
Una delle funzionalità più usate e apprezzate di Scikit-Learn sono le pipeline. Sebbene il loro utilizzo sia optional, quest'ultime possono essere utilizzate per rendere il nostro codice più pulito e facile da mantenere.
Le pipeline accettano come input degli estimators, che non sono altro che delle classi che si ereditano da sklearn.base.BaseEstimator e che contengono i metodi fit e transform. Questo ci permette di personalizzare le pipeline con funzionalità che Sklearn non offre di default.
Parleremo dei transformer, degli oggetti che applicano una trasformazione su un input. La classe dalla quale erediteremo è TransformerMixin, ma è possibile estendere anche da ClassifierMixin , RegressionMixin, ClusterMixin e altri per creare un estimator personalizzato. Leggere qui per tutte le opzioni disponibili.
Lavoreremo con un dataset di dati testuali, sulla quale vogliamo applicare delle trasformazioni quali:
- preprocessing del testo
- vettorizzazione con TF-IDF
- creazione di feature aggiuntive a scopo di esempio come sentiment, numero di caratteri, numero di frasi
Questo verrà fatto attraverso l'utilizzo di Pipeline e FeatureUnion, una classe di Sklearn che unisce i feature set provenienti da diverse sorgenti.
- Importare un dataset da Sklearn
- Creare feature testuali e numeriche
- Usare BaseEstimator, TransformerMixin e FeatureUnion per creare una pipeline personalizzata di feature engineering
Alla fine del progetto avrai a disposizione del codice da poter riutilizzare nel tuo progetto, qualsiasi esso sia.
Iniziamo subito!
Il Dataset
Useremo il dataset fornito da Sklearn, 20newsgroups, per avere rapido accesso ad un corpus di dati testuali. A scopo dimostrativo, userò solo un campione di 10 testi ma l'esempio può essere esteso a qualsiasi numero di testi.
Importiamo il dataset con Python
# librerie essenziali per il nostro esempio
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import FeatureUnion, Pipeline
import nltk
from nltk.corpus import stopwords
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('vader_lexicon')
import re
# categorie usate per estrarre i testi da 20newsgroups
categories = [
'comp.graphics',
'comp.os.ms-windows.misc',
'rec.sport.baseball',
'rec.sport.hockey',
'alt.atheism',
'soc.religion.christian',
]
dataset = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, remove=('headers', 'footers', 'quotes'))
df = pd.DataFrame(dataset.data, columns=["corpus"]).sample(10) # <-- prendiamo solo 10 elementi dal corpusCreazione di feature testuali
Costruiremo il feature set conterrà queste informazioni
- vettorizzazione con TF-IDF dopo aver applicato preprocessing
- sentiment con NLTK.Vader
- numero di caratteri nel testo
- numero di frasi nel testo
Il nostro processo, senza usare pipeline, sarebbe quello di applicare sequenzialmente tutti questi step con blocchi di codice separato. La bellezza delle pipeline è che la sequenzialità viene mantenuta in un solo blocco di codice - la pipeline stessa diventa un estimator, in grado di eseguire tutte le operazioni programmate in una sola istruzione.
Creiamo le nostre funzioni
def preprocess_text(text: str, remove_stopwords: bool) -> str:
"""Funzione che pulisce il testo in input andando a
- rimuovere i link
- rimuovere i caratteri speciali
- rimuovere i numeri
- rimuovere le stopword
- trasformare in minuscolo
- rimuovere spazi bianchi eccessivi
Argomenti:
text (str): testo da pulire
remove_stopwords (bool): rimuovere o meno le stopword
Restituisce:
str: testo pulito
"""
# rimuovi link
text = re.sub(r"http\S+", "", text)
# rimuovi numeri e caratteri speciali
text = re.sub("[^A-Za-z]+", " ", text)
# rimuovere le stopword
if remove_stopwords:
# 1. crea token
tokens = nltk.word_tokenize(text)
# 2. controlla se è una stopword
tokens = [w for w in tokens if not w.lower() in stopwords.words("english")]
# 3. unisci tutti i token
text = " ".join(tokens)
# restituisci il testo pulito, senza spazi eccessivi, in minuscolo
text = text.lower().strip()
return text
def get_sentiment(text: str):
"""
Funzione che usa NLTK.Vader per estrarre il sentiment.
Il sentiment è un punteggio esprime quanto un testo sia positivo o negativo.
Il valore va da -1 a 1, dove 1 è il valore più positivo.
Argomenti:
text (str): testo da analizzare
Restituisce:
sentiment (float): polarità del testo
"""
vader = SentimentIntensityAnalyzer()
return vader.polarity_scores(text)['compound']
def get_nchars(text: str):
"""
Funzione che restituisce il numero di caratteri in un testo.
Argomenti:
text (str): testo da analizzare
Restituisce:
n_chars (int): numero di caratteri
"""
return len(text)
def get_nsentences(text: str):
"""
Funzione che restituisce il numero di frasi in un testo.
Argomenti:
text (str): testo da analizzare
Restituisce:
n_sentences (int): numero di frasi
"""
return len(text.split("."))Il nostro obiettivo è quello di creare un feature set unico in modo da addestrare un modello su un qualche task. Useremo le Pipeline e FeatureUnion per mettere insieme le nostre matrici.
Come unire le feature provenienti da sorgenti diverse
La vettorizzazione TF-IDF creerà una matrice sparsa che avrà dimensioni \( n\_documenti\_nel\_corpus \times n\_features \), il sentiment sarà un singolo numero, come anche l'output di n_chars e n_sentences. Andremo a prendere gli output di ognuno di questi step e a creare una matrice singola che li conterrà tutti, in modo da poter addestrare un modello su tutte le feature che abbiamo ingegnerizzato. Partiremo da una rappresentazione del genere

Fino a giungere a questo
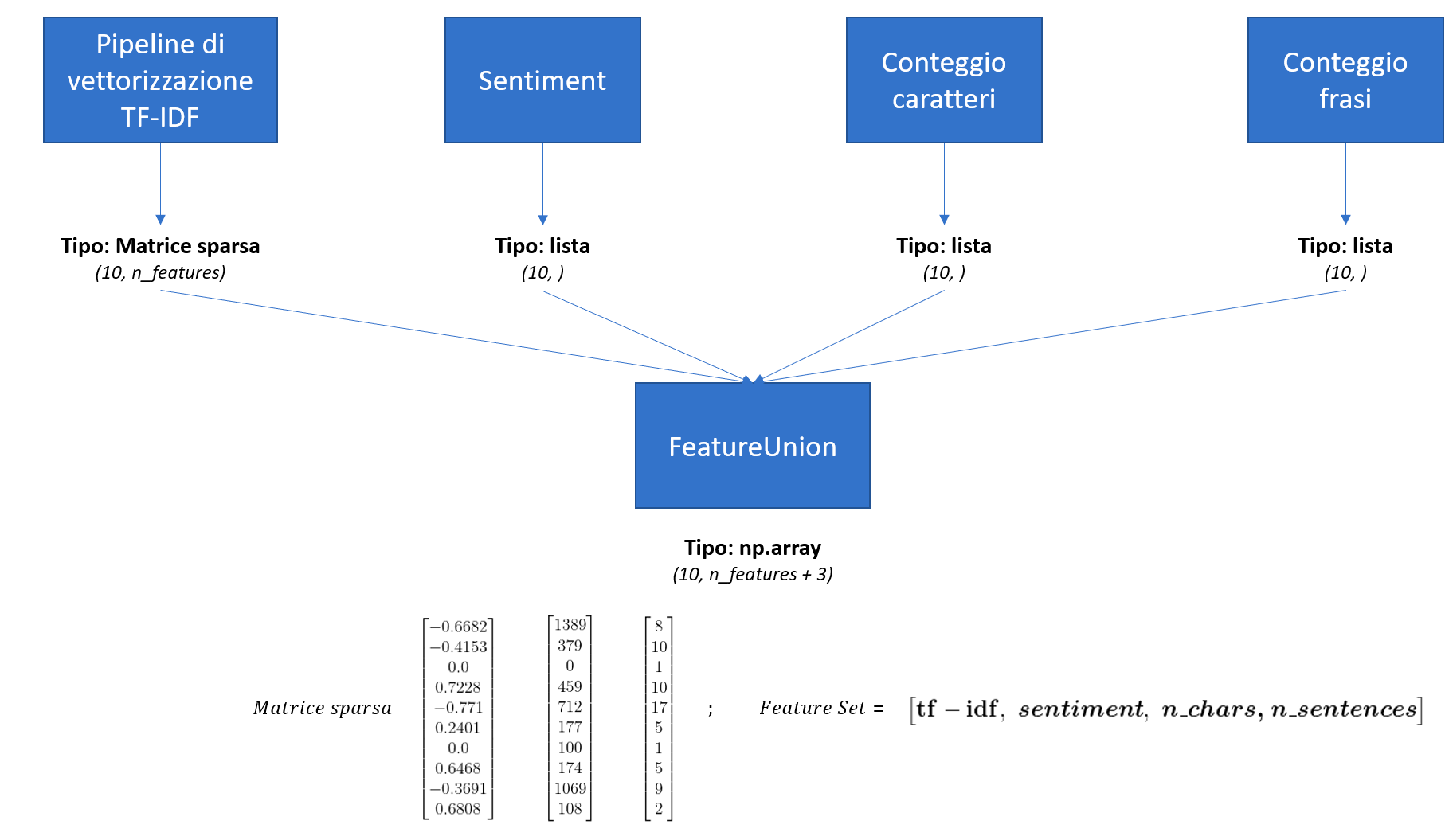
Il feature set verrà usato come vettore di addestramento del nostro modello.
Classi che ereditano da BaseEstimator e TransformerMixin
Per poter mettere giù il nostro processo, occorre definire le classi e cosa faranno nella pipeline. Iniziamo col creare un DummyEstimator, dal quale andremo ad ereditare init, fit e transform. Il DummyEstimator è una classe comoda che ci evita la scrittura di diverso codice.
class DummyTransformer(BaseEstimator, TransformerMixin):
"""
Classe "fantoccio" - ci permette di modificare solo i metodi che ci interessano,
evitando riscritture.
"""
def __init__(self):
return None
def fit(self, X=None, y=None):
return self
def transform(self, X=None):
return selfDummyEstimator sarà ereditato da quattro classi, Preprocessor, SentimentAnalysis, NChars, NSentences e FromSparseToArray.
class Preprocessor(DummyTransformer):
"""
Classe che si occupa del preprocessing del testo
"""
def __init__(self, remove_stopwords: bool):
self.remove_stopwords = remove_stopwords
return None
def transform(self, X=None):
preprocessed = X.apply(lambda x: preprocess_text(x, self.remove_stopwords)).values
return preprocessed
class SentimentAnalysis(DummyTransformer):
"""
Classe che si occupa di generare il sentiment
"""
def transform(self, X=None):
sentiment = X.apply(lambda x: get_sentiment(x)).values
return sentiment.reshape(-1, 1) # <-- da notare il reshape per trasformare un vettore riga in uno colonna
class NChars(DummyTransformer):
"""
Classe che si occupa di contare i caratteri in un testo
"""
def transform(self, X=None):
n_chars = X.apply(lambda x: get_nchars(x)).values
return n_chars.reshape(-1, 1)
class NSententences(DummyTransformer):
"""
Classe che si occupa di contare le frasi in un testo
"""
def transform(self, X=None):
n_sentences = X.apply(lambda x: get_nsentences(x)).values
return n_sentences.reshape(-1, 1)
class FromSparseToArray(DummyTransformer):
"""
Classe che si occupa trasformare una matrice sparsa in un array numpy
"""
def transform(self, X=None):
arr = X.toarray()
return arrCom'è possibile vedere, DummyEstimator ci permette di definire solo la funzione transform, poiché ogni altra classe eredita init e fit proprio da DummyEstimator.
Vediamo ora come implementare la pipeline di vettorizzazione, che terrà conto del preprocessing dei nostri testi.
vectorization_pipeline = Pipeline(steps=[
('preprocess', Preprocessor(remove_stopwords=True)), # il primo step della pipeline è di preprocessare il corpus
('tfidf_vectorization', TfidfVectorizer()), # il secondo step vettorizza il testo preparato dallo step 1
('arr', FromSparseToArray()), # il terzo step converte una matrice sparsa in un array numpy per poterlo mostrare in un dataframe
])Non resta che applicare FeatureUnion per mettere insieme i pezzi
features = [
('vectorization', vectorization_pipeline),
('sentiment', SentimentAnalysis()),
('n_chars', NChars()),
('n_sentences', NSententences())
]
combined = FeatureUnion(features) # qui è dove mettiamo insieme le nostre feature
combined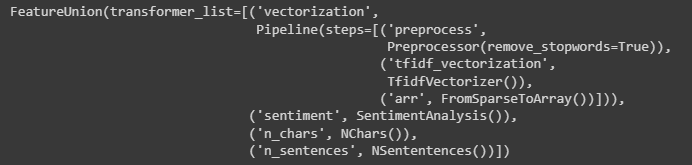
Applichiamo fit_transform sul nostro corpus e vediamo l'output
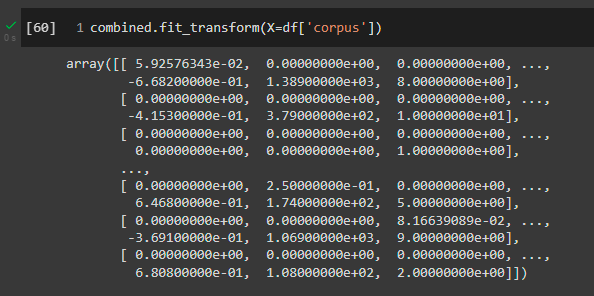
L'output sembra essere corretto! Non è molto chiaro, però. Concludiamo il tutorial con l'inserimento in dataframe del feature set combinato
# qui puntiamo al secondo step del secondo oggetto nella vectorization_pipeline per reperire i termini generati dal tf-idf
# ai quali poi andiamo ad aggiungere le altre tre colonne
cols = vectorization_pipeline.steps[1][1].get_feature_names() + ["sentiment", "n_chars", "n_sentences"]
features_df = pd.DataFrame(combined.transform(df['corpus']), columns=cols)Il risultato è il seguente (qui ho troncato il risultato per questioni di leggibilità)
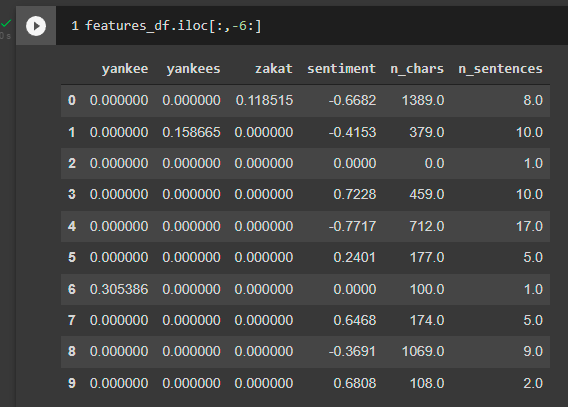
Ora abbiamo un dataset pronto per essere fornito a qualsiasi modello per addestramento. Sarebbe utile sperimentare con StandardScaler o simili e normalizzare n_chars e n_sentences. Lascerò questo esercizio al lettore.
Codice
# librerie essenziali per il nostro esempio
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import FeatureUnion, Pipeline
import nltk
from nltk.corpus import stopwords
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('vader_lexicon')
import re
# categorie usate per estrarre i testi da 20newsgroups
categories = [
'comp.graphics',
'comp.os.ms-windows.misc',
'rec.sport.baseball',
'rec.sport.hockey',
'alt.atheism',
'soc.religion.christian',
]
dataset = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, remove=('headers', 'footers', 'quotes'))
df = pd.DataFrame(dataset.data, columns=["corpus"]).sample(10) # <-- prendiamo solo 10 elementi dal corpus
vectorization_pipeline = Pipeline(steps=[
('preprocess', Preprocessor(remove_stopwords=True)), # il primo step della pipeline è di preprocessare il corpus
('tfidf_vectorization', TfidfVectorizer()), # il secondo step vettorizza il testo preparato dallo step 1
('arr', FromSparseToArray()), # il terzo step converte una matrice sparsa in un array numpy per poterlo mostrare in un dataframe
])
features = [
('vectorization', vectorization_pipeline),
('sentiment', SentimentAnalysis()),
('n_chars', NChars()),
('n_sentences', NSententences())
]
combined = FeatureUnion(features) # qui è dove mettiamo insieme le nostre feature
# qui puntiamo al secondo step del secondo oggetto nella vectorization_pipeline per reperire i termini generati dal tf-idf
# ai quali poi andiamo ad aggiungere le altre tre colonne
cols = vectorization_pipeline.steps[1][1].get_feature_names() + ["sentiment", "n_chars", "n_sentences"]
features_df = pd.DataFrame(combined.transform(df['corpus']), columns=cols)class DummyTransformer(BaseEstimator, TransformerMixin):
"""
Classe "fantoccio" - ci permette di modificare solo i metodi che ci interessano,
evitando riscritture.
"""
def __init__(self):
return None
def fit(self, X=None, y=None):
return self
def transform(self, X=None):
return self
class Preprocessor(DummyTransformer):
"""
Classe che si occupa del preprocessing del testo
"""
def __init__(self, remove_stopwords: bool):
self.remove_stopwords = remove_stopwords
return None
def transform(self, X=None):
preprocessed = X.apply(lambda x: preprocess_text(x, self.remove_stopwords)).values
return preprocessed
class SentimentAnalysis(DummyTransformer):
"""
Classe che si occupa di generare il sentiment
"""
def transform(self, X=None):
sentiment = X.apply(lambda x: get_sentiment(x)).values
return sentiment.reshape(-1, 1) # <-- da notare il reshape per trasformare un vettore riga in uno colonna
class NChars(DummyTransformer):
"""
Classe che si occupa di contare i caratteri in un testo
"""
def transform(self, X=None):
n_chars = X.apply(lambda x: get_nchars(x)).values
return n_chars.reshape(-1, 1)
class NSententences(DummyTransformer):
"""
Classe che si occupa di contare le frasi in un testo
"""
def transform(self, X=None):
n_sentences = X.apply(lambda x: get_nsentences(x)).values
return n_sentences.reshape(-1, 1)
class FromSparseToArray(DummyTransformer):
"""
Classe che si occupa trasformare una matrice sparsa in un array numpy
"""
def transform(self, X=None):
arr = X.toarray()
return arr
view rawdef preprocess_text(text: str, remove_stopwords: bool) -> str:
"""Funzione che pulisce il testo in input andando a
- rimuovere i link
- rimuovere i caratteri speciali
- rimuovere i numeri
- rimuovere le stopword
- trasformare in minuscolo
- rimuovere spazi bianchi eccessivi
Argomenti:
text (str): testo da pulire
remove_stopwords (bool): rimuovere o meno le stopword
Restituisce:
str: testo pulito
"""
# rimuovi link
text = re.sub(r"http\S+", "", text)
# rimuovi numeri e caratteri speciali
text = re.sub("[^A-Za-z]+", " ", text)
# rimuovere le stopword
if remove_stopwords:
# 1. crea token
tokens = nltk.word_tokenize(text)
# 2. controlla se è una stopword
tokens = [w for w in tokens if not w.lower() in stopwords.words("english")]
# 3. unisci tutti i token
text = " ".join(tokens)
# restituisci il testo pulito, senza spazi eccessivi, in minuscolo
text = text.lower().strip()
return text
def get_sentiment(text: str):
"""
Funzione che usa NLTK.Vader per estrarre il sentiment.
Il sentiment è un punteggio esprime quanto un testo sia positivo o negativo.
Il valore va da -1 a 1, dove 1 è il valore più positivo.
Argomenti:
text (str): testo da analizzare
Restituisce:
sentiment (float): polarità del testo
"""
vader = SentimentIntensityAnalyzer()
return vader.polarity_scores(text)['compound']
def get_nchars(text: str):
"""
Funzione che restituisce il numero di caratteri in un testo.
Argomenti:
text (str): testo da analizzare
Restituisce:
n_chars (int): numero di caratteri
"""
return len(text)
def get_nsentences(text: str):
"""
Funzione che restituisce il numero di frasi in un testo.
Argomenti:
text (str): testo da analizzare
Restituisce:
n_sentences (int): numero di frasi
"""
return len(text.split(".")) 




Commenti dalla community