
Hai creato un modello predittivo sul tuo dataset. Questo performa bene sia in cross-validazione che sul test set.
Molto bene.
Ma ora che ci fai?
Un modello di machine learning ha poca utilità se non viene usato da qualcuno.
Il nostro obiettivo come data scientist è quello di creare buoni modelli e condividerli con il nostro team o clienti.
Nasce quindi l’esigenza di una interfaccia al nostro software che permetta ai nostri utenti di collegarsi e sfruttare i dati o funzioni che mettiamo a disposizione.
Questa tecnologia si chiama API (application programming interface) ed è da tempo sfruttata dai programmatori in praticamente tutte le industry per creare servizi web.
In pratica, un'API fornisce un set di regole e protocolli standardizzati che consentono a un'applicazione di accedere alle funzionalità di un'altra applicazione o servizio e di utilizzarle in modo sicuro e affidabile.
In questo articolo vedremo come creare un modello di machine learning e servirlo attraverso una API.
Grazie a questa conoscenza potrai portarti avanti nella pipeline di machine learning e servire i tuoi modelli (ma anche altre funzionalità volendo) grazie a Python e a FastAPI.
FastAPI è una libreria incredibile, che ha sconvolto lo spazio della data science negli ultimi anni grazie alla sua incredibile usabilità e velocità. Inoltre, la sua documentazione è molto ricca e vasta.
- Modellare un dataset giocattolo con LightGBM
- Scrivere funzioni e classi per creare predizioni su dati non visti
- Servire il modello via REST grazie a FastAPI
Sei pronto? Iniziamo!
Il dataset
Il dataset che userò per questo esempio sarà il California housing dataset di Sklearn, su cui è possibile leggere di più qui

L'obiettivo quindi è creare un semplice modello di regressione della variabile target MedInc cioè il valore mediano del reddito familiare annuo per i distretti della California, espresso in centinaia di migliaia di dollari ($ 100.000).
Il feature set è composto da 7 variabili:
HouseAge: età mediana di una casa nel distrettoAveRooms: numero medio di camere per un nucleo familiareAveBedrms: numero medio di camere da letto per nucleo familiarePopulation: popolazione del distrettoAveOccup: numero medio di membri di un nucleo familiareLatitude: latitudineLongitude: longitudine
Il dataset è composto da 20640 esempi e non sono presenti valori vuoti.
Quando si lavora con un dataset reale questo non è mai il caso e il preprocessing sarà praticamente sempre d'obbligo.
Modellazione del dato con LightGBM
Poiché il focus di questo articolo è mostrare come usare FastAPI per servire un qualsivoglia modello di apprendimento automatico, salterò direttamente alla fase di modeling del dataset.
Questo significa che non scriverò di:
- come impostare un ambiente di sviluppo per il machine learning
- come strutturare un progetto di machine learning
- come ripartire i dati per la cross-validazione
In un contesto reale si seguirebbe tutta la pipeline di machine learning, che include preprocessing, selezione del modello, cross-validazione e tuning degli iperparametri.
Se vuoi un percorso introduttivo a questi argomenti e molti altri, ti linko la pagina hub di riferimento
 Andrea D’Agostino
Andrea D’Agostino
Userò LightGBM perché è un modello estremamente efficace e veloce per dati tabellari.
La prima cosa da fare è installarlo, poiché non è presente in Sklearn (anche se è disponibile una API dedicata)
pip install lightgbmA questo punto creiamo uno script o notebook nella nostra cartella di progetto e iniziamo con questo codice
import pandas as pd
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing() # importiamo il dataset da sklearn
df = pd.DataFrame(data.data, columns=data.feature_names) # inseriamolo in un dataframe pandas
df.head()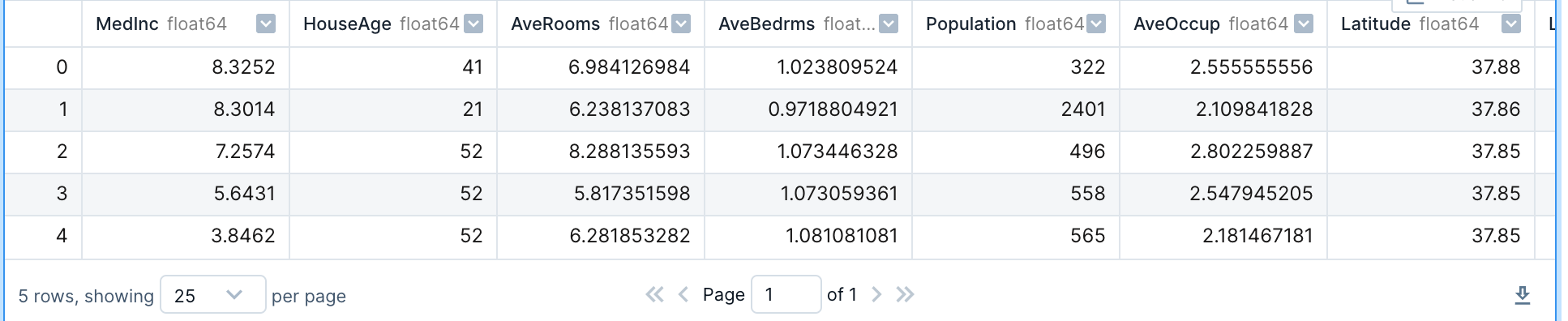
Ora dividiamo in set di addestramento e test
from sklearn.model_selection import train_test_split
X = df.drop("MedInc", axis=1)
y = df['MedInc']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape)
>>>
(16512, 7) (4128, 7)Ora siamo pronti ad addestrare un regressore LightGBM.
import lightgbm
from sklearn import metrics
# addestramento del modello
lgbm_model = lightgbm.LGBMRegressor()
lgbm_model.fit(X_train, y_train)
# creazione predizione
y_pred = lgbm_model.predict(X_test)
# valutazione del modello
mse = metrics.mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print(f"Root Mean Squared Error: {rmse:.2f}")
>>>
Root Mean Squared Error: 0.81Salviamo il modello in formato pickle così da poterlo utilizzare nell'API.
import pickle
model_filename = 'model.pkl'
with open(model_filename, 'wb') as model_file:
pickle.dump(lgbm_model, model_file)Con il modello pronto per fare predizioni possiamo ora creare la nostra API.
Creazione dell'API con FastAPI
Creiamo un file chiamato api.py nella nostra cartella. Sottolineo che deve essere un file .py e non .ipynb perché dovremmo accendere un server che richiede un terminale attivo.
Installiamo FastAPI e Uvicorn. Uvicorn è una dipendenza di FastAPI ed è la libreria che creerà il server.
pip install fastapi uvicornPer lo script api.py ci serviranno diverse cose
- Una classe Pydantic che manterrà il modello dati per il feature set
- Una funzione dedicata al caricamento del modello e alla predizione
- Un contesto per il ciclo vitale del modello di machine learning
- Un endpoint da chiamare via browser
Sembra complicato, ma in realtà è molto semplice.
Vediamo step-by-step cosa fare.
Pydantic per creare il modello dati
Perché serve un modello dati? Perché FastAPI funziona molto bene con Pydantic.
Se non lo sai Pydantic è una libreria molto potente per la gestione dei modelli dati. Permette di configurarli e di fare validazione su diverse proprietà.
Ti invito a leggere l'articolo qui per ulteriori dettagli
Andrea D’Agostino
Creare un modello dati è semplice. Sempre in api.py, iniziamo lo script così
from pydantic import BaseModel
class FeatureSet(BaseModel):
HouseAge: float
AveRooms: float
AveBedrms: float
Population: float
AveOccup: float
Latitude: float
Longitude: float
Questa classe verrà fornita a FastAPI per interpretare correttamente i dati in input e la loro struttura.
Caricamento del modello e predizione
Creiamo subito dopo il modello dati una funzione che esporrà la funzione .predict del modello. Usiamo pickle per caricare il modello.
def medinc_regressor(x: dict) -> dict:
with open("model.pkl", 'rb') as model_file:
loaded_model = pickle.load(model_file)
x_df = pd.DataFrame(x, index=[0])
res = loaded_model.predict(x_df)[0]
return {"prediction": res}La funzione medinc_regressor sarà responsabile di ricevere un feature set x e di restituire una risposta del modello.
Creazione di un ciclo vitale per il modello
Qui è dove FastAPI aiuta noi programmatori di modelli di ML.
Guardiamo il codice
ml_models = {}
@asynccontextmanager
async def ml_lifespan_manager(app: FastAPI):
# caricamento della funzione dedicata alla predizione
ml_models["medinc_regressor"] = medinc_regressor
yield
# pulizia delle risorse
ml_models.clear()A cosa serve tutto ciò?
In uno scenario reale, uno o più modelli di machine learning sono condivisi tra le varie richieste in entrata degli utenti. Non c'è una associazione 1 modello = 1 utente.
Immaginiamo che il caricamento del modello possa richiedere del tempo perché ad esempio deve leggere molti dati dal disco...è spontaneo pensare che non vogliamo che questa cosa accada per ogni singola richiesta.
Quello che il lifespan manager fa è caricare il modello prima che le richieste vengano gestite, ma solo subito prima che l'applicazione inizi a ricevere richieste e non durante il caricamento del codice.
Se può sembrarti complicato non preoccuparti: sappi che FastAPI ci aiuta molto proprio a gestire dettagli del genere che in un contesto reale hanno un impatto importante.
In ogni caso ti linko qui la documentazione ufficiale di FastAPI che copre il lifespan manager.


Creazione di un endpoint da chiamare via browser
Ora definiamo l'oggetto principale di questo script: l'app FastAPI e un endpoint da chiamare via richiesta POST.
app = FastAPI(lifespan=ml_lifespan_manager)
@app.post("/predict")
async def predict(feature_set: FeatureSet):
return ml_models["medinc_regressor"](feature_set.dict())FastAPI accetta il lifespan manager creato sopra e inizierà a gestire correttamente il flusso di richieste.
Subito dopo aver creato l'applicazione FastAPI, c'è una funzione asincrona chiamata predict che evoca il modello come negli snippet di codice precedenti.
La dicitura @app.post("/predict") informa FastAPI che vogliamo creare una rotta chiamata /predict che accetta richieste di tipo POST.
predict accetta l'oggetto Pydantic creato sopra. Qui è dove avviene la validazione del dato. Viene quindi passato il feature set in forma dizionario al modello di machine learning per la predizione.
Ce l'hai fatta a leggere fino a qui. Congratulazioni! Ora riassumiamo quanto fatto finora.
L'intero script sarà questo
import pickle
import pandas as pd
import numpy as np
from fastapi import FastAPI
from contextlib import asynccontextmanager
from pydantic import BaseModel
class FeatureSet(BaseModel):
"Modello dati basato su Pydantic"
HouseAge: float
AveRooms: float
AveBedrms: float
Population: float
AveOccup: float
Latitude: float
Longitude: float
def medinc_regressor(x: dict) -> dict:
"""Funzione dedicata alla predizione"""
with open("model.pkl", 'rb') as model_file:
loaded_model = pickle.load(model_file)
x_df = pd.DataFrame(x, index=[0])
res = loaded_model.predict(x_df)[0]
return {"prediction": res}
# Creazione di un context manager per la gestione del ciclo di vita del modello
ml_models = {}
@asynccontextmanager
async def ml_lifespan_manager(app: FastAPI):
ml_models["medinc_regressor"] = medinc_regressor
yield
ml_models.clear()
app = FastAPI(lifespan=ml_lifespan_manager)
@app.post("/predict")
async def predict(feature_set: FeatureSet):
return ml_models["medinc_regressor"](feature_set.dict())Non rimane altro che avviare l'API. Apriamo un terminale e scriviamo
> uvicorn api:app --reload --port 8010
Uvicorn creerà un server in ascolto proprio alla porta 8010, caricando il contenuto presente nel file api.py, guardando l'applicazione chiamata app all'interno di esso.
Se ora raggiungiamo nel browser http://127.0.0.1:8010 verremo accolti da questa schermata
Questo è normale. Andiamo su /docs per vedere una delle cose più belle di FastAPI: documentazione autogenerata.
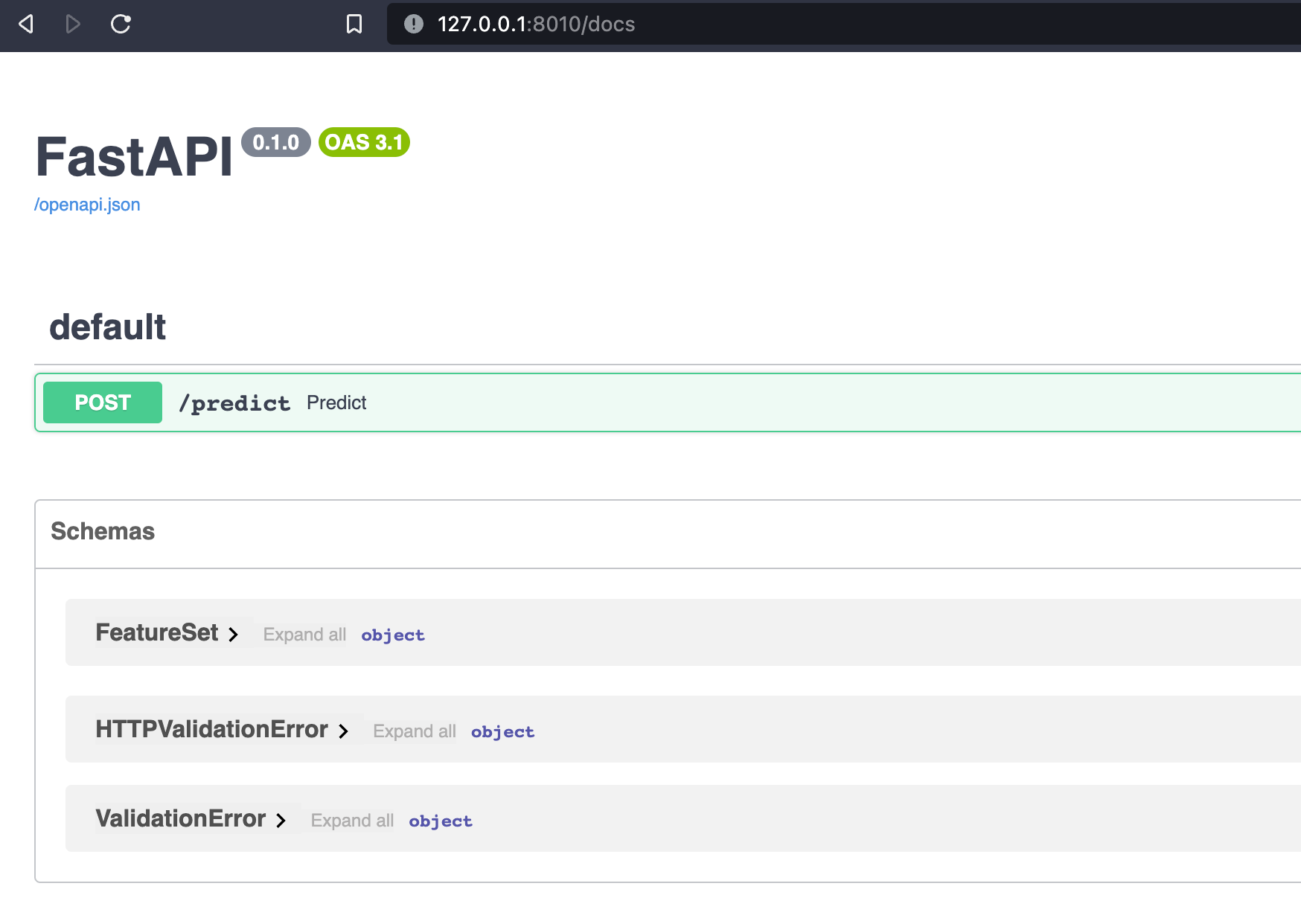
Vediamo come ci sia una rotta POST chiamata /predict, proprio come da noi programmata poco fa.
Espandendo la riga e cliccando su "Try it out" è possibile inviare una richiesta per testare il tutto.
Inseriamo dei valori di test e clicchiamo su "Execute".
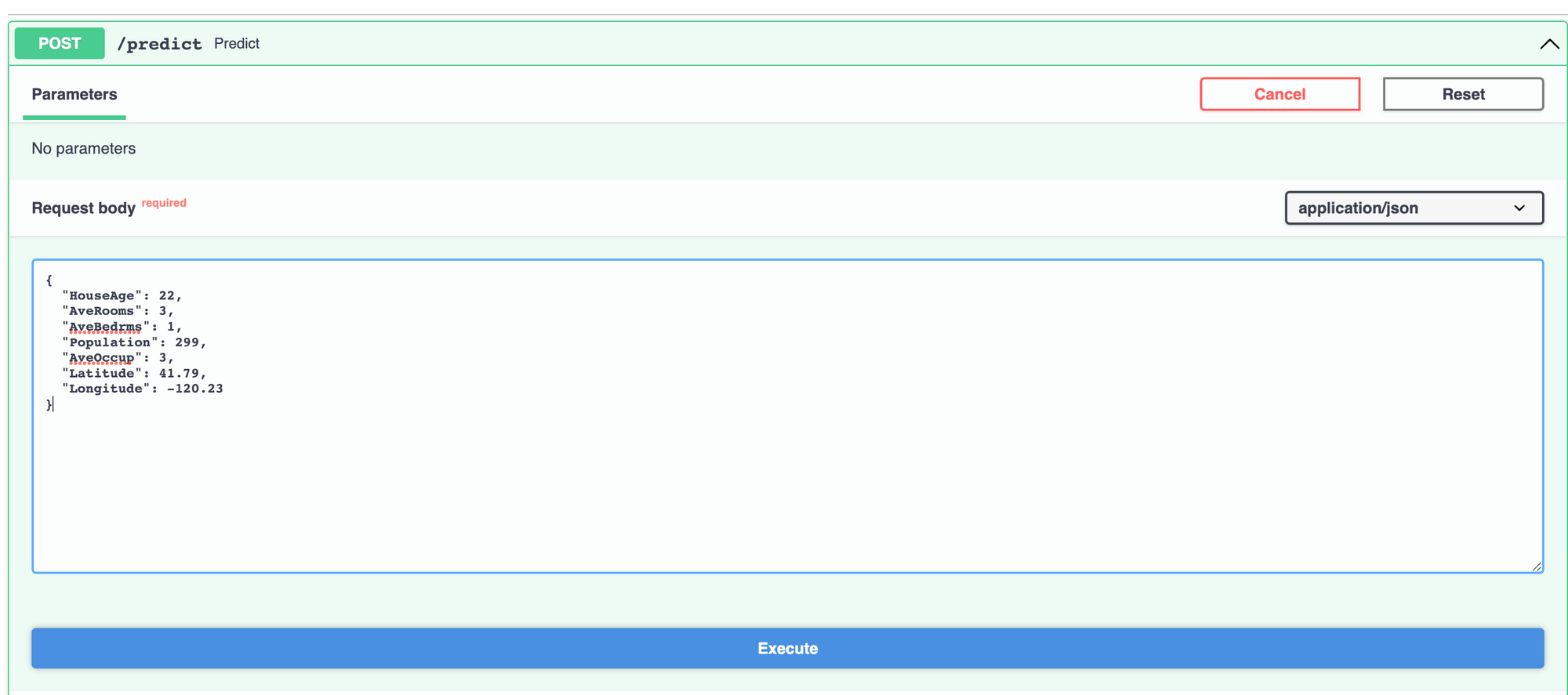
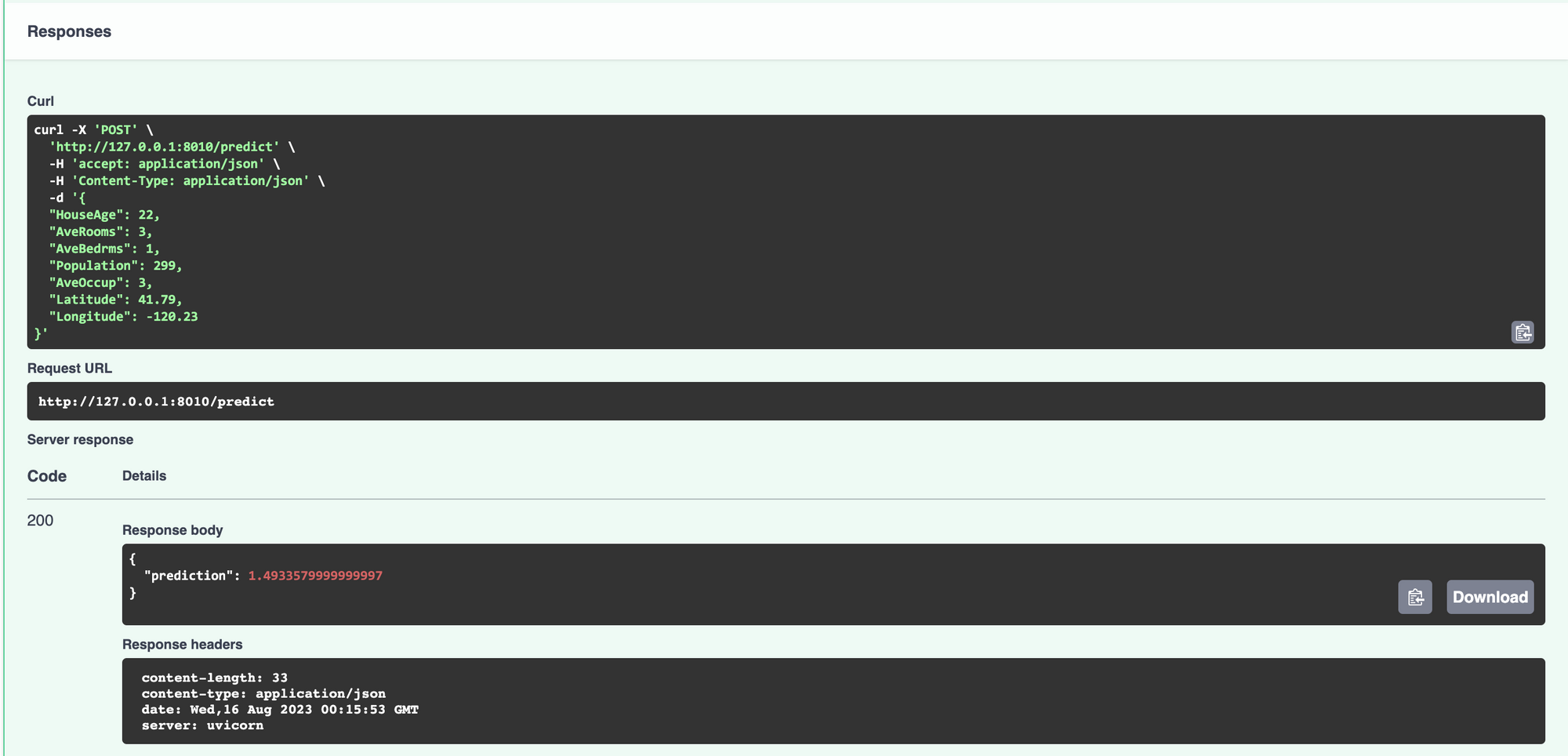
Il nostro modello di machine learning viene correttamente caricato e crea una predizione. Alla grande!
Next step
Creare una API ci permette di servire modelli non di deployarli. C'è una bella differenza.
Deployare significa metterli online.
Un server del genere, al momento, risiederebbe solamente sul nostro PC in locale. Serve quindi uno step di deployment su un server virtuale (ad esempio macchine Google o Amazon) e impostare l'API con una rotta raggiungibile ad esempio a http://miosito.com/predict.
Il deployment non è oggetto di questo articolo ma verrà trattato nel futuro e questa sezione aggiornata per linkare a tale risorsa.
Conclusioni
Ecco un sommario di ciò che hai imparato
- Cosa è una API e cosa ti permette di fare
- Come creare un semplice modello predittivo e salvarlo in formato .pkl
- Come creare una API con FastAPI, passando per diversi dettagli tecnici utili per rendere il caricamento e la predizione più efficienti.
Spero che questo articolo ti abbia aiutato ad inserire un tassello in più nella tua formazione da data scientist.
Se ci sono domande o dubbi, non esitare a commentare o a scrivermi.
Alla prossima,
Andrea





Commenti dalla community