
In questo articolo esplorerò un altro concetto fondamentale nella nostra battaglia contro l'over/underfitting: il compromesso bias-varianza.
Uno dei principali obiettivi del machine learning è quello di costruire modelli che possano generalizzare bene su dati che non sono stati ancora visti.
Quando si costruisce un modello, è importante assicurarsi che non sia troppo semplice da non poter catturare le complessità del problema o troppo complesso da sovrapporsi ai dati di addestramento.
In questo articolo, discuteremo del compromesso tra bias e varianza nel machine learning e di come trovare il giusto equilibrio tra i due può aiutare a migliorare le prestazioni del modello.
Iniziamo definendo cosa sia il bias e la varianza:
Bias: rappresenta l'errore di previsione del modello dovuto alle sue semplificazioni. Ad esempio, un modello lineare potrebbe avere un bias elevato se il problema è intrinsecamente non lineare.
Bias vuol dire pregiudizio. Rappresenta quanto il modello sia incline ad interpretare il dato in una certa maniera prima di vedere il dato stesso.
Varianza: rappresenta l'errore di previsione del modello dovuto alla sua sensibilità ai dati di addestramento. Ad esempio, un modello che si adatta molto bene ai dati di addestramento potrebbe avere una varianza elevata se non generalizza bene su dati non visti.
La varianza indica quanto il modello è adattato ai dati di addestramento. Un modello con una varianza elevata si adatta molto bene ai dati di addestramento ma generalizza male su dati non visti.
Ad esempio, immaginiamo di avere un modello di regressione che prevede il prezzo delle case in base a diversi fattori come la dimensione, la posizione, il numero di camere da letto, ecc.
Se il modello ha una varianza elevata, significa che si adatta troppo ai dati di addestramento e potrebbe prevedere prezzi sbagliati per le case che non sono presenti nel set di addestramento.
D'altro canto, se il modello ha una varianza bassa, potrebbe non essere in grado di catturare le complessità del problema e di conseguenza generalizzare male su nuovi dati.
Come trovare il giusto equilibrio
L'obiettivo principale del machine learning è di ridurre l'errore di generalizzazione del modello, ovvero l'errore che si verifica quando il modello viene applicato a dati non visti. Per farlo, è necessario trovare il giusto equilibrio tra bias e varianza.
La scelta del giusto modello dipende dalle esigenze del problema. Ecco una lista di spunti utili su cui ragionare per comprendere come bilanciare il nostro modello.
- Valutare la complessità del modello: modelli semplici come le regressioni lineari hanno un alto bias e bassa varianza, mentre i modelli complessi come le reti neurali hanno un basso bias e alta varianza.
- Dimensione del dataset: aumentando la dimensione del dataset, è possibile ridurre la varianza del modello. Infatti, con più dati di addestramento, il modello avrà maggiori informazioni per generalizzare e ridurre l'adattamento ai dati di addestramento.
- Regolarizzazione: la regolarizzazione è una tecnica utilizzata per controllare la complessità del modello. Ad esempio, la regolarizzazione L1 e L2 possono aiutare a ridurre la varianza del modello.
- Cross-validazione: la validazione incrociata è una tecnica utilizzata per valutare le prestazioni del modello su dati non visti. Ciò aiuta a evitare l'overfitting e a trovare il giusto equilibrio tra bias e varianza.
- Selezione delle feature: la selezione delle feature è un'altra tecnica utilizzata per controllare la complessità del modello. Rimuovere le feature non rilevanti o ridondanti può aiutare a ridurre la varianza del modello.
È importante ricordare che non esiste un unico modello perfetto per tutti i problemi di machine learning. È necessario valutare attentamente le esigenze specifiche del problema e scegliere il modello più adatto per quel contesto.
Per questo motivo l'analista dovrebbe iterare tra diversi modelli, attraverso una fase chiamata selezione del modello, e selezionare quello più performante per il dato problema.
Inoltre, è importante tenere sempre presente che il bilanciamento tra bias e varianza è un processo continuo e dinamico. Le prestazioni del modello possono variare nel tempo e a seconda delle nuove informazioni a disposizione. Pertanto, è necessario monitorare costantemente le prestazioni del modello e apportare eventuali modifiche quando necessario.
Esempi di vari livelli di bilanciamento di bias e varianza nel machine learning
Vediamo come si comportano modelli tra i vari livelli di bias e varianza. Tipicamente i modelli underfittano, overfittano o sono bilanciati.
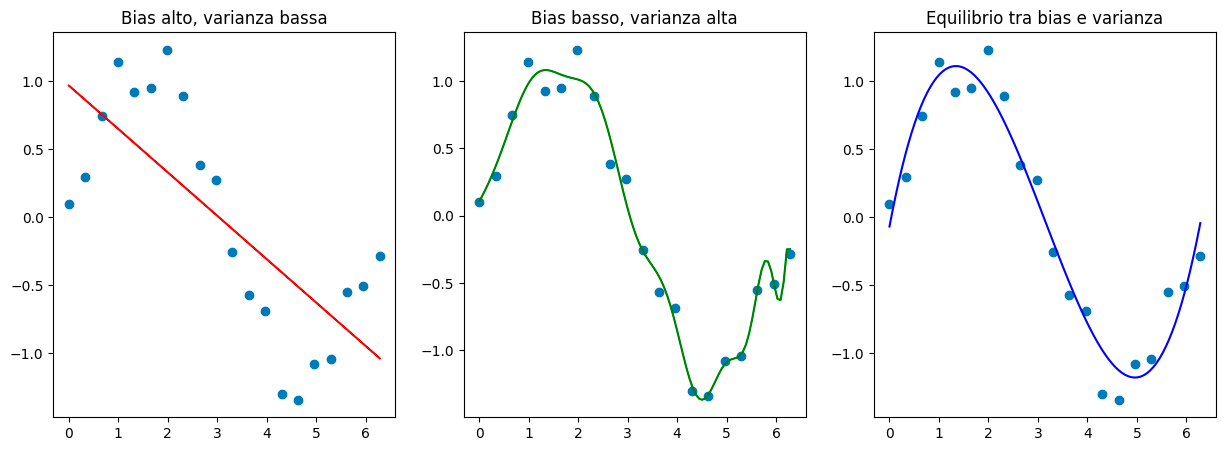
Dato un dataset fittizio fisso, i modelli nei grafici mostrano rispettivamente come appaiono underfitting (bias alto, varianza bassa), overfitting (bias basso, varianza alta) e come questi due siano bilanciati.
Il nostro obiettivo da analisti è quello di trovare il giusto bilanciamento tale che dati non visti siano modellati con un errore alquanto basso rispetto alla ground truth (verità del mondo osservabile).
Questo breve articolo si unisce alla collezione seguente di articoli che hanno come argomento centrale la interpretabilità e la generalizzazione:
- Il più grande ostacolo nel machine learning: l’overfitting
- Regolarizzazione L1 vs L2 nel Machine Learning: differenze, vantaggi e come applicarle in Python
- Perché avere un grosso numero di feature può peggiorare il tuo modello
- Cosa è la cross-validazione nel machine learning
A presto!
Andrea





Commenti dalla community