
Tabella dei Contenuti
I termini machine learning e deep learning sono sicuramente centrali nel contesto della data science.
Le manifestazioni della IA più impattanti del momento, come ChatGPT, si basano proprio su machine e deep learning.
Il modo in cui questi termini vengono usati però è spesso lo stesso, e a volte possono significare anche la stessa cosa.
Questo porta spesso i non addetti ai lavori a fare confusione rispetto alla vera interpretazione di questi due termini.
L'obiettivo di questo articolo è proprio rispondere alla seguente domanda: qual è la differenza tra machine learning e deep learning?
Facciamo chiarezza introducendo alcune definizioni.
 Andrea D’Agostino
Andrea D’Agostino
Definizioni di machine e deep learning
Per comprendere al meglio le differenze tra machine e deep learning, bisogna prima aver chiaro cosa siano effettivamente queste due discipline e in che contesto risiedono.
Questo è fondamentale soprattutto per chi vuole orientarsi nel campo e sta appena iniziando il suo viaggio nel mondo dell'analisi dati.
Ogni disciplina menzionata in questo articolo fa parte del campo dell'intelligenza artificiale. Questa fa a sua volta parte, come tanti sapranno, dell'informatica.
Di conseguenza, sia machine learning che deep learning fanno parte prima dell'IA e poi dell'informatica.
L'informatica è una disciplina scientifica molto ampia, quindi ci focalizzeremo solo sull'intelligenza artificiale perché è in questa che noi operiamo come analisti.
L'intelligenza artificiale è un campo molto ampio. Machine learning e deep Learning sono solo due delle discipline più conosciute.
Altre sono
- la creazione di algoritmi di ricerca e ottimizzazione
- creazione di strutture logiche, percettive, di apprendimento e pianificazione
- robotica
Ce ne sono molte altre, e in base al livello di dettaglio che vogliamo considerare queste possono essere espande per integrare altri gruppi.
Di conseguenza, machine learning e deep learning, facendo parte dell'IA, toccano e influenzano le discipline menzionate sopra e altrettanto fanno quest'ultime.
Per visualizzare questa gerarchia, consideriamo questa immagine
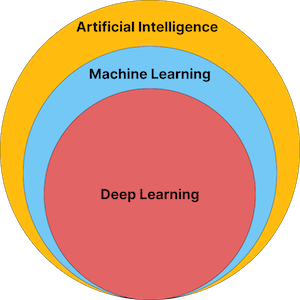
Molto probabilmente, uno studioso di robotica userà machine learning o deep learning per insegnare alla macchina a raggiungere un obiettivo. In questo caso, probabilmente userà il reinforcement learning (apprendimento per rinforzo).
Andiamo a vedere ora cosa siano machine learning e deep learning per capire le differenze.
Definizione di Machine Learning
Il termine machine learning si traduce in italiano apprendimento automatico ed è, come abbiamo menzionato, un ramo dell'intelligenza artificiale che a sua volta è una branchia dell'informatica.
Il machine learning permette ad una macchina di svolgere compiti senza essere espressamente programmarle per farlo.
Il machine learning quindi diventa una delle soluzioni più interessanti e potenti per automatizzare un compito.
È infatti questo uno dei motivi che hanno portato i data scientist a essere delle figure di spicco in contesto lavorativo - sono di fatto abilitatori dell'automazione.
Andrea D’Agostino
Grazie al machine learning, un analista può potenzialmente considerare qualsiasi compito e inserire un livello di automazione in esso che può
- contribuire a velocizzare i tempi di esecuzione
- ridurre l'errore umano
- permettere di scalare il business su più fronti
Ognuno di questi punti è fondamentale in un contesto di business, in quanto hanno diretto impatto sull'aspetto economico.
Definizione di Deep Learning
Più che una disciplina a se stante, il termine deep learning indica una serie di strumenti specifici per risolvere un particolare gruppo di problemi.
Mentre il termine machine learning si riferisce alla disciplina, deep learning si riferisce al modo in cui la macchina impara.
Il termine di traduce come apprendimento profondo perché ha a che vedere con le reti neurali. Infatti, una rete neurale apprende attraverso i suoi strati, che possono arrivare ad essere molto profondi.
Le reti neurali sono considerate l'essenza del deep learning, e ce ne sono di veramente parecchi tipi...ognuna strutturata per risolvere un particolare tipo di problema.
Ad esempio, esistono delle reti neurali che "ricordano" sequenze molto lunghe, cosi che l'output sia influenzato non solo dagli ultimi dati, ma anche quelli che li precedevano parecchio prima. Queste sono chiamate LSTM (long-short term memory) neural networks.
Andrea D’Agostino
Altre invece, chiamate reti neurali convoluzionali, applicano filtri alle immagini cosi da apprendere solo le caratteristiche più rilevanti dei soggetti rappresentati.
Marco Speciale
Se vuoi una introduzione alle reti neurali, segui il link qui in basso 👇
Andrea D’Agostino
Differenze tra Machine Learning e Deep Learning
La differenza tra machine learning e deep learning sta prevalentemente nelle applicazioni e nelle performance degli algoritmi che appartengono a queste famiglie.
Molti di questi sono concepiti per risolvere specifici problemi, come le serie temporali. In ogni caso, esistono algoritmi per ogni salsa in entrambe le famiglie.
Ecco una lista delle differenze principali tra machine learning e deep learning.
Specializzazione
Il deep learning è un insieme di tecniche e algoritmi sicuramente più adatto per problemi specifici, solitamente molto complessi.
Poiché le reti neurali possono modellare qualsiasi funzione se hanno risorse e tempi illimitati, queste sono usate per fronteggiare problemi che coinvolgono dati non strutturati, come testo, video e audio.
Per i dati tabellari, quindi strutturati, tecniche di machine learning meno complesse possono anche superare le performance di un algoritmo di deep learning.
Inoltre, le reti neurali sono più efficaci degli algoritmi tradizionali ad imparare da dataset molto più grandi (big data).
Complessità
Sebbene esistano algoritmi di machine learning tradizionale molto complessi, come XGBoost, gli algoritmi di deep learning sono per definizione più complessi.
Progettare modelli di deep learning è una delle sfide più importanti nella data science. Ogni giorno, i machine learning engineers si prodigano per innovare nel campo. Alcune delle realtà più rilevanti nel campo sono Hugging Face, Google, Meta, Baidu, OpenAI e molti altri.
Richiesta computazionale
Tipicamente, gli algoritmi di machine learning tradizionale richiedono meno potenza computazionale rispetto a quelli di deep learning.
Questo perché le reti neurali possono sfruttare le GPU (graphic processing units - in pratica le schede video) per aumentare la velocità di addestramento.
Oltre alle GPU, possono sfruttare anche le TPU (tensor processing unit), che sono dei chip ottimizzati proprio per il deep learning.
Anche alcuni algoritmi di machine learning tradizionale possono sfruttare le GPU - tra di questi c'è XGBoost, LightGBM e Catboost.
Interpretabilità
Un aspetto spesso non considerato quando si parla di differenze tra machine learning e deep learning è quanto i modelli e algoritmi appartenenti a questi siano interpretabili.
Le reti neurali sono tipicamente considerate delle black box - vale a dire che sappiamo come queste funzionino, ma non sappiamo come queste raggiungano il risultato atteso, né possiamo prevederlo.
Solo sperimentando con diverse architetture possiamo gradualmente avvicinarci alla configurazione migliore.
Algoritmi tradizionali invece, come gli alberi decisionali, sono facilmente interpretabili e comunicare come questi funzionino e come raggiungano i risultati è relativamente facile.
Conclusione
Machine learning e deep learning sono essenzialmente la stessa cosa - metodi e tecniche che permettono ad una macchina di fare inferenze abbastanza precise da poter essere utilizzate in un contesto lavorativo e non. Queste metodiche dipendono dal contesto che abbiamo di fronte.
È assolutamente superfluo usare tecniche di deep learning su dataset tabellari di dimensioni ridotte, perché un "banale" random forest potrebbe performare molto meglio e convergere più velocemente alle soluzioni.
Il mio consiglio è come sempre di valutare attentamente il contesto e porsi delle domande chiare che aiutano a comprendere bene il problema che abbiamo di fronte.
Se vuoi leggere di più su consigli e approcci in generale, ti suggerisco di sfogliare la categoria carriera di questo blog che racchiude proprio articoli che vanno a toccare modelli mentali e template per ottimizzare il lavoro.





Commenti dalla community