
Il modo migliore per spiegare cosa sia l'overfitting è attraverso un esempio.
Poniamo questo scenario: siamo appena stati assunti come data scientist in una azienda che sviluppa software di elaborazione fotografica.
L'azienda nell'ultimo periodo ha deciso di provare a implementare delle funzionalità di machine learning e l'intenzione è quella di creare un software in grado di distinguere tra foto originali e foto ritoccate.
Il nostro compito è quello di creare un modello che sia specializzato nel rilevare fotoritocchi che hanno come soggetti gli esseri umani.
Siamo entusiasti dell'opportunità, ed essendo alla prima esperienza lavorativa, lavoriamo con molta energia per fare bella figura.
Addestriamo correttamente un modello, che sembra performare molto bene sui dati di training. Siamo molto contenti al riguardo, e comunichiamo i nostri risultati preliminari agli stakeholder.
Il prossimo step è servire il modello in produzione con un gruppo ristretto di utenti. Configuriamo tutto con il team tecnico e poco dopo il modello è online e mostra i suoi risultati con gli utenti.
La mattina seguente apriamo la casella email e leggiamo una serie di messaggi sconcertanti. Gli utenti hanno riportato feedback molto negativo! Il nostro modello non sembra essere in grado di classificare correttamente le immagini.
Com'è possibile che in fase di addestramento il nostro modello performava bene mentre ora in produzione osserviamo risultati così scadenti?
Semplice. Siamo stati vittima di overfitting.
Abbiamo perso il posto. Che botta.
L'intuizione dietro l'overfitting
L'esempio sopra rappresenta una situazione un po' esagerata. Un analista alle prime armi ha almeno una volta sentito parlare del termine overfitting.
È probabilmente una delle prime parole che si imparano quando si lavora nel settore, seguendo e ascoltando tutorial online.
Ciononostante, l'overfitting è un fenomeno che si osserva molto spesso quando si addestra un modello predittivo. Questo porta l'analista a fronteggiare continuamente lo stesso problema che può essere causato da una moltitudine di ragioni.
- A definire cosa è l'overfitting (contrapposto all'underfitting)
- Perché rappresenta l'ostacolo più grande che un analista deve affrontare quando fa machine learning
- Come evitare che questo si presenti attraverso alcuni tecniche
Spiegare in maniera chiara cosa sia voglia dire overfitting non è cosa facile.
Questo perché bisogna partire proprio da cosa significa addestrare un modello e valutare le sue performance (nel link qui in basso una introduzione al machine learning, che include risposte ad alcune domande rilevanti per questo articolo).
 Andrea D’Agostino
Andrea D’Agostino
Prendendo spunto proprio dall'articolo menzionato,
L'atto di mostrare […] dati al modello e di permettere a quest'ultimo di apprendere si chiama training (addestramento). […] Durante il training, l'algoritmo di apprendimento cerca di imparare i pattern che legano i dati insieme partendo da certe ipotesi.
Ad esempio, gli algoritmi probabilistici fondano il loro funzionamento proprio nel dedurre le probabilità che un evento accada in presenza di certi dati.
Quando il modello viene addestrato, usiamo una metrica di valutazione per stabilire quanto le predizioni di quest'ultimo siano lontane dal valore reale osservato.
Ad esempio per un problema di classificazione (come quello del nostro esempio) potremmo usare lo score F1 per capire come stia performando il modello sui dati di addestramento.
L'errore commesso dall'analista junior nell'esempio introduttivo ha a che vedere con una cattiva interpretazione proprio della metrica di valutazione durante la fase di training e dell'assenza di un framework di validazione dei risultati.
Di fatto, l'analista ha posto attenzione sulle performance del modello durante l'addestramento, dimenticando di guardare e analizzare la performance sui dati di test.
Cosa è l'overfitting?
L'overfitting si manifesta quando il nostro modello impara bene a generalizzare i dati di training ma non quelli di test.
Quando questo capita il nostro algoritmo non riesce a performare bene con dati che non ha mai visto prima. Questo distrugge completamente il suo scopo, e diventa quindi un modello inutile.
Questo è il motivo per cui l'overfitting è il peggior nemico di un analista: rende il nostro modello, e quindi il nostro lavoro, inutile.
Quando un modello viene addestrato, questo sfrutta un training set per apprendere i pattern e mappare il feature set alla variabile target.
Può succedere però, come abbiamo già visto, che un modello possa iniziare a imparare informazioni rumorose o addirittura inutili - ancora peggio, queste informazioni sono presenti solamente nel training set.
Il termine "overfitting" si traduce in italiano con "overadattamento" al dataset di addestramento - il nostro modello si sofferma e impara informazioni irrilevanti e queste nozioni inficiano negativamente durante l'inferenza.
Esempio in Python
Usiamo il famoso Red Wine Dataset da Kaggle per visualizzare un caso di overfitting. Questo dataset ha 11 dimensioni che definiscono la qualità di un vino rosso. In base a queste dobbiamo costruire un modello in grado di predire la qualità di un vino rosso, che è un valore tra 1 e 10.
Useremo un classificatore basato su alberi decisionali (Sklearn.tree.DecisionTreeClassifier) per mostrare come un modello possa essere portato a overfittare.
Ecco come appare il dataset se stampiamo le prime 5 righe

Usiamo questo codice per addestrare un albero decisionale.
Train accuracy: 0.623
Test accuracy: 0.591Abbiamo inizializzato il nostro albero decisionale con l’iperparametro max_depth=3. Proviamo a usare ora un diverso valore - ad esempio 7.
clf = tree.DecisionTreeClassifier(max_depth=7) # il resto del codice rimane ugualeGuardiamo i nuovi valori dell’accuracy
train accuracy: 0.754
Test accuracy: 0.591La accuracy si sta alzando per il set di addestramento, ma non per quello di test. Inseriamo tutto in un loop dove andremo a modificare max_depth in maniera dinamica e addestrando un modello ad ogni iterazione.
train_accs = []
test_accs = []
cols = [
'fixed.acidity', 'volatile.acidity', 'citric.acid','residual.sugar', 'chlorides', 'free.sulfur.dioxide',
'total.sulfur.dioxide', 'density', 'pH', 'sulphates', 'alcohol',
]
# inizializziamo un loop dove cambieremo il valore di max depth, partendo da 1 a 25
for depth in range(1, 25):
clf = tree.DecisionTreeClassifier(max_depth=depth)
clf.fit(df_train[cols], df_train.quality)
train_predictions = clf.predict(df_train[cols])
test_predictions = clf.predict(df_test[cols])
train_acc = metrics.accuracy_score(df_train.quality, train_predictions)
test_acc = metrics.accuracy_score(df_test.quality, test_predictions)
# inseriamo in liste vuote le nostre accuracies
train_accs.append(train_acc)
test_accs.append(test_acc)
# visualizziamo i dati
plt.figure(figsize=(10, 5))
sns.set_style('whitegrid')
plt.plot(train_accs, label='train accuracy')
plt.plot(test_accs, label='test accuracy')
plt.legend(loc='upper left', prop={'size': 15})
plt.xticks(range(0, 26, 5))
plt.xlabel('max_depth', size=20)
plt.ylabel('accuracy', size=20)
plt.show()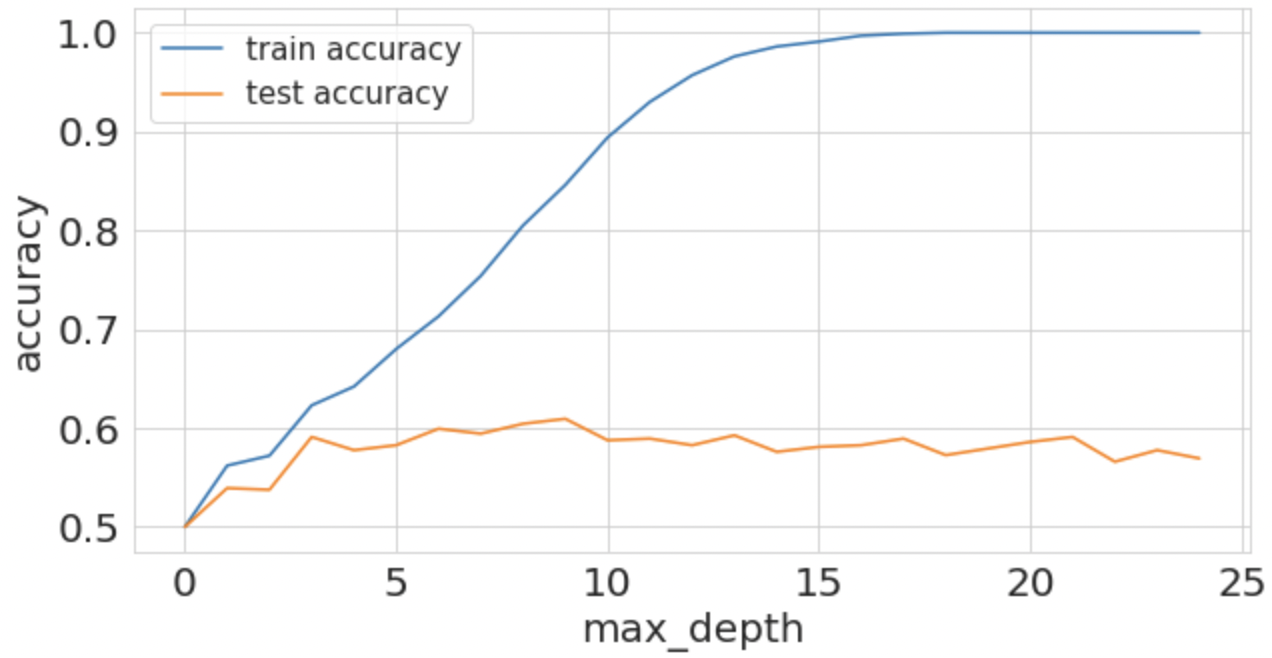
Guardate come ad una max_depth alta corrisponda una accuracy molto alta in training (addirittura 100%) ma come questa sia intorno al 55-60% nel test set.
Quello che stiamo osservando è proprio l’overfitting!
Infatti, il valore più alto della accuratezza nel test set lo si nota a max_depth = 9. Al di sopra di questo valore l’accuratezza non migliora. Non ha senso dunque aumentare il valore del parametro al di sopra del 9.
Questo valore di max_depth = 9 rappresenta lo “sweet spot” - vale a dire il valore ideale per non avere un modello che overfitta, ma che sia comunque in grado di generalizzare bene i dati. Infatti, un modello potrebbe essere anche molto “superficiale” e manifestare underfitting, l’opposto dell’overfitting.
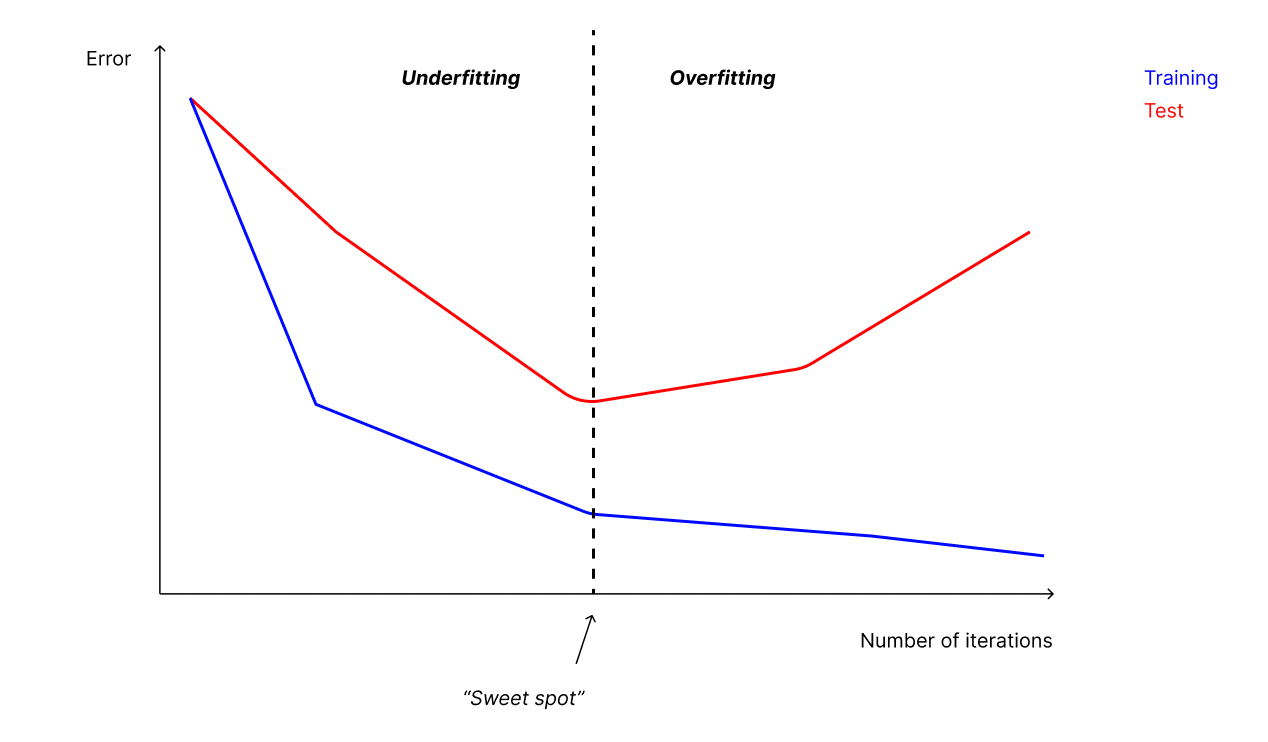
Le cause più frequenti di overfitting
Le cause più frequenti che portano un modello a overfittare sono le seguenti:
- I nostri dati contengono rumore e altre informazioni non rilevanti
- I set di training e test sono troppo piccoli
- Il modello è troppo complesso
I dati contengono rumore
Quando i nostri dati di addestramento contengono rumore, il nostro modello impara quei pattern e cerca poi di applicare tale conoscenza con il test set, senza ovviamente successo.
I dati sono pochi e non rappresentativi
Se abbiamo pochi dati, quei potrebbero non essere sufficienti ad essere rappresentativi della realtà che sarà poi fornita dagli utenti che useranno il modello.
Il modello è troppo complesso
Un modello troppo complesso si focalizzerà su informazioni che fondamentalmente sono irrilevanti a mappare la variabile target. Nell’esempio precedente, l’albero decisionale con max_depth=9 non era ne troppo semplice ne troppo complesso. Aumentare questo valore ha portato ad aumentare la metrica di performance in training, ma non in test.
Come evitare l'overfitting
Ci sono diversi modi per evitare l’overfitting. Vediamo qui i più comuni ed efficaci da usare praticamente sempre
- Cross-validazione
- Aggiungere più dati al nostro dataset
- Rimuovere feature
- Utilizzare un meccanismo di early stopping
- Regolarizzare il modello
Ognuna di queste tecniche permette all’analista di comprendere bene le performance del modello e di raggiungere più velocemente lo “sweet spot” menzionato precedentemente.
Cross-validazione
La cross-validazione è una tecnica molto comune ed estremamente potente che permette di testare le performance del modello su diversi “mini-set” di validazione, invece di usare un singolo set come abbiamo fatto noi in precedenza.
Questo permette di capire come il modello generalizzi su diverse porzioni dell’intero dataset, dando quindi una idea più chiara del comportamento del modello.
Andrea D’Agostino
Aggiungere più dati al nostro dataset
Il nostro modello può avvicinarsi di più allo sweet spot semplicemente andando ad integrare più informazioni.
Aumentiamo i dati ogni volta che possiamo in modo da offrire al nostro modello delle porzioni di “realtà” sempre più rappresentative. Consiglio al lettore di leggere questo articolo dove spiego come costruire un dataset da zero.
Rimuovere feature
Tecniche di selezione delle feature (come Boruta) possono aiutarci a comprendere quali feature sono inutili alla predizione della variabile target. Rimuovere queste variabili può aiutare a ridurre il rumore di fondo che osserva il modello.
Utilizzare un meccanismo di early stopping
L’early stopping è una tecnica principalmente utilizzata nel deep learning e consiste nel fermare il modello quando non vi è un aumento della performance per una serie di epoche di training. Questo permette di salvare lo stato del modello al suo momento migliore e utilizzare solo questa versione più performante.
Regolarizzare il modello
Attraverso il tuning degli iperparametri possiamo spesso e volentieri controllare il comportamento del modello per ridurre o aumentare la sua complessità. Possiamo modificare questi iperparametri direttamente durante la cross-validazione per comprendere come il modello performi sui diversi split di dati.
Alcuni dei parametri tunabili sono quelli relativi alla regolarizzazione: è possibile rendere il modello più o meno sensibile ai dati rumorosi andando a cambiare il valore di questi ultimi. Nella regressione logistica ad esempio, il parametro C fa esattamente questo.
Andrea D’Agostino
Conclusione
Ora il lettore ha una idea più precisa di cosa sia l'overfitting (e la sua controparte, l'underfitting) e che ripercussioni può avere sulle performance del proprio modello.
Abbiamo anche visto quali sono delle tecniche frequentemente usate nella data science e machine learning per evitare l'overfitting.
Infine abbiamo toccato il tema del tuning degli iperparametri, molto importante in una pipeline di machine learning.
Grazie per la vostra attenzione, a presto! 👋





Commenti dalla community