keyword)
return results
# 4. SingleRank
def single_rank_extractor(text):
pos = {'NOUN', 'PROPN', 'ADJ', 'ADV'}
extractor = pke.unsupervised.SingleRank()
extractor.load_document(text, language='en')
extractor.candidate_selection(pos=pos)
extractor.candidate_weighting(window=3, pos=pos)
keyphrases = extractor.get_n_best(n=5)
results = []
for scored_keywords in keyphrases:
for keyword in scored_keywords:
if isinstance(keyword, str):
results.append(keyword)
return results
# 5. MultipartiteRank
def multipartite_rank_extractor(text):
extractor = pke.unsupervised.MultipartiteRank()
extractor.load_document(text, language='en')
pos = {'NOUN', 'PROPN', 'ADJ', 'ADV'}
extractor.candidate_selection(pos=pos)
extractor.candidate_weighting(alpha=1.1, threshold=0.74, method='average')
keyphrases = extractor.get_n_best(n=5)
results = []
for scored_keywords in keyphrases:
for keyword in scored_keywords:
if isinstance(keyword, str):
results.append(keyword)
return results
# 6. TopicRank
def topic_rank_extractor(text):
extractor = pke.unsupervised.TopicRank()
extractor.load_document(text, language='en')
pos = {'NOUN', 'PROPN', 'ADJ', 'ADV'}
extractor.candidate_selection(pos=pos)
extractor.candidate_weighting()
keyphrases = extractor.get_n_best(n=5)
results = []
for scored_keywords in keyphrases:
for keyword in scored_keywords:
if isinstance(keyword, str):
results.append(keyword)
return results
# 7. KeyBERT
def keybert_extractor(text):
keywords = bert.extract_keywords(text, keyphrase_ngram_range=(3, 5), stop_words="english", top_n=5)
results = []
for scored_keywords in keywords:
for keyword in scored_keywords:
if isinstance(keyword, str):
results.append(keyword)
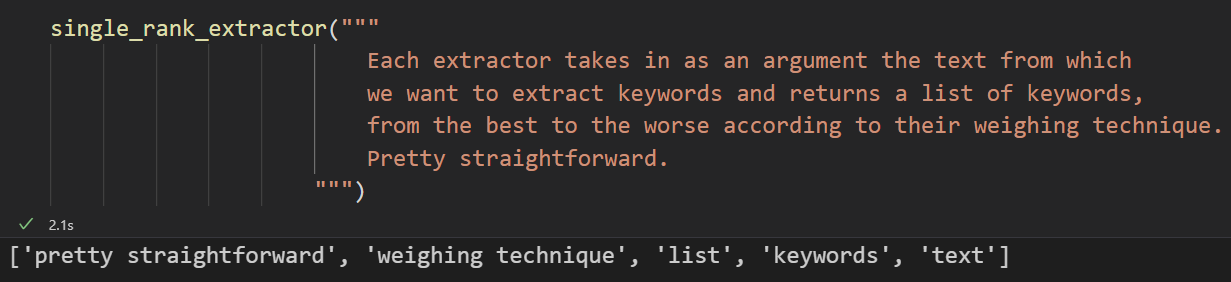
return results Ogni estrattore prende come argomento il testo da cui vogliamo estrarre le parole chiave e restituisce un elenco di parole chiave, dalla migliore alla peggiore in base alla loro tecnica estrazione.
Nota: per qualche motivo, non ho potuto inizializzare tutti gli oggetti estrattore al di fuori delle funzioni. TopicRank e MultiPartiteRank generavano errori ogni volta che lo facevo. Questo inficia un po' sulle performance, ma il benchmark può essere fatto comunque.
Stiamo già limitando alcuni dei modelli grammaticali accettati passando pos = {'NOUN', 'PROPN', 'ADJ', 'ADV'} (nome, nomi propri, aggettivi e avverbi) — questo, insieme a Spacy, assicurerà che quasi tutte le parole chiave siano sensate da un prospettiva del linguaggio umano.
Vogliamo anche che le parole chiave siano almeno trigrammi, solo per avere parole chiave più specifiche. Invito a controllare la documentazione delle librerie per approfondire i parametri e come funzionano.
Estrarre le keyword dall'intero corpus
Definiamo ora una funzione che applicherà un singolo estrattore all'intero corpus insieme ad alcune informazioni utili.
def extract_keywords_from_corpus(extractor, corpus):
"""Questa funzione usa un estrattore per estrarre le keyword da una lista di documenti"""
extractor_name = extractor.__name__.replace("_extractor", "")
logging.info(f"Starting keyword extraction with {extractor_name}")
corpus_kws = {}
start = time.time()
# logging.info(f"Timer initiated.") <-- rimuovere il commento per loggare quando inizia il timer
for idx, text in tqdm(enumerate(corpus), desc="Extracting keywords from corpus..."):
corpus_kws[idx] = extractor(text)
end = time.time()
# logging.info(f"Timer stopped.") <-- rimuovere il commento per loggare quando si ferma il timer
elapsed = time.strftime("%H:%M:%S", time.gmtime(end - start))
logging.info(f"Time elapsed: {elapsed}")
return {"algorithm": extractor.__name__,
"corpus_kws": corpus_kws,
"elapsed_time": elapsed}Tutto ciò che fa questa funzione è popolare un dizionario con i dati provenienti dall'estrattore passati come argomento e una serie di informazioni utili come il tempo impiegato per eseguire l'attività.
È qui che ci assicuriamo che le parole chiave restituite dagli estrattori abbiano sempre (quasi?) un senso. Ad esempio,

Vediamo come le prime tre parole chiave abbiano senso fuori da qualsiasi contesto. Hanno un significato e sono del tutto sensate. Qualcosa quando usciamo, non ha senso perché abbiamo bisogno di più informazioni per comprendere il significato di quel blocco di dati. Vogliamo evitare questo.
Spacy ci aiuta con l'oggetto Matcher. Definiremo una funzione di corrispondenza che accetta una parola chiave e restituisce True o False se i modelli definiti corrispondono.
def match(keyword):
"""Questa funzione controlla se un elenco di parole chiave corrisponde a un determinato modello grammaticale"""
patterns = [
[{'POS': 'PROPN'}, {'POS': 'VERB'}, {'POS': 'VERB'}],
[{'POS': 'NOUN'}, {'POS': 'VERB'}, {'POS': 'NOUN'}],
[{'POS': 'VERB'}, {'POS': 'NOUN'}],
[{'POS': 'ADJ'}, {'POS': 'ADJ'}, {'POS': 'NOUN'}],
[{'POS': 'NOUN'}, {'POS': 'VERB'}],
[{'POS': 'PROPN'}, {'POS': 'PROPN'}, {'POS': 'PROPN'}],
[{'POS': 'PROPN'}, {'POS': 'PROPN'}, {'POS': 'NOUN'}],
[{'POS': 'ADJ'}, {'POS': 'NOUN'}],
[{'POS': 'ADJ'}, {'POS': 'NOUN'}, {'POS': 'NOUN'}, {'POS': 'NOUN'}],
[{'POS': 'PROPN'}, {'POS': 'PROPN'}, {'POS': 'PROPN'}, {'POS': 'ADV'}, {'POS': 'PROPN'}],
[{'POS': 'PROPN'}, {'POS': 'PROPN'}, {'POS': 'PROPN'}, {'POS': 'VERB'}],
[{'POS': 'PROPN'}, {'POS': 'PROPN'}],
[{'POS': 'NOUN'}, {'POS': 'NOUN'}],
[{'POS': 'ADJ'}, {'POS': 'PROPN'}],
[{'POS': 'PROPN'}, {'POS': 'ADP'}, {'POS': 'PROPN'}],
[{'POS': 'PROPN'}, {'POS': 'ADJ'}, {'POS': 'NOUN'}],
[{'POS': 'PROPN'}, {'POS': 'VERB'}, {'POS': 'NOUN'}],
[{'POS': 'NOUN'}, {'POS': 'ADP'}, {'POS': 'NOUN'}],
[{'POS': 'PROPN'}, {'POS': 'NOUN'}, {'POS': 'PROPN'}],
[{'POS': 'VERB'}, {'POS': 'ADV'}],
[{'POS': 'PROPN'}, {'POS': 'NOUN'}],
]
matcher = Matcher(nlp.vocab)
matcher.add("pos-matcher", patterns)
# creiamo l'oggetto spacy
doc = nlp(keyword)
# iteriamo tra i match
matches = matcher(doc)
# se match non è vuoto vuol dire che ha trovato almeno un elemento che segue le regole grammaticali
if len(matches) > 0:
return True
return FalseLa Funzione di Benchmark
Abbiamo quasi finito. Questo è l'ultimo passaggio prima di avviare lo script e raccogliere i risultati.
Definiremo una funzione di benchmark che prende come argomenti il nostro corpus e valore booleano per mescolare o meno i nostri dati. Per ogni estrattore, chiama la funzione extract_keywords_from_corpus, che restituisce un dizionario contenente il risultato di quell'estrattore. Memorizziamo quel valore in un elenco.
Per ogni algoritmo della lista, calcoliamo
- numero medio di parole chiave estratte
- numero medio di parole chiave corrispondenti
- calcolare un punteggio che tenga conto del numero medio di corrispondenze trovate diviso per il tempo impiegato per eseguire l'operazione
- salviamo tutti i nostri dati in un DataFrame Pandas e li esportiamo in .csv.
def benchmark(corpus, shuffle=True):
"""Questa funzione esegue il benchmark per gli algoritmi di estrazione delle parole chiave"""
logging.info("Starting benchmark...\n")
# Randomizziamo l'ordine del corpus
if shuffle:
random.shuffle(corpus)
# estrazione delle keyword
results = []
extractors = [
rake_extractor,
yake_extractor,
topic_rank_extractor,
position_rank_extractor,
single_rank_extractor,
multipartite_rank_extractor,
keybert_extractor,
]
for extractor in extractors:
result = extract_keywords_from_corpus(extractor, corpus)
results.append(result)
# calcolare il numero medio di parole chiave estratte
for result in results:
len_of_kw_list = []
for kws in result["corpus_kws"].values():
len_of_kw_list.append(len(kws))
result["avg_keywords_per_document"] = np.mean(len_of_kw_list)
# match con i pattern grammaticali
for result in results:
for idx, kws in result["corpus_kws"].items():
match_results = []
for kw in kws:
match_results.append(match(kw))
result["corpus_kws"][idx] = match_results
# calcolare il numero medio di parole chiave che matchano
for result in results:
len_of_matching_kws_list = []
for idx, kws in result["corpus_kws"].items():
len_of_matching_kws_list.append(len([kw for kw in kws if kw]))
result["avg_matched_keywords_per_document"] = np.mean(len_of_matching_kws_list)
# calcolare la percentuale media di parole chiave che matchano, decimali arrotondati a 2
result["avg_percentage_matched_keywords"] = round(result["avg_matched_keywords_per_document"] / result["avg_keywords_per_document"], 2)
# creare un punteggio basato sulla percentuale media di parole chiave che matchano divisa per il tempo trascorso (in secondi)
for result in results:
elapsed_seconds = get_sec(result["elapsed_time"]) + 0.1
# pesare il punteggio in base al tempo trascorso
result["performance_score"] = round(result["avg_matched_keywords_per_document"] / elapsed_seconds, 2)
# cancellare corpus_kw
for result in results:
del result["corpus_kws"]
# creazione dataframe
df = pd.DataFrame(results)
df.to_csv("results.csv", index=False)
logging.info("Benchmark finished. Results saved to results.csv")
return dfdef get_sec(time_str):
"""Calcolare i secondi"""
h, m, s = time_str.split(':')
return int(h) * 3600 + int(m) * 60 + int(s)Risultati
Per lanciare il benchmark basta fare
# su un laptop di 4 anni ha impiegato circa 3 ore
results = benchmark(texts[:2000], shuffle=True)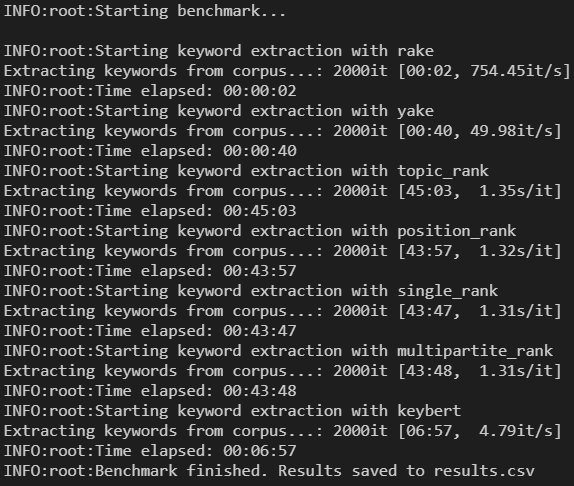
Ed ecco i risultati

e un grafico a barre con il punteggio delle prestazioni
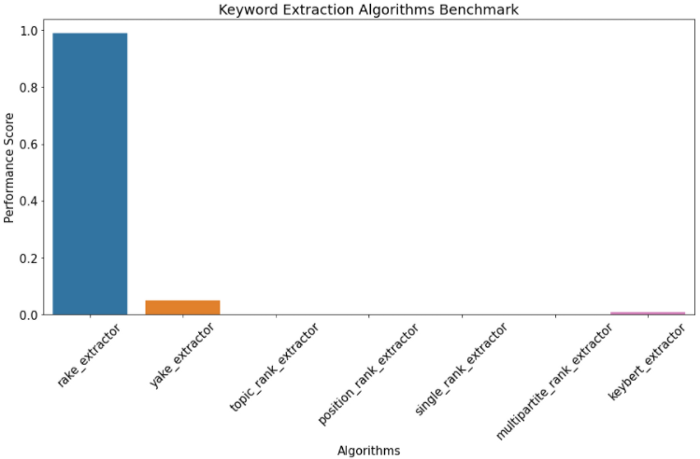
Rake vince su tutti gli altri algoritmi di molto secondo la formula del punteggio che è (avg_matched_keywords_per_document / time_elapsed_in_seconds). Il fatto che Rake elabori 2000 documenti in 2 secondi è impressionante, e anche se la precisione non è così alta come Yake o KeyBERT, il fattore tempo lo fa vincere sugli altri.
Se dovessimo considerare solo l'accuratezza, calcolata come il rapporto tra avg_matched_keywords_per_document e avg_keywords_per_document, otteniamo questi risultati
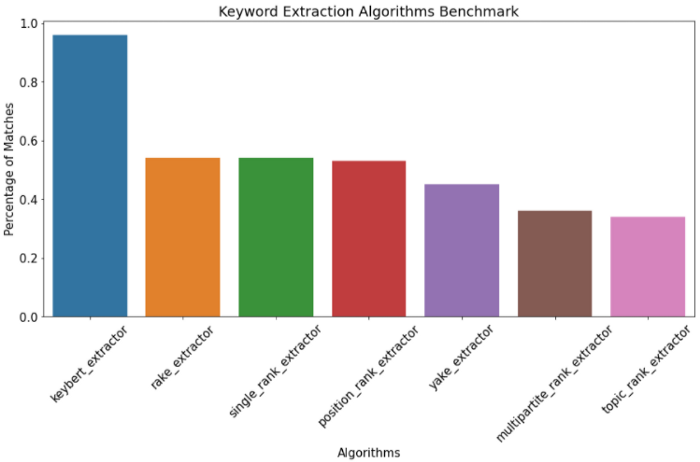
Rake si comporta abbastanza bene anche dal punto di vista della accuracy. Ha senso avere un punteggio di prestazioni così elevato dato il breve tempo necessario per eseguire l'estrazione.
Considerazioni finali
Se non consideriamo iltempo nell'equazione, KeyBERT avrebbe sicuramente preso il posto del vincitore come l'algoritmo più accurato in grado di estrarre parole chiave sensate.
Lo scopo di questo progetto era trovare il miglior algoritmo in termini di efficienza. Per questo compito, Rake sembra prendere quel posto.
In conclusione, se abbiamo bisogno di precisione rispetto a qualsiasi altra cosa, KeyBERT è la soluzione, altrimenti Rake o Yake. Userei Yake nei casi in cui non ho obiettivi particolari e desidero solo una soluzione equilibrata.
Riferimenti
Campos, R., Mangaravite, V., Pasquali, A., Jatowt, A., Jorge, A., Nunes, C. and Jatowt, A. (2020). YAKE! Keyword Extraction from Single Documents using Multiple Local Features. In Information Sciences Journal. Elsevier, Vol 509, pp 257–289. pdf
Campos R., Mangaravite V., Pasquali A., Jorge A.M., Nunes C., and Jatowt A. (2018). A Text Feature Based Automatic Keyword Extraction Method for Single Documents. In: Pasi G., Piwowarski B., Azzopardi L., Hanbury A. (eds). Advances in Information Retrieval. ECIR 2018 (Grenoble, France. March 26–29). Lecture Notes in Computer Science, vol 10772, pp. 684–691. pdf
Campos R., Mangaravite V., Pasquali A., Jorge A.M., Nunes C., and Jatowt A. (2018). YAKE! Collection-independent Automatic Keyword Extractor. In: Pasi G., Piwowarski B., Azzopardi L., Hanbury A. (eds). Advances in Information Retrieval. ECIR 2018 (Grenoble, France. March 26–29). Lecture Notes in Computer Science, vol 10772, pp. 806–810.
Csurfer. (n.d.). CSURFER/Rake-nltk: Python implementation of the rapid automatic keyword extraction algorithm using NLTK. Retrieved November 25, 2021, from https://github.com/csurfer/rake-nltk
Liaad. (n.d.). Liaad/Yake: Single-document unsupervised keyword extraction. Retrieved November 25, 2021, from https://github.com/LIAAD/yake
Boudinfl. (n.d.). BOUDINFL/pke: Python keyphrase extraction module. Retrieved November 25, 2021, from https://github.com/boudinfl/pke
MaartenGr. (n.d.). MAARTENGR/Keybert: Minimal keyword extraction with bert. Retrieved November 25, 2021, from https://github.com/MaartenGr/KeyBERT
Explosion. (n.d.). Explosion/spacy: 💫 industrial-strength natural language processing (NLP) in Python. Retrieved November 25, 2021, from https://github.com/explosion/spaCy





Commenti dalla community