
Sviluppatori di modelli di machine learning sfruttano rappresentazioni numeriche del mondo per creare e addestrare algoritmi predittivi.
Queste rappresentazioni permettono alla macchina di imparare la relazione tra di essi e la variabile che si vuole predire.
Immaginiamo che un vettore non sia altro che una lista di numeri
$$ X = [1, 2, 3, 4, 5] $$
Questa viene messa in relazione con la variabile target \( y \)
$$ X = [1, 2, 3, 4, 5];\ y = 1 $$
Il modello di machine learning impara la relazione tra caratteristiche e target e fornisce una previsione, in questo caso una classificazione in cui una delle classi è identificata con il numero 1.
In questo post, scriverò di come i vettori possano essere utilizzati per rappresentare concetti complessi in un formato numerico.
La motivazione è che un modello di machine learning non può imparare da fenomeni che non gli siano forniti in formato numerico.
Bisogna prima trasformare un testo, una immagine, un suono o qualsiasi altro fenomeno in un formato numerico adatto all’apprendimento.
Ci sono varie tecniche per trasformare un fenomeno in vettori, e queste dipendono dal tipo di dato con il quale lavoriamo
- Inizieremo presentando il concetto di One-Hot Encoding, una tecnica utilizzata per rappresentare parole come vettori numerici.
- Successivamente, discuteremo i limiti di questa tecnica e introdurremo il concetto di embedding, una tecnica che permette di rappresentare parole, immagini, suoni e altro come vettori numerici di dimensioni inferiori rispetto alle migliaia di categorie necessarie con il One-Hot Encoding.
- Menzioneremo anche i modelli TF-IDF e bag of words, che sono fondamentali nella vettorizzazione del testo
Come si codifica un fenomeno in vettore?
Usiamo del testo per portare avanti il discorso. L’esempio è naturale perché come possiamo intuire, i modelli di machine learning non possono usare direttamente il testo per il loro apprendimento. Occorre trasformare ogni carattere o parola in un numero prima.
Facciamo un esempio. Poniamo che vogliamo creare una rappresentazione numerica delle parole
- Re
- Regina
- Principe
- Principessa
Il modo più semplice di codificare queste parole sarebbe di assegnare a ognuna di esse un numero, in maniera sequenziale.
| Re | 1 |
| Regina | 2 |
| Principe | 3 |
| Principessa | 4 |
Le parole sono state correttamente trasformate in formato numerico, seguendo la mappatura
map = {
"Re": 1,
"Regina": 2,
"Principe": 3,
"Principessa": 4
}
Ma c’è un problema. Se fornissimo questi dati a qualsiasi modello predittivo, questo andrebbe ad assegnare un valore matematico più alto a principe e principessa, rendendoli più importanti di re e regina.
Ovviamente questo andrebbe a fornire informazioni sbagliate al modello, che apprenderebbe relazioni sbagliate. Dobbiamo rendere la nostra rappresentazione numerica più precisa.
One-Hot Encoding
Per risolvere il problema di rappresentazione numerica descritto sopra, è possibile utilizzare la tecnica del One-Hot Encoding.
In questo caso, ogni parola sarebbe rappresentata da un vettore numerico di dimensione pari al numero totale di parole che si vuole rappresentare. Il vettore avrebbe tutti i valori pari a zero, tranne uno, che rappresenta la parola specifica.
Ad esempio, nel caso delle quattro parole "Re", "Regina", "Principe" e "Principessa", ogni parola sarebbe rappresentata da un vettore di quattro elementi, con il valore "1" nella posizione corrispondente alla parola e "0" in tutte le altre posizioni.
Questa tecnica risolve il problema di assegnare un valore matematico più alto a parole che non sono più importanti di altre nella rappresentazione numerica.
| Re | [1, 0, 0, 0] |
| Regina | [0, 1, 0, 0] |
| Principe | [0, 0, 1, 0] |
| Principessa | [0, 0, 0, 1] |
Molto bene. Ora il nostro modello ha una rappresentazione vettoriale “bilanciata” per ogni vocabolo appartenente al dataset (che in questo caso è formato solo da 4 vocaboli).
Ma…cosa succede se il nostro vocabolario è formato da migliaia o magari milioni di vocaboli? Considerando che nel dizionario italiano esistono circa 270.000 vocaboli, applicare il one-hot encoding sarebbe a dir poco problematico.
Le risorse computazionali per svolgere questa codifica sarebbero notevoli e la rappresentazione finale sarebbe “solo” bilanciata: non c’è alcuna informazione riguardo le relazioni tra le parole.
Word Embedding
Per superare i limiti del One-Hot Encoding, si può utilizzare la tecnica chiama embedding. Questa permette di rappresentare parole come vettori numerici di dimensioni controllabili rispetto alle migliaia di categoria necessarie con il One-Hot Encoding.
L'idea è quella di creare una rappresentazione numerica delle parole che tenga conto delle relazioni semantiche tra le parole stesse.
In pratica, ogni parola viene rappresentata come un vettore di numeri reali, dove ogni dimensione rappresenta un aspetto diverso del significato della parola.
Proviamo a creare un grafico dove catturiamo alcune delle caratteristiche delle parole menzionate prima.
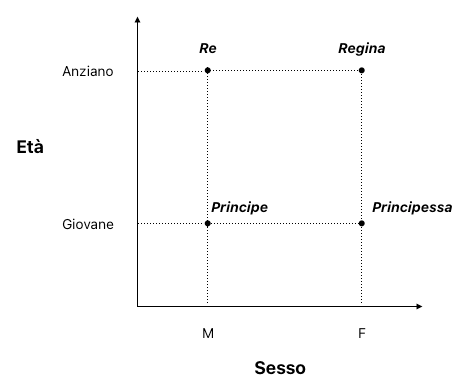
Vediamo come le parole principe e principessa siano vicine tra di loro, esattamente come re e regina.
Ponendo che la variabile genere possa assumere solo due valori, M e F (usiamo 0 e 1), e che la variabile età possa assumere solo tre valori [Giovane, Mezz’età, Anziano] (usiamo 0, 1, 2), vediamo come degli embedding possano rappresentare queste relazioni
| Re | [0, 2] |
| Regina | [1, 2] |
| Principe | [0, 1] |
| Principessa | [1, 1] |
Questa rappresentazione riesce a catturare lo status nobiliare di un individuo andando a usare le dimensioni di genere e l’età.
Muovendoci sull’asse delle X possiamo osservare come i due nobili siano equidistanti da una dimensione che rappresenta la differenza di genere (0: maschio, 1: femmina). Muovendoci sull’asse delle Y, invece, possiamo osservare come l’età sia rappresentato dalla distanza dell’embedding dall’asse Y.
In questo modo, gli embedding delle parole possono essere utilizzati come input per i modelli di machine learning, permettendo di rappresentare in modo più preciso concetti complessi in un formato numerico.
In questo esempio abbiamo solo due dimensioni. Di fatto, vengono addestrate delle reti neurali con lo specifico compito di trovare queste rappresentazioni su parecchie dimensioni.
Per mettere in prospettiva, modelli come GPT-3 usano più di 12.000 dimensioni.
Una pietra miliare del settore
Gli embedding possono essere utilizzati non solo per parole, ma anche per rappresentare immagini, suoni e altro.
L'uso delle rappresentazioni vettoriali è fondamentale nel machine learning odierno. Le varie innovazioni e tecnologie nel campo del deep learning derivano a cascata dal concetto di vettorizzazione.
Modelli come GPT-3.5 nascono incrociando rappresentazioni vettoriali, algoritmi di ottimizzazione ben studiati e grosse quantità di risorse computazionali.
Teoricamente non c’è limite a questo approccio.
Più dati → Vettori di qualità sempre maggiore → Modelli che useranno tali vettori per un addestramento migliore.
Limiti degli embedding
Nonostante gli embedding siano una tecnica molto utile per la rappresentazione di concetti complessi in formato numerico, hanno anche dei limiti.
In particolare, è importante sottolineare che gli embedding sono costruiti a partire dai dati di addestramento, e quindi possono essere influenzati da eventuali bias presenti nei dati.
Come menzionato, la qualità degli embedding dipende dalla qualità dei dati di addestramento. Se i dati di addestramento non sono rappresentativi del dominio in cui il modello verrà utilizzato, gli embedding potrebbero non essere in grado di catturare tutte le relazioni semantiche tra i concetti.
Inoltre, embedding possono richiedere molta memoria per essere memorizzati, soprattutto se il numero di dimensioni è elevato. Questo può rappresentare un problema in particolare per i modelli di machine learning che devono essere eseguiti su dispositivi con risorse limitate, come ad esempio i dispositivi mobili.
Altre forme di rappresentazione per il testo
Essendo il testo il formato di dati più presente intorno a noi (basti pensare all’enorme quantità di dati testuali presenti sull’internet), alcune tecniche di vettorizzazione testuale sono comuni e ben conosciute.
Una di queste è la trasformazione TF-IDF che è una tecnica di vettorizzazione testuale che assegna un peso a ciascuna parola in base alla sua frequenza all'interno di un documento e alla sua frequenza complessiva all'interno del corpus.
In questo modo, le parole che compaiono frequentemente all'interno di un documento ma raramente all'interno del corpus avranno un peso maggiore rispetto a quelle che compaiono spesso ovunque. Questa tecnica è molto utilizzata nell'ambito del Natural Language Processing per l'analisi dei testi.
Invito il lettore interessato ad saperne di più sul modello TF-IDF leggendo il seguente articolo
 Andrea D’Agostino
Andrea D’Agostino
Il TF-IDF si basa sul modello bag of words che rappresenta un documento come un insieme non ordinato di parole, ignorando la struttura della frase e l'ordine delle parole.
In questo modo, il bag of words può essere utilizzato per rappresentare qualsiasi documento come un vettore di valori numerici, dove ogni valore rappresenta la frequenza di una parola all'interno del documento. Ovviamente non c’è una rappresentazione adeguata della relazione tra le parole, che è fornito invece dagli embedding.
Invito il lettore interessato ad saperne di più sul modello BoW leggendo il seguente articolo
Andrea D’Agostino
Conclusione
In questo post abbiamo visto come i vettori possano essere utilizzati per rappresentare concetti complessi in un formato numerico.
È importante per un data scientist ragionare in termini di vettorizzazione. Domande del tipo
- come posso convertire questo stimolo in un numero?
- come viene interpretato questo dato dalla rete neurale?
- come posso migliorare questa rappresentazione?
sono fondamentali, e il team che riesce a rispondere adeguatamente a queste domande creerà dei sistemi migliori.
I data scientist vedono il mondo in termini di vettori.





Commenti dalla community