
Il desiderio di qualsiasi ricercatore è quello di poter avere dati sull’intera popolazione oggetto di studio.
Studiare la popolazione intera permette al ricercatore di ottenere una comprensione completa del fenomeno in esame, poiché ciò consente di raccogliere informazioni su tutti gli individui che compongono la popolazione.
Tuttavia, nella maggior parte dei casi, questo obiettivo è irrealizzabile, sia per motivi pratici che teorici.
Ad esempio, in molti casi è impossibile individuare e contattare tutti gli individui appartenenti a una popolazione, o la raccolta di dati sull'intera popolazione sarebbe troppo costosa o richiederebbe troppo tempo.
Per questo motivo, è spesso necessario utilizzare un campione come approssimazione della popolazione.
In questo articolo parleremo di cosa sia il campionamento statistico, perché è importante per qualsiasi analista (che faccia analisi dati o machine learning) e alcune tecniche più utilizzate proprio per stimare la popolazione date delle informazioni di partenza.
Cosa è un campione
Un campione è un sottoinsieme della popolazione che si intende studiare. A differenza della popolazione, che rappresenta l'intero gruppo di individui o oggetti che si desidera analizzare, il campione rappresenta solo una porzione di esso.
L'utilizzo di un campione è importante perché può essere più pratico e conveniente raccogliere dati su un gruppo più piccolo e rappresentativo di individui, piuttosto che sulla popolazione intera.
Perché è difficile studiare una popolazione?
Le motivazioni possono essere innumerevoli, ma alcune delle più comuni sono
- la popolazione è troppo grande per poter essere presa tutta in esame
- mancanza di risorse, come tempo e denaro, per raccogliere dati su tutta la popolazione
- difficoltà a individuare tutti gli individui appartenenti alla popolazione
- impossibilità di raccogliere dati su alcuni individui, ad esempio a causa di malattie o inaccessibilità di altro tipo
E molto altri aspetti che dipendono dal progetto del ricercatore.
In questi casi, il campionamento statistico diventa una soluzione pratica ed efficiente per stimare le caratteristiche della popolazione. Una volta raccolti i dati dal campione, è possibile utilizzarli per fare inferenze sulla popolazione più ampia, utilizzando tecniche di stima e di ricampionamento.
Cosa significa campione “rappresentativo”?
Un campione rappresentativo è un sottoinsieme della popolazione che è stato scelto in modo tale da avere le stesse caratteristiche della popolazione nella sua interezza.
Un campione rappresentativo è quello che riflette accuratamente la distribuzione delle caratteristiche della popolazione di riferimento.
Durante la fase di raccolta dati, che sia attraverso il web scraping oppure la somministrazione di un questionario, è importante che il ricercatore sia sensibile e attento agli individui che include all’interno dell’esperimento.
La maggior parte delle volte il ricercatore non avrà alcuna idea di come sia distribuita la popolazione, quindi dovrà utilizzare delle tecniche di campionamento, come ad esempio quello casuale, che cerca di garantire che ogni individuo della popolazione abbia la stessa probabilità di essere incluso nel campione. In questo modo, il campione sarà rappresentativo della popolazione e le inferenze fatte sui dati del campione saranno valide per la popolazione più ampia.
Ma non è così semplice, poiché l'unico modo empirico che il ricercatore ha per validare le sue tecniche di campionamento è attraverso l'osservazione e la sperimentazione.
Fattori che impattano il campionamento
Ecco una lista di fattori che impattano la qualità del campionamento e la sua proprietà di approssimare correttamente la popolazione di riferimento:
- La popolazione di riferimento: la scelta del campione dipende dalla conoscenza della popolazione di riferimento, cioè il gruppo di persone, oggetti, eventi o dati da cui si intende estrarre il campione.
- Il metodo di campionamento: esistono diversi metodi di campionamento, tra cui il campionamento casuale semplice, il campionamento stratificato, il campionamento a grappoli, il campionamento sistematico e il campionamento basato su quote. La scelta del metodo dipende dalle caratteristiche della popolazione e dagli obiettivi dello studio.
- La dimensione del campione: la dimensione del campione dipende dal livello di precisione e dall'affidabilità richiesti per le stime. In generale, maggiore è la dimensione del campione, maggiore è la precisione delle stime. Questo perché si approssima sempre di più la popolazione di riferimento a mano a mano che il numero di individui del campione aumenta.
- Criteri di inclusione: i criteri di inclusione utilizzati possono influenzare la rappresentatività del campione e l'accuratezza delle stime. È importante utilizzare tecniche di selezione appropriate e di evitare bias di selezione.
- La modalità di raccolta dei dati: la modalità di raccolta dei dati (ad esempio, interviste telefoniche, questionari online, osservazioni sul campo) può influire sulla qualità dei dati e sulla rappresentatività del campione.
- La durata del periodo di raccolta dei dati: la durata del periodo di raccolta dei dati può influenzare la rappresentatività del campione, in quanto le caratteristiche della popolazione possono variare nel tempo.
Tecniche di campionamento
Vedremo ora una lista di tecniche di campionamento a disposizione del ricercatore per approssimare la popolazione.
- casuale
- stratificato
- sistematico
- per quote
- bootstrapping
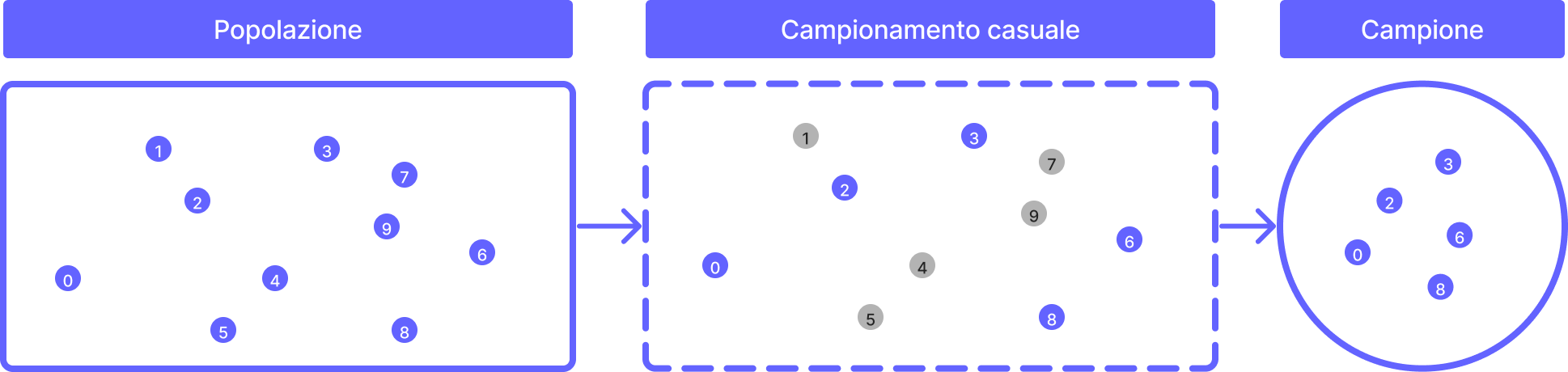
Campionamento casuale
Il campionamento casuale semplice è una delle tecniche di campionamento più utilizzate e prevede la selezione casuale degli individui della popolazione, in modo tale che ogni individuo abbia la stessa probabilità di essere incluso nel campione.
Questa tecnica di campionamento è utile quando la popolazione è omogenea e non ci sono ragioni per suddividerla in gruppi. Inoltre, il campionamento casuale semplice è relativamente facile da implementare e non richiede conoscenze specialistiche.
Il campionamento casuale semplice ha tuttavia alcuni limiti, come la difficoltà di garantire la rappresentatività del campione quando la popolazione è altamente eterogenea.
In questo caso è importante avere conoscenza specifica del dominio (domain knowledge) per comprendere e affrontare correttamente questi fenomeni.
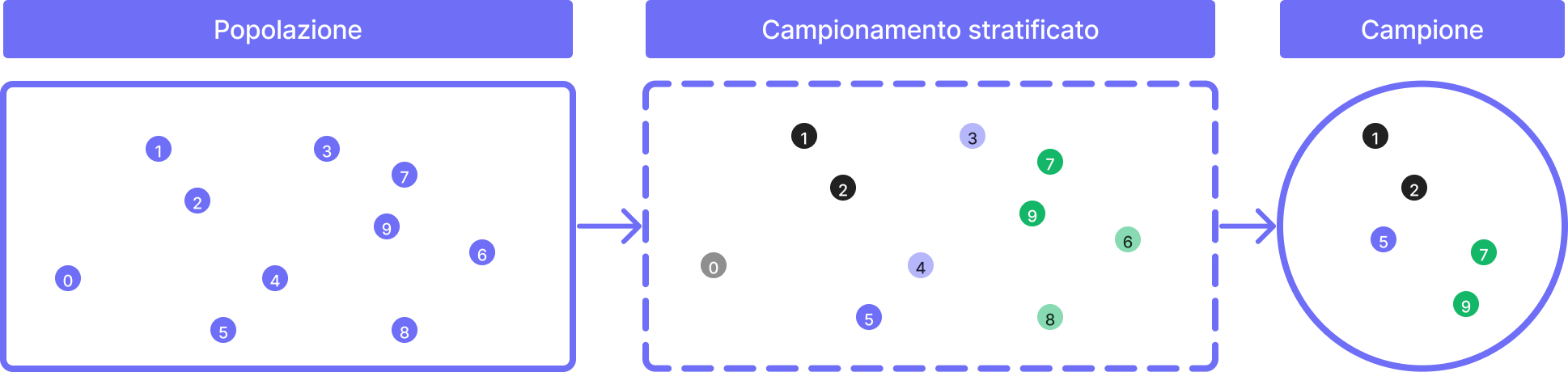
Campionamento stratificato
Il campionamento stratificato è una tecnica di campionamento che prevede la suddivisione della popolazione in gruppi omogenei, chiamati strati, in base a una o più caratteristiche.
Una volta definiti gli strati, si procede a selezionare un campione casuale semplice all'interno di ciascuno strato.
Questa tecnica è utile quando la popolazione presenta eterogeneità nelle caratteristiche di interesse e si vuole garantire che ogni strato venga rappresentato adeguatamente nel campione.
Ad esempio, se si vuole studiare la soddisfazione dei clienti di un'azienda in diverse regioni, si potrebbe suddividere la popolazione in base alla regione di provenienza e selezionare un campione casuale semplice di clienti da ciascuna regione.
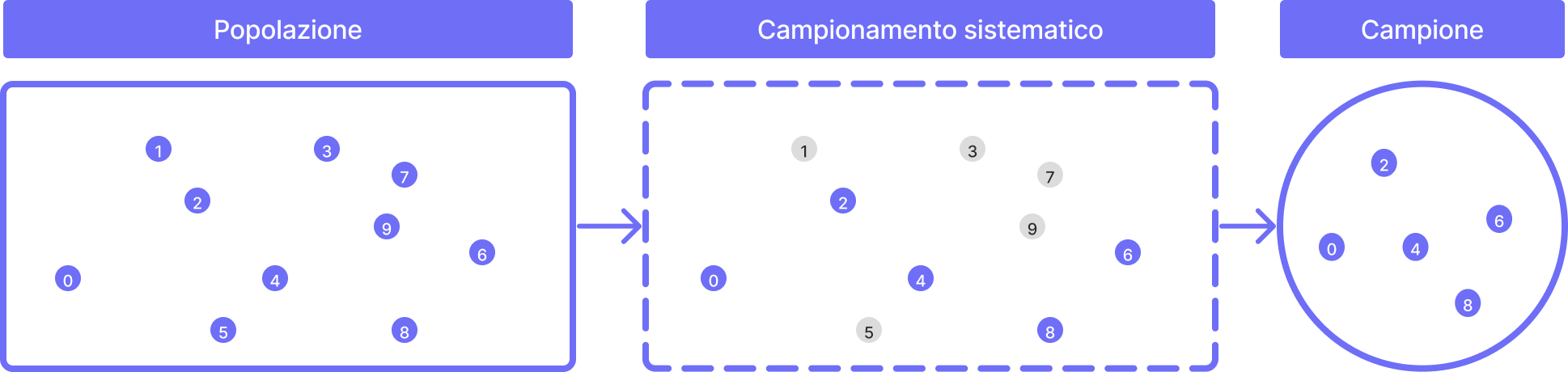
Campionamento sistematico
l campionamento sistematico è un metodo di campionamento probabilistico in cui gli elementi della popolazione sono disposti in un elenco ordinato e viene selezionato un elemento ogni k-esimo elemento (ad esempio, ogni decimo elemento) a partire da un punto di partenza casuale.
Questo metodo di campionamento viene utilizzato quando l'elenco degli elementi della popolazione è già disponibile e viene richiesta una selezione casuale di un campione.
Il campionamento sistematico è utile quando la popolazione è grande e l'individuazione di ogni singolo individuo richiederebbe troppo tempo o risorse. Tuttavia, il campionamento sistematico può essere soggetto a bias se l'intervallo tra gli individui scelti coincide con un particolare pattern nella popolazione.
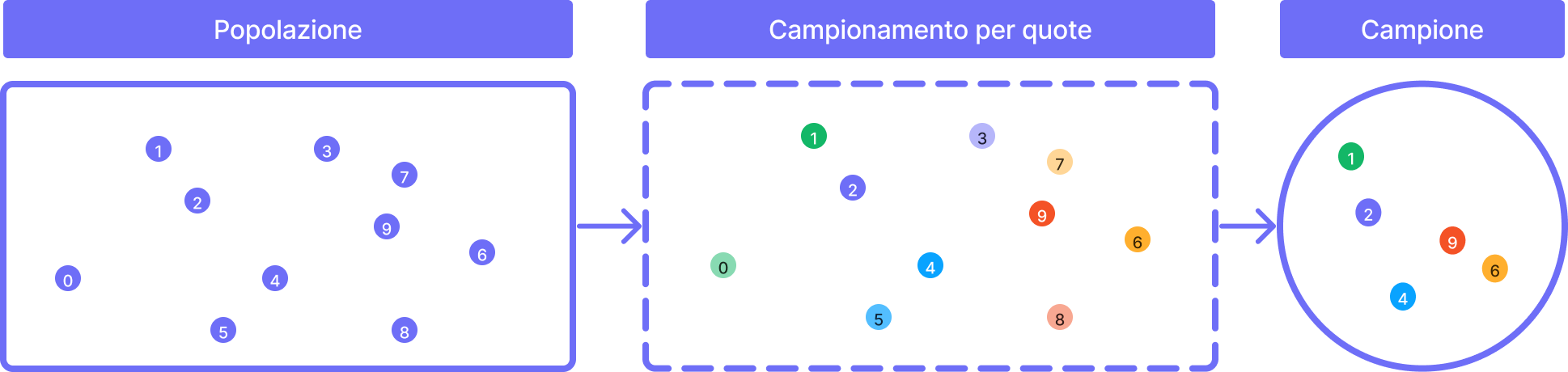
Campionamento per quote
Il campionamento per quote è un metodo di campionamento non probabilistico in cui vengono selezionati i soggetti per il campione in modo da ottenere una rappresentazione proporzionale delle caratteristiche della popolazione di riferimento.
In questo metodo, la popolazione viene suddivisa in categorie o "quote" sulla base di alcune caratteristiche di interesse (ad esempio, genere, età, istruzione, regione geografica) e viene determinato il numero di soggetti da selezionare per ogni quota sulla base delle proporzioni della popolazione.
La selezione dei soggetti all'interno di ogni quota può essere effettuata utilizzando un metodo di campionamento casuale o non casuale, a seconda delle esigenze dello studio.
Il vantaggio del campionamento per quote è che permette di ottenere un campione che rappresenta proporzionalmente le caratteristiche della popolazione di riferimento, anche se la scelta dei soggetti all'interno di ogni quota non è effettuata in modo casuale.
Questo metodo di campionamento è spesso utilizzato in sondaggi di opinione, poiché consente di raggiungere un campione rappresentativo in modo relativamente rapido ed economico. Tuttavia, il campionamento per quote può essere influenzato dalla conoscenza e dalle opinioni del selezionatore che sceglie i soggetti per il campione, e può quindi essere soggetto a bias di selezione.
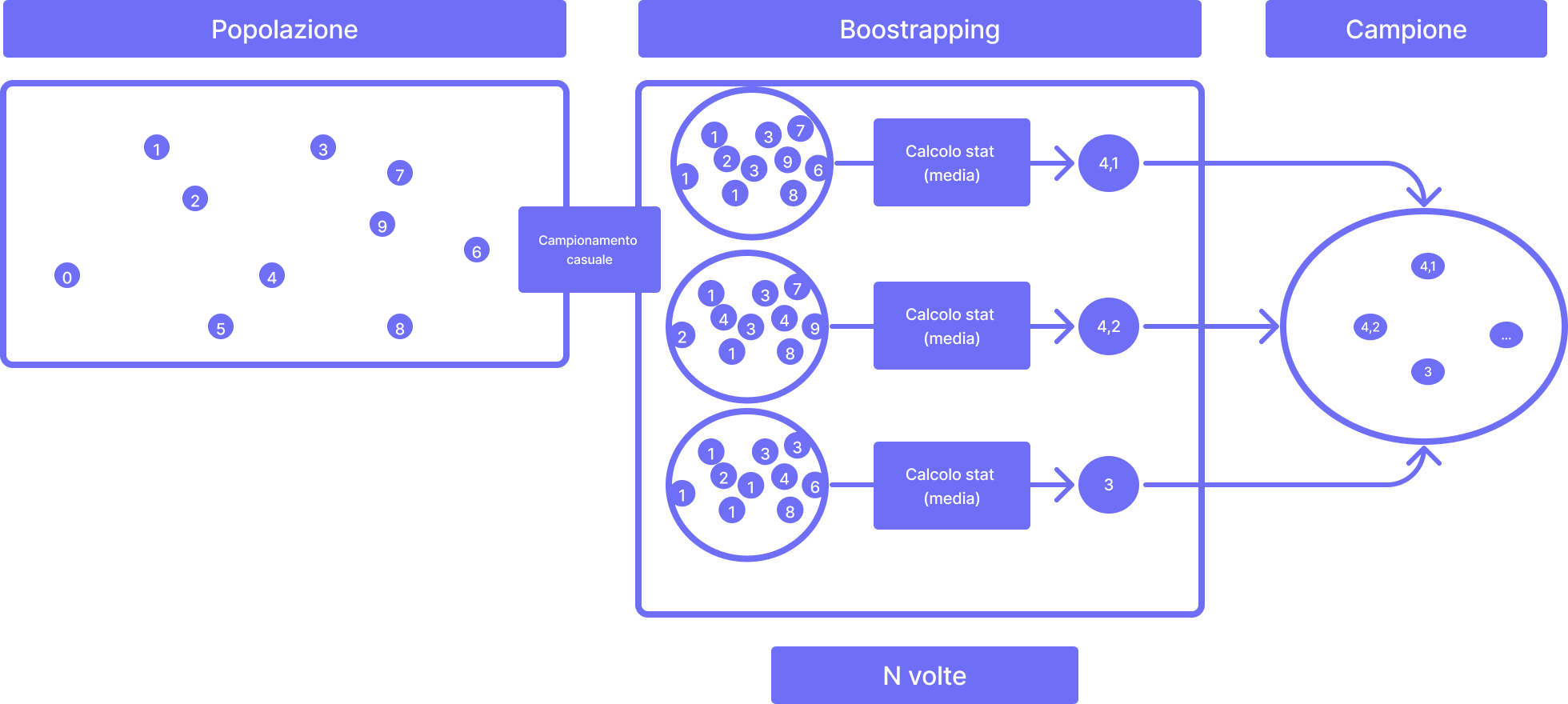
Bootstrapping
Il bootstrapping è una tecnica di ricampionamento che permette di approssimare la popolazione andando a selezionare casualmente con sostituzione un certo numero di elementi dalla popolazione per generare un campione.
Questo processo viene ripetuto molte volte, in modo tale da creare una grossa quantità di campioni. Da questi campioni viene estratta una qualsivoglia statistica (come la media o la mediana) e questa diventa parte del campione finale che andrà ad approssimare la popolazione.
Il bootstrapping è utile quando si desidera stimare la precisione di una statistica campionaria o di un modello di machine learning. Invece di fare supposizioni sulla distribuzione della popolazione, il bootstrapping utilizza la distribuzione dei campioni sintetici per stimare l'errore standard e gli intervalli di confidenza.
Il bootstrapping è particolarmente utile quando la distribuzione della popolazione è sconosciuta o quando non è possibile ottenere campioni ripetuti dalla popolazione originale.
Conclusione
In questo articolo abbiamo visto come il campionamento statistico sia un concetto fondamentale durante il processo di ricerca.
Abbiamo visto come il campionamento può aiutare a ottenere informazioni sulla popolazione di interesse con un'efficienza maggiore rispetto alla raccolta di dati sull'intera popolazione, in base alle conoscenze del ricercatore nel dominio di riferimento e ai vari bias alla quale è esposto.
Abbiamo anche discusso delle tecniche di campionamento più utilizzate, tra cui il campionamento casuale, quello stratificato, quello sistematico e per quote, nonché la tecnica del bootstrapping.
Infine, abbiamo sottolineato l'importanza di una corretta definizione della popolazione di riferimento e della scelta del metodo di campionamento più appropriato per gli obiettivi dello studio.





Commenti dalla community