
Nella analisi dei dati, identificare anomalie (outlier detection) è un tema cruciale che può fornire parecchie informazioni importanti.
In questo articolo ci concentreremo sui metodi e tecniche utilizzati per identificare le anomalie nei dati. In particolare, esploreremo tecniche di visualizzazione dei dati e l'utilizzo di statistiche descrittive e test statistici.
La definizione di anomalia
Una anomalia, spesso riferita come outlier dall’inglese, è un valore che si discosta significativamente dagli altri valori del dataset. Questo discostamento può essere numerico o anche categoriale.
Ad esempio, un discostamento numerico è quando abbiamo un valore molto più grande o molto più piccolo rispetto alla maggior parte degli altri valori all'interno del dataset.
Un discostamento categoriale, invece, si verifica quando abbiamo delle etichette note come "altro" o "sconosciuto" che rappresentano una proporzione molto più alta rispetto alle altre etichette all'interno del dataset.
Può essere causata da errori di misurazione, errori di input, errori di trascrizione o semplicemente da dati che non seguono il normale andamento del dataset.
In alcuni casi, le anomalie possono essere indicative di problemi più ampi nel dataset o nel processo che ha prodotto i dati e possono offrire informazioni importanti alle persone che hanno sviluppato il processo di raccolta dati.
Come identificare le anomalie in un set di dati
Ci sono diverse tecniche che puoi utilizzare per identificare le anomalie nei tuoi dati. Ecco quelle che toccheremo in questo articolo
- visualizzazione dei dati: che permette di identificare anomalie guardando la distribuzione dei dati facendo uso di grafici utili a tale scopo
- utilizzo di statistiche descrittive, come la differenza interquartilica
- utilizzo di score z
- utilizzo di tecniche di clustering: che permette di individuare gruppi di dati simili e di identificare eventuali dati "isolati" o "non classificabili"
ognuno di questi metodi è valido per identificare le anomalie, e vanno scelti in base ai nostri dati. Vediamone uno per uno.
Visualizzazione dei dati
Una delle tecniche più comuni per trovare anomalie è attraverso l’analisi esplorativa dei dati e in particolare con la visualizzazione dei dati.
Utilizzando Python, puoi utilizzare librerie come Matplotlib o Seaborn per visualizzare i dati in modo tale da poter individuare facilmente eventuali anomalie.
Ad esempio, è possibile creare un istogramma o un boxplot per visualizzare la distribuzione dei tuoi dati e individuare eventuali valori che si discostano significativamente dalla media.
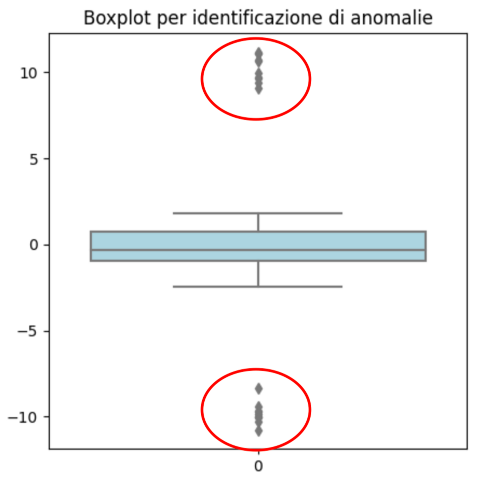
L’anatomia del boxplot può essere compresa da questo post su Kaggle.

Utilizzo di statistiche descrittive
Un altro metodo per individuare le anomalie è l’utilizzo di statistiche descrittive. Ad esempio, la differenza interquartilica (IQR) può essere utilizzata per identificare i valori che si discostano significativamente dalla media.
La differenza interquartilica (IQR) è definita come la differenza tra il terzo quartile (Q3) e il primo quartile (Q1) del dataset. Gli outlier sono definiti come i valori al di fuori dell'intervallo IQR moltiplicato per un coefficiente tipicamente di 1,5.
Il boxplot precedentemente trattato è proprio un metodo che utilizza tale metrica descrittiva per identificare le anomalie.
Un esempio in Python per identificare gli outlier utilizzando la differenza interquartilica è il seguente:
import numpy as np
def find_outliers_IQR(data, threshold=1.5):
# Calcola il primo e il terzo quartile
Q1, Q3 = np.percentile(data, [25, 75])
# Calcola l'IQR
IQR = Q3 - Q1
# Calcola la soglia inferiore e superiore
lower_bound = Q1 - (threshold * IQR)
upper_bound = Q3 + (threshold * IQR)
# Identifica gli outlier
outliers = [x for x in data if x < lower_bound or x > upper_bound]
return outliersQuesto metodo calcola il primo e il terzo quartile del dataset, poi calcola l'IQR e la soglia inferiore e superiore. Infine, identifica gli outlier come quei valori che sono al di fuori della soglia inferiore e superiore.
Questa comoda funzione può essere utilizzata per identificare gli outlier in un dataset e può essere aggiunta al tuo toolkit di funzioni util in pressoché qualsiasi progetto.

Utilizzo di score z
Un altro modo per individuare le anomalie è attraverso dei punteggi z. Gli score z misurano quanto un valore si discosta dalla media in termini di deviazioni standard.
La formula per convertire i dati in punteggi z è la seguente:
\[ z = \frac{x - \mu}{\sigma} \]
dove \( x \) è il valore originale, \( \mu \) è la media del dataset e \( \sigma \) è la deviazione standard del dataset. Il punteggio z indica quanti deviazioni standard il valore originale è distante dalla media. Un valore di punteggio z superiore a 3 (o inferiore a -3) è generalmente considerato un outlier.
Questo metodo è particolarmente utile quando si lavora con grandi dataset e quando si vuole identificare anomalie in modo oggettivo e riproducibile.
In sklearn in Python, la conversione in punteggi z può essere fatta così
from sklearn.preprocessing import StandardScaler
def find_outliers_zscore(data, threshold=3):
# Standardizza i dati
scaler = StandardScaler()
standardized = scaler.fit_transform(data.reshape(-1, 1))
# Identifica gli outlier
outliers = [data[i] for i, x in enumerate(standardized) if x < -threshold or x > threshold]
return outliers
Utilizzo di tecniche di clustering
Infine, le tecniche di clustering possono essere utilizzate per individuare eventuali dati "isolati" o "non classificabili". Questo può essere utile quando si lavora con dataset molto grandi e complessi, dove la visualizzazione dei dati non è sufficiente per individuare le anomalie.
In questo caso, un'opzione è di utilizzare l'algoritmo DBSCAN (Density-Based Spatial Clustering of Applications with Noise), che è un algoritmo di clustering che può identificare gruppi di dati in base alla loro densità e individuare eventuali punti che non appartengono a nessun cluster. Questi punti sono considerati come anomalie.
L'algoritmo DBSCAN può essere implementato sempre con sklearn di Python e può essere utilizzato per identificare anomalie in un set di dati.
Prendiamo ad esempio questo dataset visualizzato
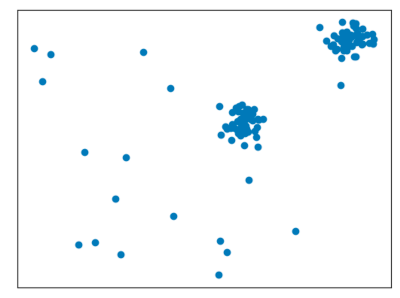
L’applicazione di DBSCAN fornisce questa visualizzazione

Il codice per creare questi grafici è il seguente
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
def generate_data_with_outliers(n_samples=100, noise=0.05, outlier_fraction=0.05, random_state=42):
# Genera dati casuali
X = np.concatenate([np.random.normal(0.5, 0.1, size=(n_samples//2, 2)),
np.random.normal(1.5, 0.1, size=(n_samples//2, 2))], axis=0)
# Aggiungi outlier
n_outliers = int(outlier_fraction * n_samples)
outliers = np.random.RandomState(seed=random_state).rand(n_outliers, 2) * 3 - 1.5
X = np.concatenate((X, outliers), axis=0)
# Aggiungi rumore ai dati per renderli verosimili
X = X + np.random.randn(n_samples + n_outliers, 2) * noise
return X
# Genera dati con outlier
X = generate_data_with_outliers(outlier_fraction=0.2)
# Applica DBSCAN per trovare cluster e outlier
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan.fit(X)
# Ottieni gli indici dei punti outlier
outlier_indices = np.where(dbscan.labels_ == -1)[0]
# Visualizza dati e outlier
plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_, cmap="viridis")
plt.scatter(X[outlier_indices, 0], X[outlier_indices, 1], c="red", label="Outliers", marker="x")
plt.xticks([])
plt.yticks([])
plt.legend()
plt.show()Questo metodo crea un oggetto DBSCAN con i parametri eps e min_samples e lo adatta ai dati. Quindi identifica gli outlier come quei valori che non appartengono a nessun cluster, cioè quelli che sono etichettati come -1.
Questa è solo una delle molte tecniche di clustering che si possono utilizzare per identificare le anomalie. Ad esempio, un metodo basato sul deep learning si basa sugli autoencoder particolari reti neurali che sfruttano una rappresentazione compressa del dato per identificare caratteristiche distintive nei dati in input.
Conclusione
In questo articolo abbiamo visto diverse tecniche che possono essere utilizzate per identificare le anomalie nei dati.
Abbiamo parlato di visualizzazione dei dati, di utilizzo di statistiche descrittive e di score z, e di tecniche di clustering.
Ognuna di queste tecniche è valida e va scelta in base al tipo di dati che si sta analizzando. L'importante è ricordare che l'individuazione delle anomalie può fornire informazioni importanti per migliorare i processi di raccolta dati e per prendere decisioni migliori in base ai risultati ottenuti.





Commenti dalla community