
Calcolare la similarità tra due testi è una attività molto utile nell'ambito del data mining e dell'elaborazione del linguaggio naturale (NLP, natural language processing). Questa permette sia di isolare anomalie, ad esempio testi molto simili tra di loro o molto diversi, e di raggruppare entità simili in categorie utili.
In questo articolo andremo ad utilizzare uno script pubblicato qui per scraperare un blog e creare un piccolo corpus su cui applicare un algoritmo di calcolo della similarità basato su TF-IDF in Python.
In particolare andremo ad utilizzare una libreria chiamata Trafilatura per recuperare dalla sitemap tutti gli articoli di un blog e li inseriremo in un dataframe Pandas per l'elaborazione.
Invito il lettore a leggere l'articolo che ho linkato sopra per comprendere come funziona l'algoritmo di estrazione più in dettaglio.
Per semplicità, nell'esempio andremo ad analizzare proprio diariodiunanalista.it al fine di comprendere se esistono articoli troppo simili tra di loro.
Questo ha notevoli ripercussioni SEO - infatti articoli simili tra di loro danno luogo al fenomeno della cannibalizzazione del contenuto: quando due pezzi appartenenti allo stesso sito web competono per la stessa posizione su Google.
I requisiti
Le librerie che ci serviranno saranno Pandas, Numpy, NLTK, Sklearn, TQDM, Matplotlib e Seaborn.
Importiamole nel nostro script Python.
import pandas as pd
import numpy as np
import nltk
from nltk.corpus import stopwords
import string
from tqdm import tqdm
import matplotlib.pyplot as plt
import seaborn as snsInoltre, servirà lanciare il comando nltk.download('stopwords') per installare e stopword di NLTK. Una stopword è una parola che non contribuisce in maniera importante al significato di una frase e ci serviranno per preprocessare i nostri testi.
Creazione del dataset
Andiamo ad eseguire il software creato nell'articolo menzionato sopra.
if __name__ == "__main__":
list_of_websites = [
"https://www.diariodiunanalista.it/",
]
df = create_dataset(list_of_websites)
df.to_csv("dataset.csv", index=False)
Andiamo a dare una occhiata al nostro dataset.
Dalla tassonomia delle URL notiamo come tutti i post siano raccolti sotto /posts/ - questo ci permette di isolare solo gli articoli veri e propri, tralasciando pagine, categorie, tag e altro.
Usiamo il seguente codice per applicare questa selezione
posts = df[df.url.str.contains('post')]
posts.reset_index(inplace=True)
Abbiamo il nostro corpus. Al momento di scrittura di questo pezzo stiamo intorno a 30 articoli - si tratta quindi di un corpus molto piccolo. Andrà comunque bene per il nostro esempio.
Preprocessing dei testi
Applicheremo un minimo di preprocessing dei testi per replicare una pipeline reale di applicazione. Questa può essere espansa per integrare i requisiti del lettore.
Step di preprocessing
Andremo ad applicare questi step di preprocessing:
- rimozione punteggiatura
- applicazione di minuscole
Il tutto verrà fatto in una funzione molto semplice, che utilizza la libreria standard string e NLTK.
Questa funzione verrà utilizzata dal vettorizzatore TF-IDF (che definiremo a breve) per normalizzare il testo.
L'algoritmo di calcolo della similarità
Per prima cosa, andiamo a definire le nostre stopword salvandole in una variabile
ita_stopwords = stopwords.words('italian')
Ora importiamo TfIdfVectorizer da Sklearn, passandogli la funzione di preprocessing e le stopword.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=preprocess, stop_words=ita_stopwords)Il vettorizzatore TF-IDF andrà a convertire ogni testo in una rappresentazione vettoriale dello stesso. Questo ci consentirà di trattare ogni testo come una serie di punti in uno spazio multidimensionale.
Il modo in cui andremo a calcolare la similarità sarà attraverso la computazione del coseno tra i vettori che costituiscono i testi che mettiamo a confronto. Il valore di similitudine è compreso tra -1 e +1. Un valore di +1 indica due testi essenzialmente uguali, mentre invece -1 indica una completa dissociazione.
Invito il lettore interessato a leggere di più sull'argomento sulla pagina Wikipedia dedicata.
Definiamo una funzione chiamata compute_similarity che userà il vettorizzatore per convertire i testi in numero e applica la funzione per calcolare il coseno di similarità con i vettori TF-IDF.
def compute_similarity(a, b):
tfidf = vectorizer.fit_transform([a, b])
return ((tfidf * tfidf.T).toarray())[0,1]Testiamo il funzionamento
Prendiamo in esempio due testi presi da Wikipedia.
Figlio secondogenito del giudice sardo Ugone II di Arborea e di Benedetta, proseguì e intensificò l'eredità culturale e politica del padre, volta al mantenimento dell'autonomia del giudicato di Arborea e alla sua indipendenza, che ampliò all'intera Sardegna. Considerato una delle più importanti figure nel '300 sardo, contribuì allo sviluppo dell'organizzazione agricola dell'isola grazie alla promulgazione del Codice rurale, emendamento legislativo successivamente incluso da sua figlia Eleonora nella ben più celebre Carta de Logu
L'incredibile Hulk è un film del 2008 diretto da Louis Leterrier. Il protagonista è interpretato da Edward Norton, il quale contribuì anche alla stesura della sceneggiatura insieme a Zak Penn; il supereroe è incentrato principalmente sulla versione Ultimate si sottopone all'esperimento di proposito, e non viene investito dai raggi gamma nel tentativo di salvare Rick Jones come nell'universo Marvel tradizionale. Il personaggio mantiene comunque i tratti del "gigante buono" della versione classica che vuole solo essere lasciato in pace dagli uomini, e non il bestiale assassino dell'altro universo.
Applichiamo la funzione compute_similarity per testare quanto simili siano questi due testi. Ci aspettiamo un valore abbastanza basso poiché trattano di argomenti diversi e non usano la stessa terminologia.
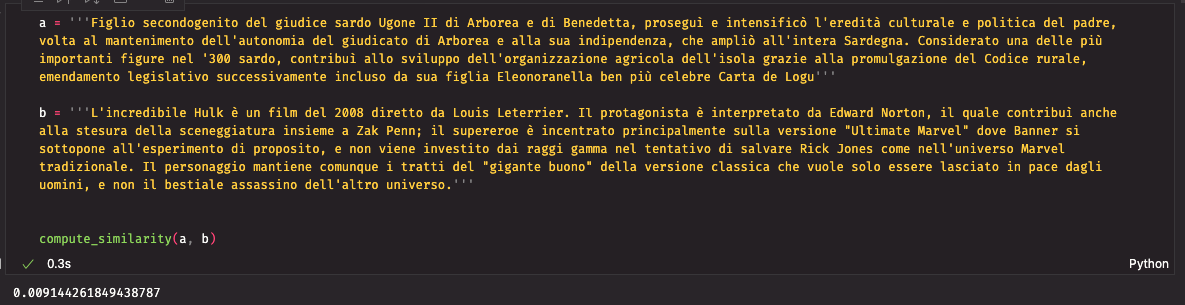
I due testi mostrano una similarità molto bassa, vicino allo 0. Vediamo ora con due testi abbastanza simili.
Copierò parte del secondo testo nel primo, mantenendo una lunghezza simile
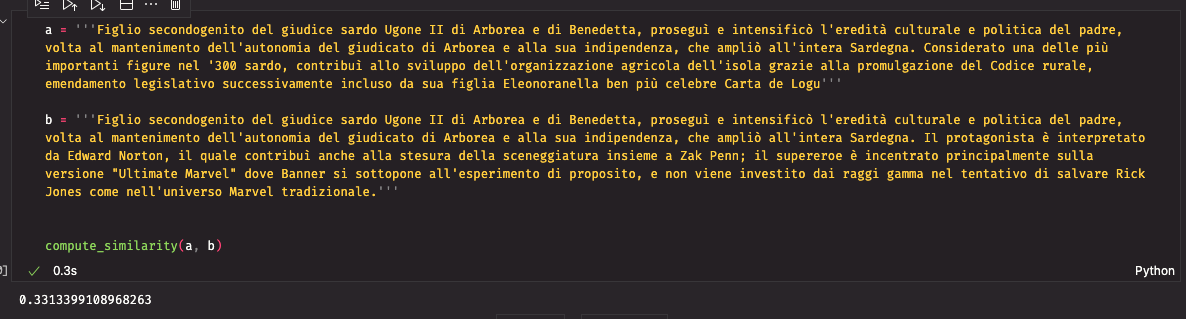
La similarità è ora di 0.33. Sembra funzionare bene.
Ora applichiamo questo metodo a tutti i testi presenti, in maniera accoppiata (pairwise).
M = np.zeros((posts.shape[0], posts.shape[0])) # creiamo una matrice 30x30 per contenere i risultati di testo_i con testo_j
for i, row in tqdm(posts.iterrows(), total=posts.shape[0], desc='1st level'): # definiamo i
for j, next_row in posts.iterrows(): # definiamo j
M[i, j] = compute_similarity(row.article, next_row.article) # popoliamo la matrice con i risultati
Andiamo nel dettaglio di quello che fa questo pezzo di codice.
- Creiamo una matrice 30x30 chiamata
M - Iteriamo riga per riga sul dataframe per accedere all'articolo \( i \)
- Iteriamo riga per riga sullo stesso dataframe nuovamente, per accedere all'articolo \( j \)
- Lanciamo
compute_similaritysu \( articolo_i \) e su \( articolo_j \) per ottenere la similarità - Salviamo questo valore in
Ma posizione \( i \), \( j \)
M può essere facilmente convertita in un dataframe Pandas per la visualizzazione di una heatmap attraverso Seaborn.
labels = posts.url.str.split('/').str[3:].str[1] # estraiamo i titoli degli articoli dalle url
similarity_df = pd.DataFrame(M, columns=labels, index=labels) # creiamo un dataframe
mask = np.triu(np.ones_like(similarity_df)) # applichiamo una maschera per rimuovere la parte superiore della heatmap
# creiamo la visualizzazione
plt.figure(figsize=(12, 12))
sns.heatmap(
similarity_df,
square=True,
annot=True,
robust=True,
fmt='.2f',
annot_kws={'size': 7, 'fontweight': 'bold'},
yticklabels=similarity_df.columns
xticklabels=similarity_df.columns,
cmap="YlGnBu",
mask=mask
)
plt.title('Heatmap delle similarità tra testi', fontdict={'fontsize': 24})
plt.show()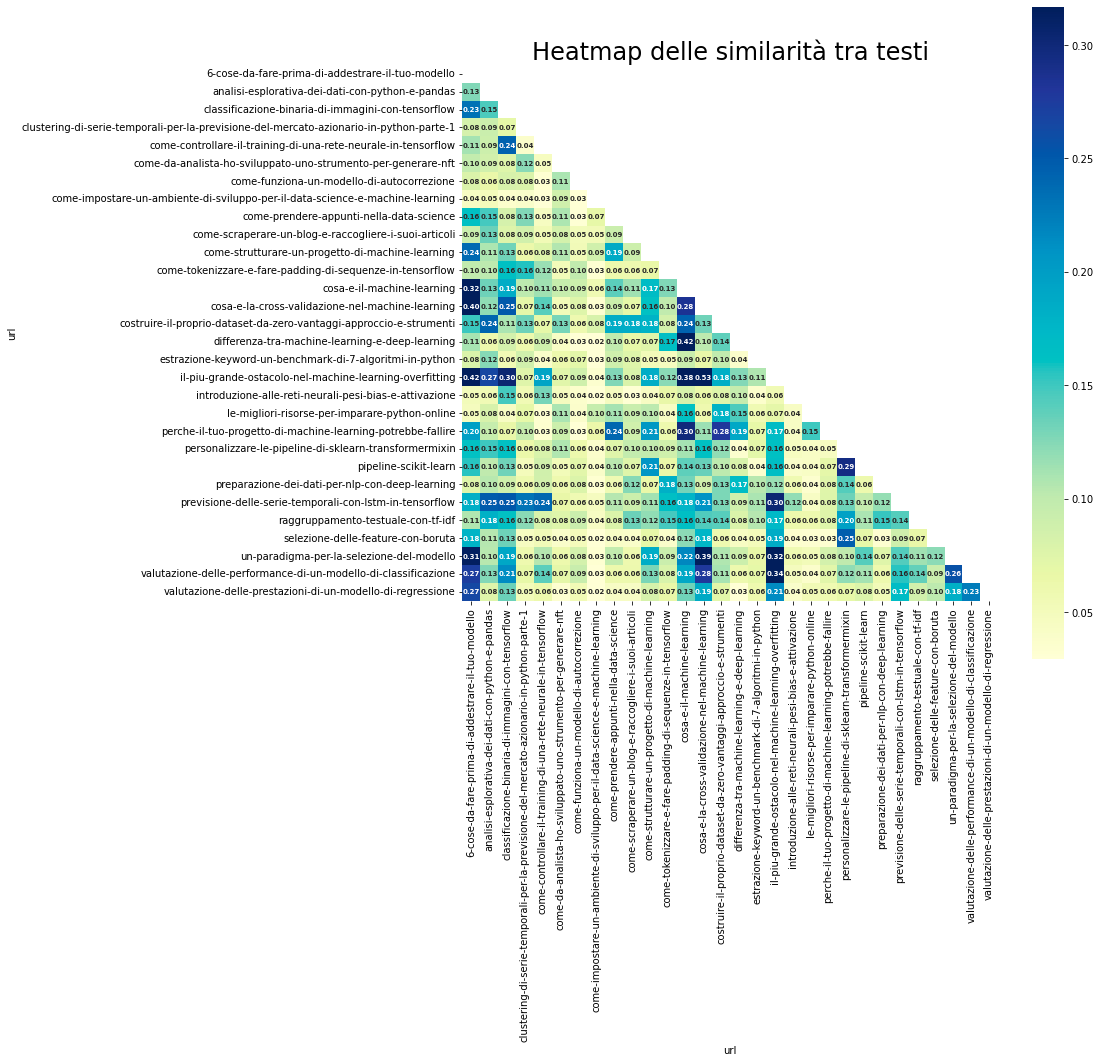
La mappa di calore mette in risalto le anomalie usando colori più accesi o spenti in base al valore di similarità ottenuto.
Facciamo un piccolo cambiamento al codice per selezionare solo gli elementi che hanno similarità superiore a 0.40.
top = similarity_df[similarity_df > 0.4] # andiamo a modificare qui
mask = np.triu(np.ones_like(top))
sns.heatmap(
top,
square=True,
annot=True,
robust=True,
fmt='.2f',
annot_kws={'size': 7, 'fontweight': 'bold'},
yticklabels=top.columns
xticklabels=top.columns,
cmap="YlGnBu",
mask=mask
)
plt.title('Heatmap delle similarità tra testi', fontdict={'fontsize': 24})
plt.show()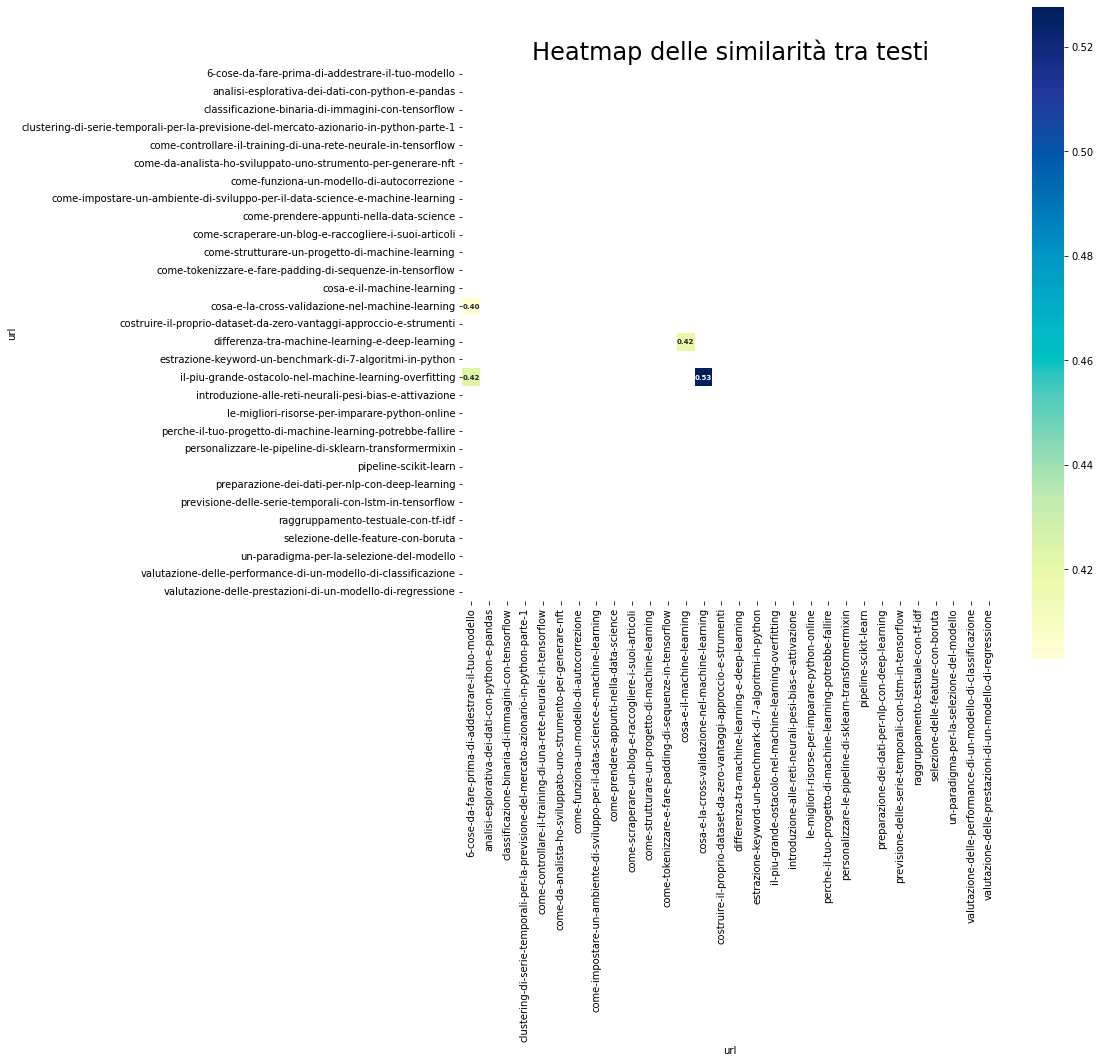
Vediamo 4 pagine con un indice di similarità maggiore di 0.4.
In particolare vediamo queste combinazioni:
- 6 cose da fare prima di addestrare il tuo modello -> il più grande ostacolo nel machine learning - l'overfitting
- 6 cose da fare prima di addestrare il tuo modello -> cosa è la cross-validazione nel machine learning
- cosa è la cross-validazione nel machine learning -> il più grande ostacolo nel machine learning - l'overfitting
- cosa è il machine learning -> qual è la differenza tra machine learning e deep learning
La similarità tra alcune di queste coppie è presente anche tra altre coppie che mostrano similarità alta.
Questi articoli sono accomunati dall'argomento, cioè quello del machine learning e di alcune best practice. Vale la pena girare questo script alla mia prossima pubblicazione in queste categorie, cosi da non incorrere in similarità troppo alta!
Conclusioni
In questo articolo abbiamo visto un semplice ma efficace algoritmo per identificare pagine o articoli simili di un sito web, scraperato con un metodo altrettanto efficiente.
I next step includerebbero una analisi più approfondita per capire perché questi articoli abbiano una similarità alta. Strumenti di data mining e NLP, come Spacy, fanno molto comodo e permettono una analisi POS (part of speech) e NER (named entity recognition).
Studiare le keyword più usate sarebbe altrettanto efficace.
Template
Ecco qui l'intera codebase
import pandas as pd
import numpy as np
import nltk
from nltk.corpus import stopwords
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from tqdm import tqdm
import matplotlib.pyplot as plt
import seaborn as sns
###
Ricordiamo di creare il dataset con lo script presente qui
https://www.diariodiunanalista.it/posts/come-scraperare-un-blog-e-raccogliere-i-suoi-articoli
###
posts = df[df.url.str.contains('post')]
posts.reset_index(inplace=True)
remove_punctuation_map = dict((ord(char), None) for char in string.punctuation)
ita_stopwords = stopwords.words('italian')
def preprocess(text):
return nltk.word_tokenize(text.lower().translate(remove_punctuation_map))
vectorizer = TfidfVectorizer(tokenizer=preprocess, stop_words=ita_stopwords)
def compute_similarity(a, b):
tfidf = vectorizer.fit_transform([a, b])
return ((tfidf * tfidf.T).toarray())[0,1]
M = np.zeros((posts.shape[0], posts.shape[0]))
for i, row in tqdm(posts.iterrows(), total=posts.shape[0], desc='1st level'):
for j, next_row in posts.iterrows():
M[i, j] = compute_similarity(row.article, next_row.article)
labels = posts.url.str.split('/').str[3:].str[1]
similarity_df = pd.DataFrame(M, columns=labels, index=labels)
mask = np.triu(np.ones_like(similarity_df))
plt.figure(figsize=(12, 12))
sns.heatmap(
similarity_df,
square=True,
annot=True,
robust=True,
fmt='.2f',
annot_kws={'size': 7, 'fontweight': 'bold'},
yticklabels=similarity_df.columns
xticklabels=similarity_df.columns,
cmap="YlGnBu",
mask=mask
)
plt.title('Heatmap delle similarità tra testi', fontdict={'fontsize': 24})
plt.show()




Commenti dalla community