
In questo articolo, esploreremo il mondo affascinante degli algoritmi di clustering, svelando il loro significato e dimostrando perché rappresentano uno strumento cruciale nell'analisi dei dati.
Gli algoritmi di clustering sono come i detective dei dati, il cui compito principale è identificare pattern e relazioni nascoste nei tuoi dati.
Ci aiutano a rispondere a domande come:
- Quali sono le similitudini tra i miei clienti?
- Come posso suddividere i miei prodotti in categorie significative?
- Quali sono le tendenze nei dati che potrebbero sfuggire all'occhio umano?
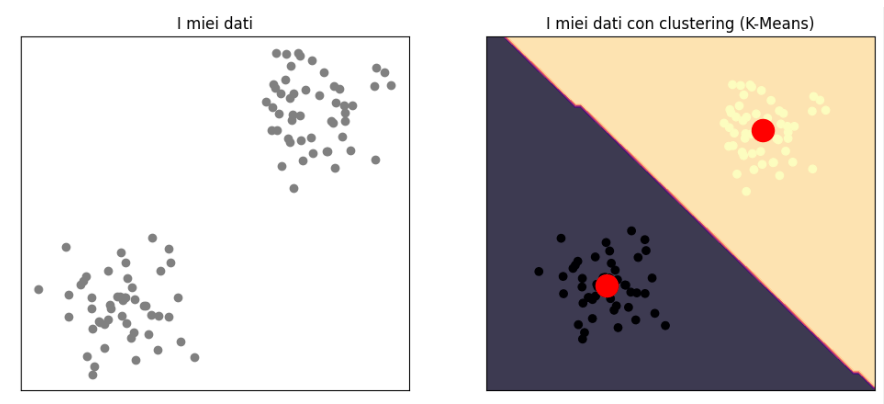
La capacità di queste tecniche di poter rispondere a domande del genere rende la cluster analysis una delle metodiche più utilli (e quindi pagate) nell'ambito dell'analisi dei dati e della data science.
Nel corso di questo articolo, esamineremo in dettaglio cosa sono gli algoritmi di clustering, come funzionano e perché sono un elemento fondamentale in vari settori, dalla marketing intelligence all'analisi delle reti sociali.
Anche se non sei un esperto in analisi dei dati, non preoccuparti - cercherò di spiegare tutto in modo chiaro e accessibile, in modo che alla fine dell'articolo sarai in grado di comprendere l'importanza dei clustering nella tua sfera di interesse.
Prima di immergerci nei dettagli tecnici, cominciamo con una panoramica generale su cosa siano esattamente questi algoritmi di clustering e perché dovresti interessartene.
Cosa sono gli algoritmi di clustering?
Per iniziare, diamo una definizione semplice ma esaustiva:
Gli algoritmi di clustering sono procedure matematiche progettate per organizzare un insieme di dati in gruppi omogenei o "cluster" in base alle loro caratteristiche simili.
Immagina di avere un cesto pieno di frutta mista e il tuo obiettivo è separare le mele dalle banane, gli agrumi dai kiwi. Gli algoritmi di clustering farebbero proprio questo, ma su un grande set di dati, in modo più sofisticato e accurato di quanto potremmo fare manualmente.
Nel contesto del machine learning, gli algoritmi di clustering ricadono nella categoria degli algoritmi non supervisionati. Significa che essi sono in grado di raggiungere i risultati per cui sono progettati senza aver bisogno di dati da cui apprendere.
Se vuoi saperne di più su cosa sia il machine learning e le differenze tra l'apprendimento supervisionato e non supervisionato, ti suggerisco di leggere il seguente articolo
 Andrea D’Agostino
Andrea D’Agostino
Perché sono importanti?
Ora che sa cosa sono, la domanda successiva è: perché dovresti preoccuparti del clustering e degli algoritmi ad essi associati? Ecco alcune ragioni chiave:
Comprendere i dati
Gli algoritmi di clustering aiutano a rendere comprensibili grandi quantità di dati.
Immagina di avere migliaia di punti dati che rappresentano gli utenti di un sito web. Con il clustering, puoi suddividerli in gruppi basati su comportamenti o preferenze comuni, permettendoti di capire meglio chi sono i tuoi utenti e come interagiscono con il tuo sito.
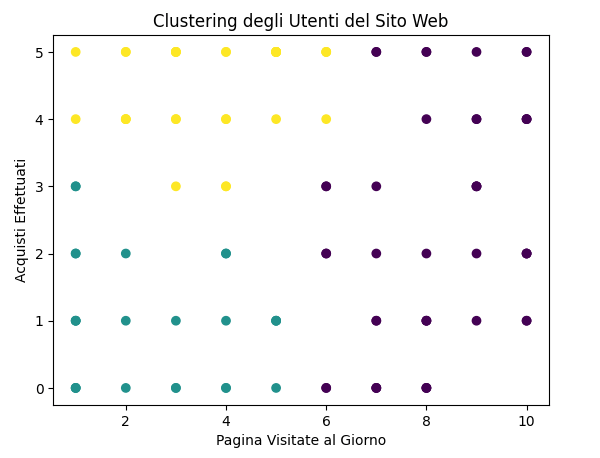
Nell'immagine di esempio - gli utenti nel cluster giallo sono quelli che mostrano un comportamento ideale: poche pagine visitate, alto numero di acquisti. Questi sono gli utenti che vogliamo targettare con delle attività di marketing!
Identificare anomalie nei dati
Il clustering può rivelare pattern o tendenze che potrebbero non essere evidenti a una prima occhiata. Ad esempio, potrebbero aiutarti a identificare gruppi di clienti che acquistano prodotti simili ma che potresti non aver mai associato in precedenza.
Ho scritto un articolo dedicato a questo use case 👇
Andrea D’Agostino
Aumentare l'efficienza
In molti settori, come la logistica o la produzione, l'uso del clustering può portare a una migliore organizzazione delle risorse. Ad esempio, potresti ottimizzare le consegne suddividendo le destinazioni in cluster geografici.
Personalizzazione
Il clustering può essere utilizzati per personalizzare l'esperienza dell'utente. Ad esempio, un sito di e-commerce potrebbe suggerire prodotti simili a quelli già acquistati da un cliente, basandosi sui cluster a cui appartiene.
Segmentazione del mercato
Nel campo del marketing, il clustering puòaiutare a identificare segmenti di mercato specifici, consentendo alle aziende di adattare le loro strategie di marketing in modo più mirato.
In sostanza, fare clustering sui propri dati può far emergere notevoli insight in base proprio ai dati che abbiamo e al contesto lavorativo.
A breve esploreremo alcuni dei principali tipi di algoritmi di clustering e come ciascuno di essi affronta il compito di raggruppare dati in modo efficiente e accurato. Faremo questo in Python e Sklearn.
Alcuni degli algoritmi di clustering più comuni
Qui vedremo alcuni degli algoritmi di clustering più usati nell'ambito della analisi dei dati.
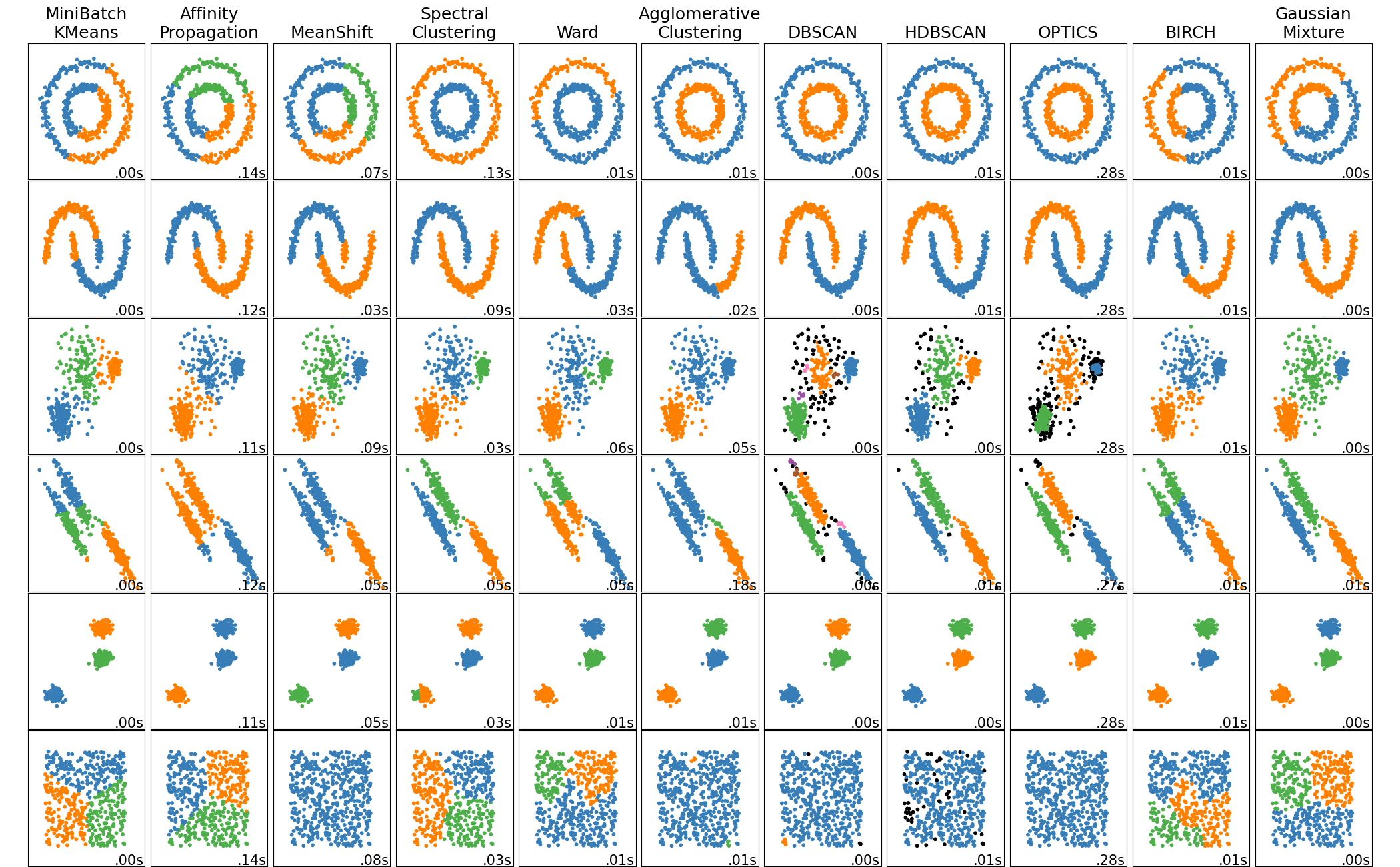
Utilizzando Scikit-Learn, nota libreria di machine learning in Python, è possibile creare rapidamente delle visualizzazioni per questi algoritmi. Nell'immagine in basso è possibile notare come, sullo stesso set di dati, diversi algoritmi di clustering restituiscano raggruppamenti notevolmente diversi.
Questo perché ognuno di questi algoritmi ha il proprio approccio unico per raggruppare i dati, il che li rende adatti a diverse situazioni.
K-Means
Questo è uno degli algoritmi di clustering più popolari. Si basa sulla divisione dei dati in un numero specifico di cluster (k) in modo che ogni punto dati sia assegnato al cluster più vicino al suo centro. È ampiamente utilizzato in applicazioni come la segmentazione dei clienti e la compressione delle immagini.
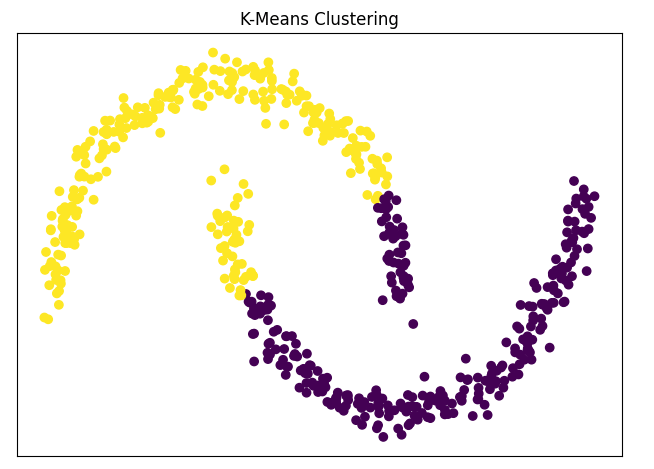
Su questo blog è presente un articolo dedicato proprio al K-Means
Marco Speciale
Clustering gerarchico
Questo algoritmo crea una gerarchia di cluster, a partire da singoli punti dati e combinandoli gradualmente in cluster più grandi. Questo permette di visualizzare i dati a diverse scale di dettaglio ed è utile quando non si conosce a priori il numero di cluster desiderato.
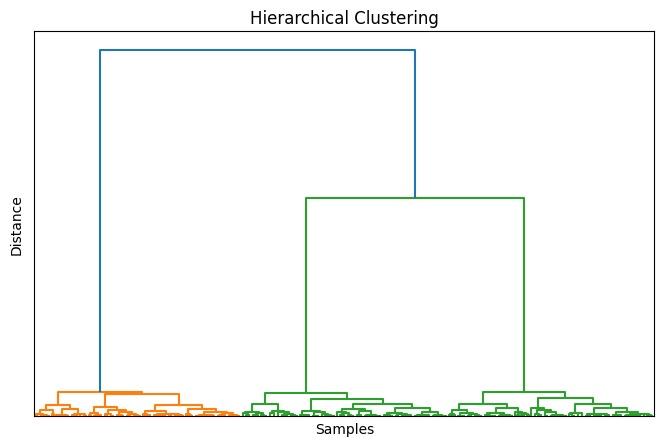
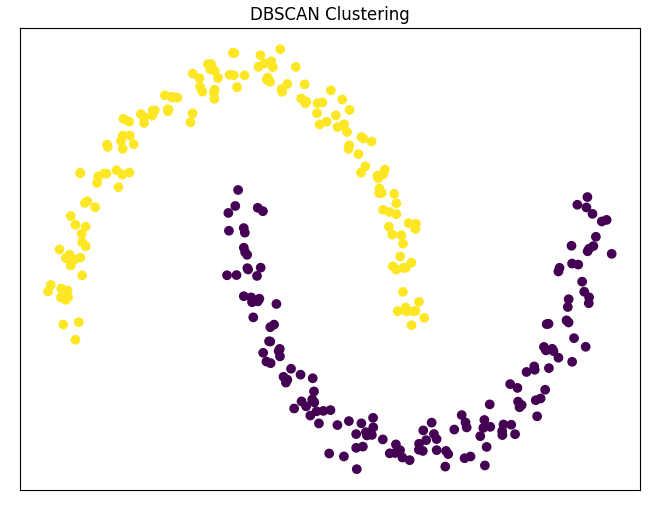
DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) è un algoritmo che trova cluster basati sulla densità dei punti dati. È particolarmente efficace nel rilevare cluster di forme irregolari e può identificare punti dati isolati come rumore.
Gaussian Mixture Models (GMM)
GMM è un modello statistico che assume che i dati siano generati da una miscela di distribuzioni gaussiane. È spesso utilizzato per problemi di clustering probabilistico e può essere esteso per modellare cluster con diverse forme e dimensioni.
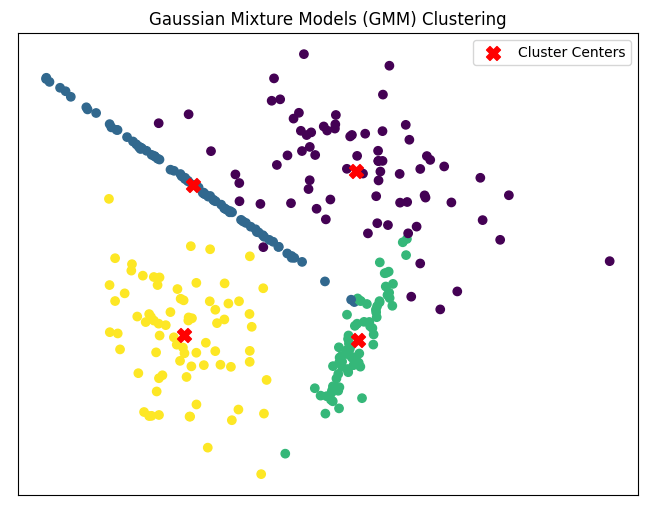
Altri tipi di algoritmi di clustering oltre a quelli tradizionali
Finora abbiamo esplorato alcuni dei concetti fondamentali relativi agli algoritmi di clustering e ai loro utilizzi.
Tuttavia, il mondo dell'analisi dei dati è vasto e complesso, e ci sono molti altri algoritmi di clustering avanzati che vale la pena conoscere. In questa sezione, ci concentreremo su tre di questi: il biclustering, il fuzzy clustering e lo spectral clustering.
Biclustering
Il biclustering, a volte chiamato co-clustering, è un approccio da considerare quando hai bisogno di suddividere i dati in cluster sia lungo le righe che lungo le colonne. In altre parole, non cerchi solo di raggruppare le istanze dei dati, ma anche le loro caratteristiche.
Questo è particolarmente utile in applicazioni in cui si desidera identificare sottogruppi di dati che mostrano comportamenti simili su un sottoinsieme di attributi.
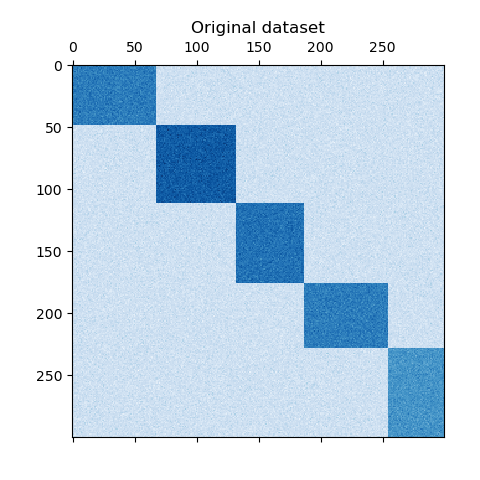
Un esempio pratico potrebbe essere l'analisi dei geni in un esperimento di espressione genica, dove vuoi trovare gruppi di geni che vengono regolati in modo simile in diverse condizioni sperimentali. Alcuni algoritmi biclustering noti includono il Spectral Co-Clustering e il BiMax.
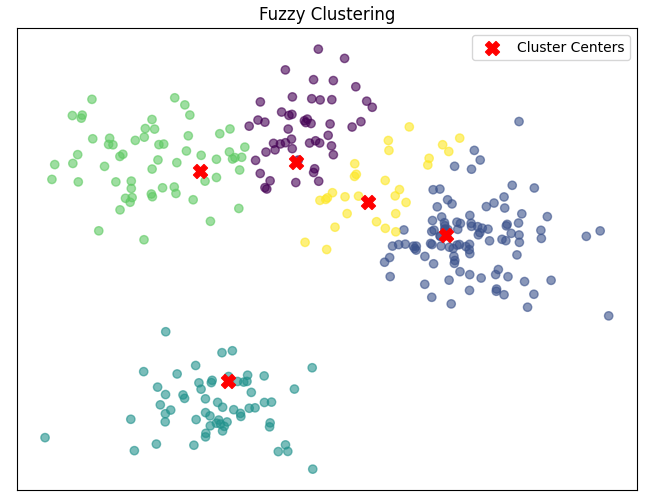
Fuzzy clustering
Nel clustering fuzzy, a differenza del K-Means tradizionale, i punti dati possono appartenere a più di un cluster con gradi diversi di appartenenza.
Invece di assegnare rigidamente ciascun punto a un solo cluster, l'algoritmo fuzzy attribuisce a ciascun punto un valore di appartenenza a ciascun cluster. Questo approccio è utile quando i dati possono avere una natura ambigua o quando potrebbero appartenere a più cluster in base a diverse caratteristiche.
Ad esempio, nell'analisi delle immagini mediche, potresti utilizzare il fuzzy clustering per assegnare una probabilità di appartenenza di ciascun pixel a diverse regioni dell'immagine, come tessuto sano o tumorale.
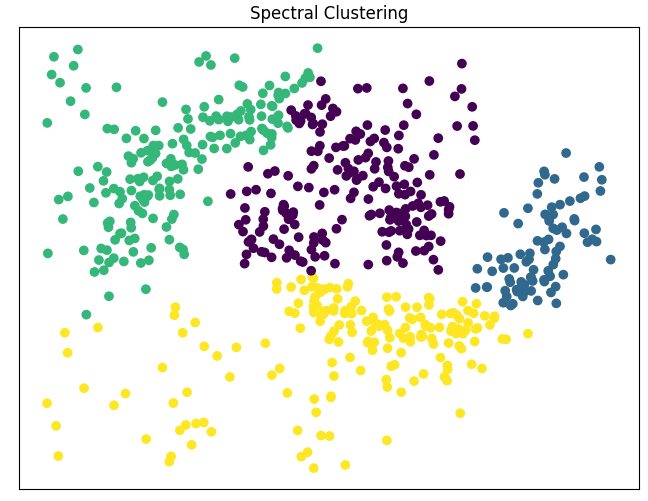
Spectral clustering
Lo spectral clustering è un approccio basato sulla teoria dei grafi e la matrice di similarità tra i punti dati.
Questo metodo è particolarmente efficace nel rilevare cluster con forme non necessariamente sferiche e può essere applicato a dati di alta dimensionalità. La chiave dello spectral clustering è la trasformazione dei dati in uno spazio diverso, dove la struttura dei cluster è più evidente.
Questo tipo di clustering è utilizzato in una varietà di applicazioni, tra cui rilevamento delle comunità in reti sociali e segmentazione delle immagini.
Come valutare l'efficacia degli algoritmi di clustering e interpretare i risultati ottenuti
Ora che abbiamo esaminato vari tipi di algoritmi di clustering, è importante comprendere come valutare l'efficacia di questi algoritmi e come interpretare i risultati ottenuti. Ecco alcune delle tecniche e metriche chiave utilizzate per questa valutazione.
Indici di Validità del Cluster (CVI)
Gli indici di validità del cluster sono misure quantitative utilizzate per valutare l'efficacia di un algoritmo di clustering.
Questi indici forniscono una valutazione oggettiva della qualità dei cluster formati. Alcuni esempi comuni di indici di validità del cluster includono:
- Indice di Silhouette: Questo indice misura quanto ogni punto dati è simile ai punti del suo stesso cluster rispetto ai punti degli altri cluster. Varia da -1 a 1, dove valori più alti indicano cluster più coesi.
- Indice del Gomito (Elbow Method): Questo metodo aiuta a determinare il numero ottimale di cluster (k) confrontando la variazione della somma dei quadrati all'interno dei cluster (WCSS) per diversi valori di k. Il punto in cui la variazione inizia a diminuire drasticamente è spesso scelto come il numero ottimale di cluster. È spessissimo utilizzato per valutare la qualità dei cluster del K-Means.
- Indice di Davies-Bouldin: Questo indice valuta la media delle similarità tra ciascun cluster e il cluster più simile ad esso. Un valore basso indica cluster ben separati.
- Indice di Dunn: Questo indice misura la distanza minima tra i centroidi dei cluster diviso dalla massima distanza tra i punti di ciascun cluster. Un valore alto indica cluster compatti e ben separati.
- Indice di Calinski-Harabasz (Varianza tra-cluster / Varianza intra-cluster): Questo indice confronta la varianza tra i cluster con la varianza all'interno dei cluster. Un valore più alto suggerisce cluster di alta qualità.
La visualizzazione dei dati
Tecniche di visualizzazione dei dati multidimensionali come la PCA o la t-distributed Stochastic Neighbor Embedding (t-SNE) possono essere molto utili per visualizzare la separazione dei nostri cluster.
È possibile usare la PCA o t-SNE per proiettare i tuoi dati clusterizzati in uno spazio bidimensionale o tridimensionale in modo da poterli visualizzare facilmente e valutare visivamente. Ho trattato l'argomento in dettaglio a questo articolo 👇
Andrea D’Agostino
Interpretazione dei risultati
Interpretare i risultati del clustering è un passaggio critico. Dopo aver eseguito l'algoritmo e calcolato le metriche di validità del cluster, devi considerare il contesto e gli obiettivi del tuo problema. Alcune delle domande chiave da porsi includono:
- Sono i cluster risultanti significativi dal punto di vista pratico? Hanno senso per il tuo contesto / dominio lavorativo?
- Come cambiano i risultati al variare dei parametri dell'algoritmo (come il numero di cluster k nel caso di K-Means)?
- Quali sono le caratteristiche principali che distinguono i cluster? Puoi utilizzare tecniche di visualizzazione o analisi delle caratteristiche per rispondere a questa domanda.
- Come possono i risultati del clustering essere utilizzati per prendere decisioni o formulare ipotesi?
- C'è un miglioramento nei risultati dopo aver applicato tecniche di preprocessing dei dati?
- Come si confrontano i risultati del clustering con i risultati desiderati o con l'expertise del dominio?
Il lavoro di data scientist è arriva al culmine della complessità proprio durante la fase di interpretazione dei dati: il processo è un'arte tanto quanto una scienza.
È importante utilizzare una combinazione di metriche quantitative e comprensione qualitativa per determinare se il clustering è utile per il tuo problema e per trarre conclusioni significative dai dati.
Conclusione
In questo articolo, abbiamo esplorato l'affascinante mondo degli algoritmi di clustering e le diverse metriche utilizzate per valutarne l'efficacia.
Abbiamo iniziato comprendendo cos'è il clustering e perché è importante nell'analisi dei dati. Abbiamo discusso di diversi tipi di algoritmi di clustering, dai classici come il K-Means agli avanzati come il biclustering, il fuzzy clustering e lo spectral clustering.
Abbiamo anche approfondito come valutare l'efficacia dei cluster utilizzando gli indici di validità del cluster: questi strumenti forniscono un modo obiettivo per determinare il numero ottimale di cluster e valutare la coesione e la separazione dei cluster formati.
Infine, abbiamo discusso l'importanza di interpretare i risultati del clustering alla luce del contesto del problema e degli obiettivi specifici. La visualizzazione dei risultati tramite tecniche come t-SNE può essere di grande aiuto per capire come i dati sono stati suddivisi nei cluster.
Conoscere le tecniche di clustering qui discusse ti metterà in una posizione molto potente dal punto di vista professionale: stai di fatto imparando metodiche applicabili ad vasta gamma di settori, dalla segmentazione del mercato al rilevamento delle comunità in reti sociali.
Mentre continui il tuo viaggio nell'analisi dei dati, ricorda che l'arte del clustering richiede pratica e sperimentazione.
Ogni set di dati è unico, e il tuo spirito di esplorazione e la tua comprensione delle metriche di validità del cluster ti guideranno nel prendere decisioni informate e nell'ottenere intuizioni preziose dai tuoi dati.





Commenti dalla community