
Tabella dei Contenuti
La Retrieval-augmented Generation (RAG, generazione aumentata del recupero delle informazioni) nel contesto dei large language model (LLM) è argomento di parecchie conversazioni incentrate sui temi IA generativa.
La motivazione si trova nella sua facilità di esecuzione e nei risultati che porta per attività di estrazione e arricchimento delle informazioni partendo da documenti.
RAG permette di migliorare la qualità della risposta dei modelli utilizzando un archivio dati esterno al momento dell'inferenza per creare un prompt più ricco che include una combinazione di contesto, cronologia e conoscenza recente/pertinente.
Gli ingredienti per questa fare RAG sono i seguenti:
- un corpus testuale di documenti dalla quale si vuole estrarre informazioni, come PDF, pagine Notion, conversazioni Slack, appunti OneNote e così via
- Una modello di embedding
- Un database vettoriale
- Un prompt e un LLM
Questo articolo ti guiderà attraverso un caso d'uso comune: creare un chatbot basato quindi su linguaggio naturale per estrarre informazioni da una collezione di documenti.
Faremo tutto questo con LangChain, un framework per interfacciarsi con gli LLM per creare catene di operazioni e agenti autonomi.
Il flusso di operazioni è riassunto nel diagramma qui in basso
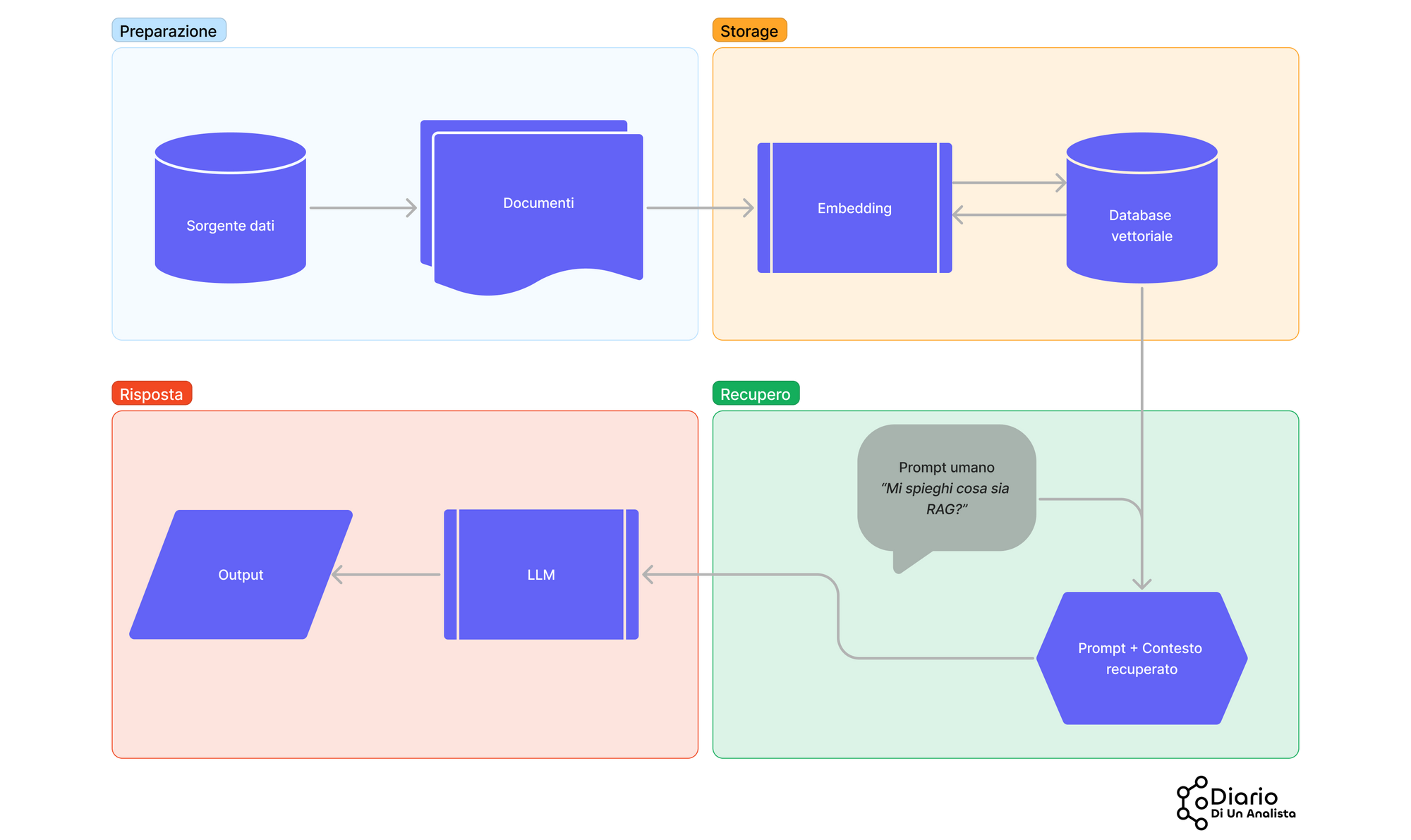
Guardiamo meglio questi step:
- La prima fase include il reperimento dei documenti target
- Useremo LangChain per dividere in porzioni i nostri documenti: gli LLM di fatto non possono processare enormi quantità di dati in input a causa della finestra temporale limitata ad un numero fisso di caratteri. La strategia qui è quella di mostrare al modello solo porzioni di documento che sono rilevanti per la query dell'umano (capirai come a breve)
- Tali porzioni verranno convertite in rappresentazioni numeriche usando dei modelli di embedding e salvate in un database vettoriale per il recupero dell'informazione
- RAG avviene in queste due ultime fasi: il database vettoriale troverà le porzioni di documenti più simili che rispondono alla query dell'utente e queste porzioni verranno passate al LLM insieme al nostro prompt
- LLM restituisce la sua risposta considerando il prompt e il contesto recuperato per arricchire la sua risposta
Si capisce quindi che RAG sia da intendersi quasi come una tecnica di prompt engineering - l'utente ha una query, ma vuole una risposta più accurata da parte del LLM. RAG è una strategia proprio per fare questo.
Se ti interessa leggere di prompt engineering, ho scritto un articolo che potrebbe interessarti che puoi trovare al link seguente
 Andrea D’Agostino
Andrea D’Agostino
- Le basi di LangChain per creare software integrati agli LLM
- Estrarre risposte da un corpus di dati testuali usando linguaggio naturale con RAG
- Creare una interfaccia Streamlit per mostrare e utilizzare il chatbot
Va specificato che LangChain e RAG possono essere usati con praticamente tutti gli LLM conosciuti, open source o meno. In questa guida useremo sia OpenAI che modelli open source (sarà molto facile cambiare i modelli e apprezzare i risultati).
Iniziamo!
I requisiti tecnici
Per fare RAG con LangChain servono pochi ingredienti:
- Uno o più documenti dalla quale vogliamo estrarre informazioni (in questo caso, pagine HTML)
- Un modello di embedding
- Un database vettoriale
- Un prompt
- LangChain (ma volendo si può fare anche senza)
- Un LLM, come GPT-3.5 o 4
- Streamlit crea l'interfaccia frontend
La nostra base dati coinvolgerà l'intera documentazione di LangChain - poiché è molto ampia, un progettino del genere ci aiuterà a fare domande in linguaggio naturale direttamente a LangChain, trovando risposte rapidamente!
Il recupero dei file HTML verrà fatto usando Trafilatura, una libreria per il web scraping efficiente. A questo proposito, userò il codice scritto in precedenza in un mio articolo
Andrea D’Agostino
Il database vettoriale che useremo sarà FAISS. Questo è un database leggero e facile da usare per creare prototipi del genere.
Dopo aver installato un ambiente di sviluppo procedi con i seguenti comandi in terminale.
pip install langchain faiss-cpu openai tiktoken InstructorEmbedding sentence-transformers streamlit python-dotenv pandas trafilaturaoppure se si usa Poetry
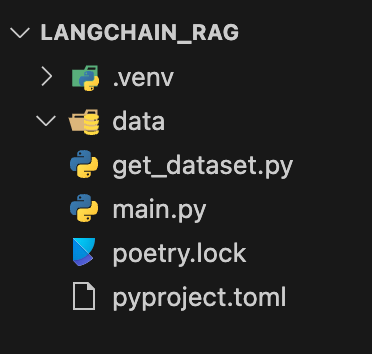
poetry add [lista di librerie]Creiamo due nuovi file che chiameremo main.py e get_dataset.py all'interno della root della directory. Il primo conterrà la logica di Streamlit e di Langchain, mentre il secondo creerà il dataset da esplorare con RAG.
La cartella data conterrà il dump dell'operazione di estrazione.
Ecco uno screenshot che mostra la struttura del progetto (sto usando Poetry).
Creazione del dataset
Per prima cosa occorre creare un dataset. Tale dataset conterrà tutta la documentazione presa dal sito LangChain.
Apriamo il file get_dataset.py e iniziamo a popolarlo con il seguente codice
import time
import pandas as pd
from tqdm import tqdm
from trafilatura.sitemaps import sitemap_search
from trafilatura import fetch_url, extract, extract_metadata
def get_urls_from_sitemap(resource_url: str) -> list:
"""
Funzione che recupera la sitemap attraverso Trafilatura
"""
urls = sitemap_search(resource_url)
return urls
def create_dataset(list_of_websites: list) -> pd.DataFrame:
"""
Funzione che crea un DataFrame Pandas di URL e articoli.
"""
data = []
for website in tqdm(list_of_websites, desc="Websites"):
urls = get_urls_from_sitemap(website)
for url in tqdm(urls, desc="URLs"):
html = fetch_url(url)
body = extract(html)
try:
metadata = extract_metadata(html)
title = metadata.title
description = metadata.description
except:
metadata = ""
title = ""
description = ""
d = {
'url': url,
"body": body,
"title": title,
"description": description
}
data.append(d)
time.sleep(0.5)
df = pd.DataFrame(data)
df = df.drop_duplicates()
df = df.dropna()
return df
if __name__ == "__main__":
list_of_websites = [
"https://python.langchain.com/"
]
df = create_dataset(list_of_websites)
df.to_csv("./data/dataset.csv", index=False)Questo è il codice leggermente rivisto preso dall'articolo precedentemente linkato.
Lanciamo lo script usando il comando in terminale python get_dataset.py.
Il file apparirà così
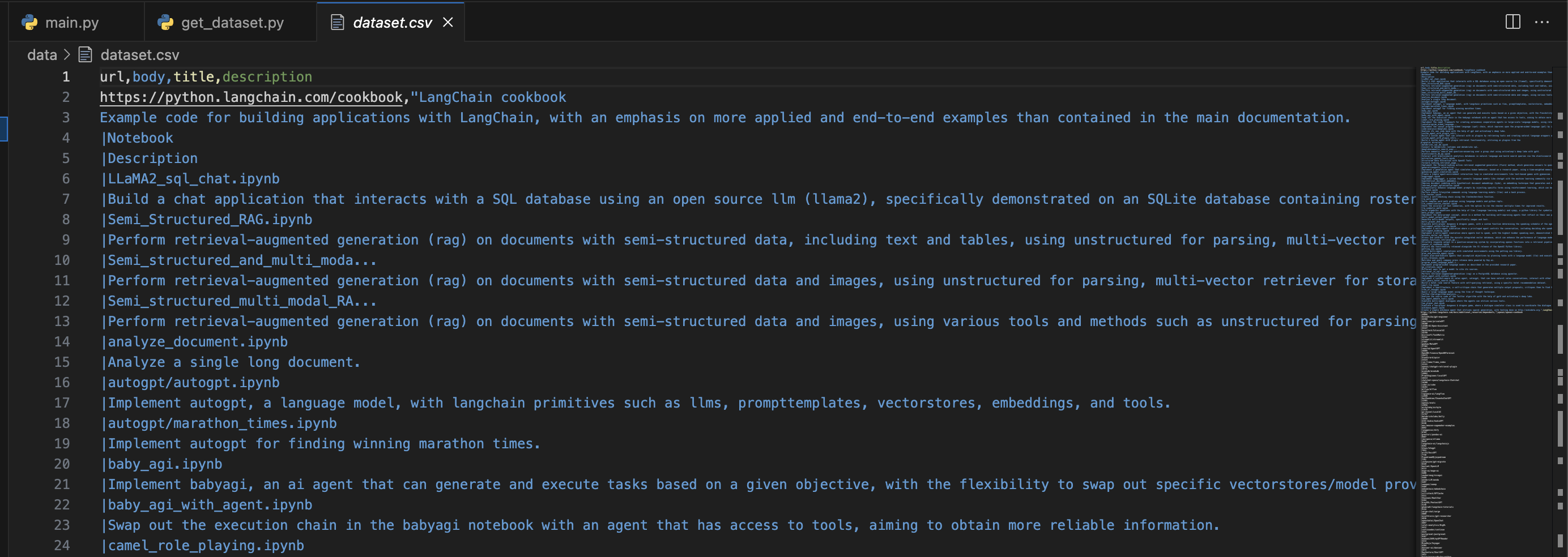
Il dataset è di 1032 righe. Procediamo ora scrivendo la logica del chatbot in main.py.
Struttura del file main.py
Trovo sempre molto comodo iniziare da un file vuoto e popolarlo con uno scheletro che elenca le funzioni e presunti input e output.
Ecco cosa andremo a costruire nel file main.py:
def load_dataset(dataset_name:str="dataset.csv") -> pd.DataFrame:
"""
Funzione helper per caricare il dataset
Args:
dataset_name (str, optional): Nome del file salvato dalla fase di estrazione. Defaults to "dataset.csv".
Returns:
pd.DataFrame: DataFrame Pandas dei dati raccolti da LangChain
"""
pass
def create_chunks(dataset:pd.DataFrame, chunk_size:int, chunk_overlap:int) -> list:
"""
Crea chunk informazionali dal dataset
Args:
dataset (pd.DataFrame): Dataset Pandas
chunk_size (int): Quanti chunk informazionali?
chunk_overlap (int): Quanti chunk condivisi?
Returns:
list: lista di chunk
"""
pass
def create_or_get_vector_store(chunks: list) -> FAISS:
"""
Crea o recupera il vector store
Args:
chunks: List of chunks
Returns:
FAISS: Vector store
"""
pass
def get_conversational_chain(vector_store: FAISS, human_message: str, system_message: str) -> None:
"""
Recupera la catena conversazionale da LangChain
Args:
vector_store (FAISS): Vector store
system_message (str): System message
human_message (str): Human message
Returns:
ConversationalRetrievalChain: Chatbot conversation chain
"""
pass
def main():
pass
if __name__ == "__main__":
main()
Ora andremo nel dettaglio di ogni funzione.
Caricamento dei dati in LangChain
LangChain non è una libreria essenziale, ma offre delle funzioni helper veramente utili. Useremo alcune di queste nel contesto di lettura del dataframe Pandas e nella creazione dei chunk informazionali.
Iniziamo a scrivere una piccola funzione per caricare il dataset nel file main.py.
import pandas as pd
def load_dataset(dataset_name:str="dataset.csv"):
"""
Funzione helper per caricare il dataset
Args:
dataset_name (str, optional): Nome del file salvato dalla fase di estrazione. Defaults to "dataset.csv".
Returns:
pd.DataFrame: DataFrame Pandas dei dati raccolti da LangChain
"""
data_dir = "./data"
file_path = os.path.join(data_dir, dataset_name)
df = pd.read_csv(file_path)
return df
from langchain.document_loaders import DataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def create_chunks(dataset:pd.DataFrame, chunk_size:int, chunk_overlap:int):
"""
Crea chunk informazionali dal dataset
Args:
dataset (pd.DataFrame): Dataset Pandas
chunk_size (int): Quanti chunk informazionali?
chunk_overlap (int): Quanti chunk condivisi?
Returns:
list: lista di chunk
"""
text_chunks = DataFrameLoader(
dataset, page_content_column="body"
).load_and_split(
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=0, length_function=len
)
)
# aggiungiamo i metadati ai chunk stessi per facilitare il lavoro di recupero
for doc in text_chunks:
title = doc.metadata["title"]
description = doc.metadata["description"]
content = doc.page_content
url = doc.metadata["url"]
final_content = f"TITLE: {title}\DESCRIPTION: {description}\BODY: {content}\nURL: {url}"
doc.page_content = final_content
return text_chunks
Un chunk appare così
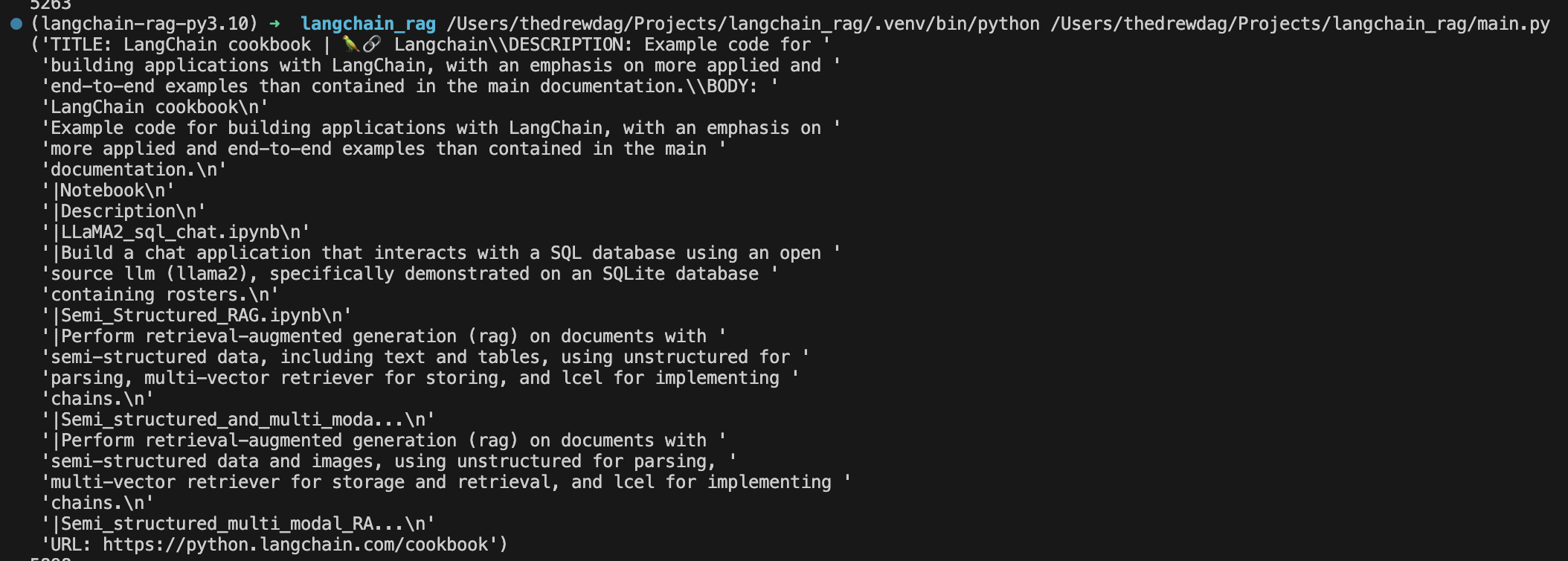
Vediamo meglio cosa sta accadendo nella funzione create_chunks. Usiamo RecursiveCharacterTextSplitter di LangChain applicato all'helper DataFrameLoader per creare i chunk informazionali.
La funzione accetta un dataframe Pandas (che abbiamo già), un valore per chunk_size e chunk_overlap.
- Chunk Size: di quanti elementi dev'essere composto un chunk.
- Chunk Overlap: quanti caratteri possono essere condivisi tra chunk.
In questo caso ho inserito 1000 e 0.
Il RecursiveCharacterTextSplitter è parametrizzato da un elenco di caratteri. Cerca di dividerli in ordine finché i chunk non sono abbastanza piccoli. L'elenco predefinito è ["\n\n", "\n", " ", ""]. Ciò ha l'effetto di cercare di tenere insieme tutti i paragrafi (e poi le frasi e poi le parole) il più a lungo possibile, poiché quelli sembrerebbero genericamente essere i pezzi di testo semanticamente più correlati.
Dal dataset importato nascono 5898 chunk di informazione.
Funzione di embedding e database vettoriale
Qui entriamo nella prima parte di machine learning applicata.
Useremo gli embedding di OpenAI (oppure quelli Instructor, open source) per convertire i testi in numeri.
LangChain permette facilmente di fare questo. Vediamo il codice della funzione create_or_get_vector_store
from langchain.vectorstores import FAISS
from dotenv import load_dotenv
load_dotenv()
def create_or_get_vector_store(chunks: list) -> FAISS:
"""
Funzione per creare o caricare il database vettoriale dalla memoria locale
Returns:
FAISS: Vector store
"""
embeddings = OpenAIEmbeddings() # possiamo cambiarla a piacimento!
# embeddings = HuggingFaceInstructEmbeddings() # ad esempio rimuovendo il commento qui e commentando la riga di sopra
if not os.path.exists("./db"):
print("CREATING DB")
vectorstore = FAISS.from_documents(
chunks, embeddings
)
vectorstore.save_local("./db")
else:
print("LOADING DB")
vectorstore = FAISS.load_local("./db", embeddings)
return vectorstore
Questa funzione è molto semplice: fa un check sulla presenza o meno del database nel progetto e in base a questo lo crea o lo recupera con gli embedding adatti.
load_dotenv! Occorre creare un file chiamato .env nella root della cartella di lavoro e inserire la nostra chiave API di OpenAI oppure di Hugging Face.Il formato è
OPENAI_API_KEY=...In questo modo LangChain andrà a recuperare le nostre chiavi API automaticamente e potremmo usare i servizi richiesti.
Embeddare l'intera documentazione di LangChain prende circa 3 minuti con OpenAI e il database occupa circa 43 mb.
Creare la catena conversazionale con LangChain
Ora creeremo l'interfaccia tra umano e LLM. LangChain aiuta molto qui, con un supporto alla storicizzazione della chat (memoria) e con la ConversationalRetrievalChain che di fatto è proprio l'oggetto che passa in maniera programmatica il prompt umano al LLM.
LLM in questione è GPT-4, proprio quello che usiamo quando chattiamo con ChatGPT.
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
def get_conversation_chain(vector_store: FAISS, system_message:str, human_message:str) -> ConversationalRetrievalChain:
"""
Oggetto LangChain che permette domanda-risposta tra umano e LLM
Args:
vector_store (FAISS): Vector store
system_message (str): System message
human_message (str): Human message
Returns:
ConversationalRetrievalChain: Chatbot conversation chain
"""
llm = ChatOpenAI(model="gpt-4") # possiamo cambiare modello a piacimento
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vector_store.as_retriever(),
memory=memory,
combine_docs_chain_kwargs={
"prompt": ChatPromptTemplate.from_messages(
[
system_message,
human_message,
]
),
},
)
return conversation_chainLa ConversationalRetrievalChain chiede in input un LLM, un retriever (cioè un database vettoriale in modalità read-only) e un oggetto che gestisce la memoria. Inoltre, aggiungiamo il parametro combine_docs_chain_kwargs che permette di manipolare i chunk, aggiungendo i prompt umani e di sistema.
Per convertire il database vettoriale FAISS in un retriever, basta usare .as_retriever() all'oggetto stesso.
Avrà tutto più senso quando vedremo tutto in azione all'interno della funzione main.py.
Creazione dell'interfaccia Streamlit
Ora creeremo l'interfaccia web con cui interagiremo col chatbot.
Streamlit è una libreria molto utile per i data scientist, perché permette di scrivere interfacce web senza conoscere JavaScript. Questo permette ai suoi utenti di prototipare velocemente applicazioni basate sul machine learning.
Scriveremo l'interfaccia all'interno della funzione main.py.
streamlit run [nome_script.py]. Consiglio di aprire un secondo terminale e di lanciare Streamlit così da vedere gli aggiornamenti in live.Ma prima di iniziare con l'interfaccia, definiamo dei messaggi di sistema per il chatbot.
Messaggi di sistema e messaggi umani
Per istruire il chatbot a rispondere adeguatamente dobbiamo usare un prompt di sistema.
Questo è possibile farlo con SystemMessagePromptTemplate che abbiamo importato poco fa da LangChain.
Useremo questo messaggio:
You are a chatbot tasked with responding to questions about the documentation of the LangChain library and project.
You should never answer a question with a question, and you should always respond with the most relevant documentation page.
Do not answer questions that are not about the LangChain library or project.
Given a question, you should respond with the most relevant documentation page by following the relevant context below:\n
{context}In questo modo il chatbot saprà cosa fare prima di interagire con l'umano. La variabile {context} verrà riempita con il chunk informazionale più rilevante scelto dal processo di RAG (riferirsi allo schema sopra).
Il messaggio umano invece verrà passato con HumanMessagePromptTemplate, sostituendo la variabile {question} con la domanda espressa dall'utente via Streamlit.
Configurazione di Streamlit
Continuamo con Steamlit.
Ecco come procederemo
- Caricheremo le variabili d'ambiente quando viene lanciata l'interfaccia
- Caricheremo i messaggi di sistema e umani
- Creeremo delle variabili di stato in Streamlit - queste eviteranno che il refresh dell'informazione in pagina cancelli la cronologia dell'interazione
- Creeremo i widget utili alla conversazione via Streamlit
- Chiameremo la catena conversazionale e riceveremo la risposta alla nostra domanda
Iniziamo a scrivere la nostra funzione, che conterrà anche le funzioni precedentemente scritte:
def main():
load_dotenv() # carichiamo le variabili d'ambiente
system_message_prompt = SystemMessagePromptTemplate.from_template(
"""
You are a chatbot tasked with responding to questions about the documentation of the LangChain library and project.
You should never answer a question with a question, and you should always respond with the most relevant documentation page.
Do not answer questions that are not about the LangChain library or project.
Given a question, you should respond with the most relevant documentation page by following the relevant context below:\n
{context}
"""
)
human_message_prompt = HumanMessagePromptTemplate.from_template("{question}")
if "vector_store" not in st.session_state:
st.session_state.vector_store = create_or_get_vector_store(chunks)
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.set_page_config(
page_title="Documentation Chatbot",
page_icon=":books:",
)
st.title("Documentation Chatbot")
st.subheader("Chatbot per la documentazione del progetto LangChain")
st.markdown(
"""
Questo chatbot è stato creato per rispondere a domande sulla documentazione del progetto LangChain.
Poni una domanda e il chatbot ti risponderà con la pagina più rilevante della documentazione.
"""
)
st.image("https://images.unsplash.com/photo-1485827404703-89b55fcc595e") # Immagine presa con diritti di citazione da Unsplash - ref. Alex Knight
user_question = st.text_input("Cosa vuoi chiedere?")Lanciamo l'interfaccia Streamlit con il comando
streamlit run main.py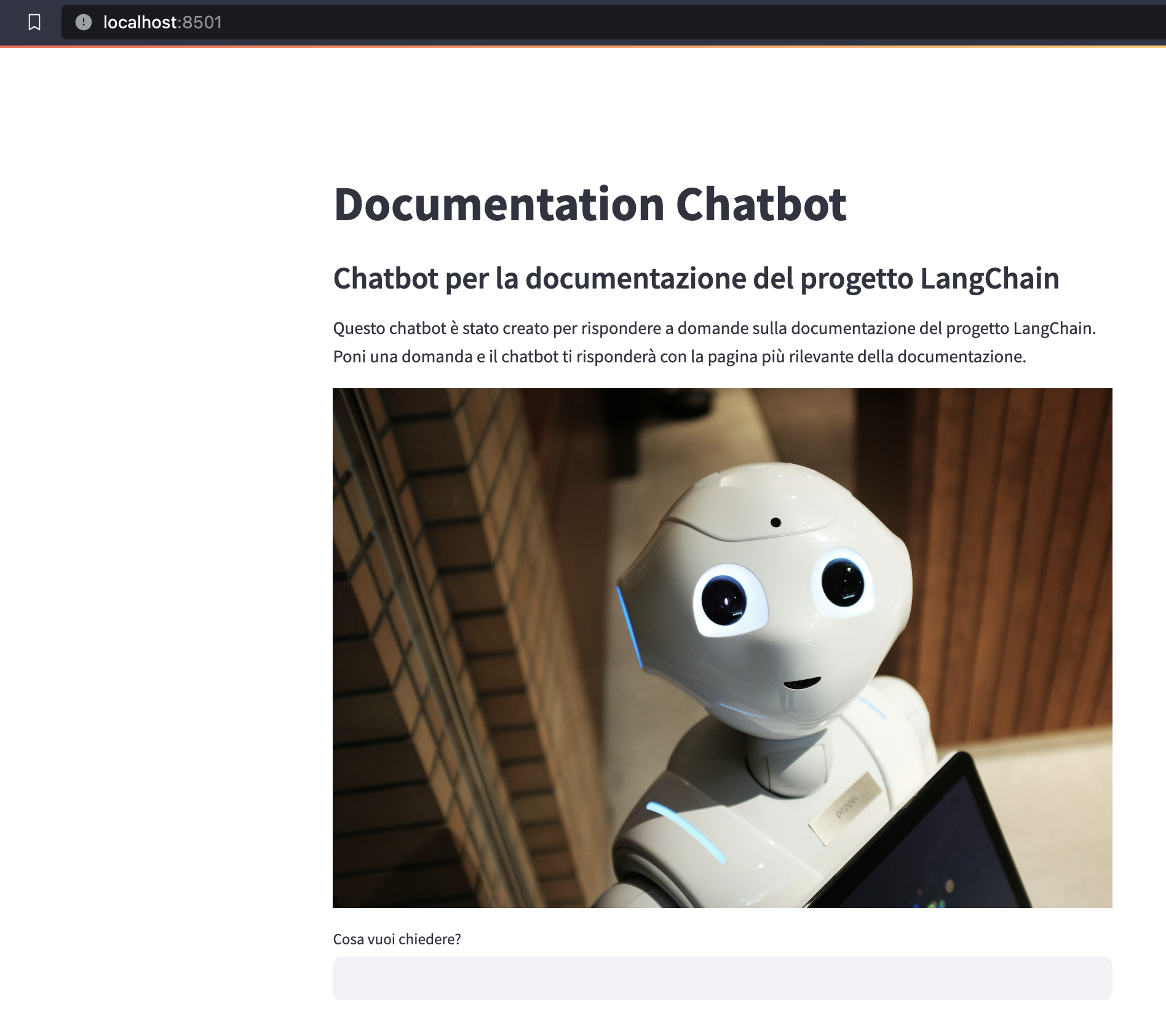
Prima di continuare, gestiamo la risposta dal punto di vista grafico creando uno stile con HTML e CSS. Creiamo una nuova funzione:
def handle_style_and_responses(user_question: str) -> None:
"""
Handle user input to create the chatbot conversation in Streamlit
Args:
user_question (str): User question
"""
response = st.session_state.conversation({"question": user_question})
st.session_state.chat_history = response["chat_history"]
human_style = "background-color: #e6f7ff; border-radius: 10px; padding: 10px;"
chatbot_style = "background-color: #f9f9f9; border-radius: 10px; padding: 10px;"
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.markdown(
f"<p style='text-align: right;'><b>Utente</b></p> <p style='text-align: right;{human_style}'> <i>{message.content}</i> </p>",
unsafe_allow_html=True,
)
else:
st.markdown(
f"<p style='text-align: left;'><b>Chatbot</b></p> <p style='text-align: left;{chatbot_style}'> <i>{message.content}</i> </p>",
unsafe_allow_html=True,
)Ora continuamo a scrivere il codice per ricevere risposta da GPT-4.
def main():
load_dotenv() # carichiamo le variabili d'ambiente
system_message_prompt = SystemMessagePromptTemplate.from_template(
"""
You are a chatbot tasked with responding to questions about the documentation of the LangChain library and project.
You should never answer a question with a question, and you should always respond with the most relevant documentation page.
Do not answer questions that are not about the LangChain library or project.
Given a question, you should respond with the most relevant documentation page by following the relevant context below:\n
{context}
"""
)
human_message_prompt = HumanMessagePromptTemplate.from_template("{question}")
if "vector_store" not in st.session_state:
st.session_state.vector_store = create_or_get_vector_store(chunks)
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.set_page_config(
page_title="Documentation Chatbot",
page_icon=":books:",
)
st.title("Documentation Chatbot")
st.subheader("Chatbot per la documentazione del progetto LangChain")
st.markdown(
"""
Questo chatbot è stato creato per rispondere a domande sulla documentazione del progetto LangChain.
Poni una domanda e il chatbot ti risponderà con la pagina più rilevante della documentazione.
"""
)
st.image("https://images.unsplash.com/photo-1485827404703-89b55fcc595e") # Immagine presa con diritti di citazione da Unsplash - ref. Alex Knight
user_question = st.text_input("Cosa vuoi chiedere?")
with st.spinner("Elaborando risposta..."):
if user_question:
handle_style_and_responses(user_question)
# create conversation chain
st.session_state.conversation = get_conversation_chain(
st.session_state.vector_store, system_message_prompt, human_message_prompt
)e...siamo pronti! Ricarichiamo Streamlit e vediamo cosa accade alla domanda "How do I split text?"
Il chatbot risponde con una risposta dettagliata, allegando anche link funzionanti alla pagina di LangChain sul web. Perfetto!
Conclusioni
Abbiamo visto come creare un chatbot con LangChain usando RAG.
RAG permette al database vettoriale di cercare i chunk informazionali più rilevanti alla query in input dell'utente e passarli a GPT-4 per la risposta.
Il trucchetto di inserire i metadati all'interno del chunk permette al chatbot di avere sempre l'informazione del link, descrizione e del titolo della pagina a portata di mano e può riportarlo su richiesta senza errori.
Alcune note utili:
- Cambiare il prompt di sistema per cambiare il comportamento del bot in ingresso
- Cambiare i separatori e la chunk size / overlap per cambiare la qualità del contesto recuperato
- È possibile usare modelli open source invece di GPT-4, basta cambiare la variabile
llmcon un modello Hugging Face usandoHuggingFaceHube un collegamento al modello stesso (vedere codebase intera in basso)
Nota finale: è possibile deployare l'applicazione Streamlit collegando il Github repository alla piattaforma Streamlit, basta cliccare sul tasto "Deploy" in alto a destra per più informazioni.
Codebase Python intera
Ecco la codebase del chatbot in formato copia-incolla
import pandas as pd
import os
from dotenv import load_dotenv
from langchain.document_loaders import DataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.llms import HuggingFaceHub
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
import streamlit as st
from pprint import pprint
def load_dataset(dataset_name:str="dataset.csv") -> pd.DataFrame:
"""
Load dataset from file_path
Args:
dataset_name (str, optional): Dataset name. Defaults to "dataset.csv".
Returns:
pd.DataFrame: Dataset
"""
data_dir = "./data"
file_path = os.path.join(data_dir, dataset_name)
df = pd.read_csv(file_path)
return df
def create_chunks(dataset:pd.DataFrame, chunk_size:int, chunk_overlap:int) -> list:
"""
Create chunks from the dataset
Args:
dataset (pd.DataFrame): Dataset
chunk_size (int): Chunk size
chunk_overlap (int): Chunk overlap
Returns:
list: List of chunks
"""
text_chunks = DataFrameLoader(
dataset, page_content_column="body"
).load_and_split(
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=0, length_function=len
)
)
# aggiungiamo i metadati ai chunk stessi per facilitare il lavoro di recupero
for doc in text_chunks:
title = doc.metadata["title"]
description = doc.metadata["description"]
content = doc.page_content
url = doc.metadata["url"]
final_content = f"TITLE: {title}\DESCRIPTION: {description}\BODY: {content}\nURL: {url}"
doc.page_content = final_content
return text_chunks
def create_or_get_vector_store(chunks: list) -> FAISS:
"""
Create or get vector store
Args:
chunks (list): List of chunks
Returns:
FAISS: Vector store
"""
embeddings = OpenAIEmbeddings()
#embeddings = HuggingFaceInstructEmbeddings()
if not os.path.exists("./db"):
print("CREATING DB")
vectorstore = FAISS.from_documents(
chunks, embeddings
)
vectorstore.save_local("./db")
else:
print("LOADING DB")
vectorstore = FAISS.load_local("./db", embeddings)
return vectorstore
def get_conversation_chain(vector_store:FAISS, system_message:str, human_message:str) -> ConversationalRetrievalChain:
"""
Get the chatbot conversation chain
Args:
vector_store (FAISS): Vector store
system_message (str): System message
human_message (str): Human message
Returns:
ConversationalRetrievalChain: Chatbot conversation chain
"""
llm = ChatOpenAI(model="gpt-4")
# llm = HuggingFaceHub(model="HuggingFaceH4/zephyr-7b-beta")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vector_store.as_retriever(),
memory=memory,
combine_docs_chain_kwargs={
"prompt": ChatPromptTemplate.from_messages(
[
system_message,
human_message,
]
),
},
)
return conversation_chain
def handle_style_and_responses(user_question: str) -> None:
"""
Handle user input to create the chatbot conversation in Streamlit
Args:
user_question (str): User question
"""
response = st.session_state.conversation({"question": user_question})
st.session_state.chat_history = response["chat_history"]
human_style = "background-color: #e6f7ff; border-radius: 10px; padding: 10px;"
chatbot_style = "background-color: #f9f9f9; border-radius: 10px; padding: 10px;"
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.markdown(
f"<p style='text-align: right;'><b>Utente</b></p> <p style='text-align: right;{human_style}'> <i>{message.content}</i> </p>",
unsafe_allow_html=True,
)
else:
st.markdown(
f"<p style='text-align: left;'><b>Chatbot</b></p> <p style='text-align: left;{chatbot_style}'> <i>{message.content}</i> </p>",
unsafe_allow_html=True,
)
def main():
load_dotenv()
df = load_dataset()
chunks = create_chunks(df, 1000, 0)
system_message_prompt = SystemMessagePromptTemplate.from_template(
"""
You are a chatbot tasked with responding to questions about the documentation of the LangChain library and project.
You should never answer a question with a question, and you should always respond with the most relevant documentation page.
Do not answer questions that are not about the LangChain library or project.
Given a question, you should respond with the most relevant documentation page by following the relevant context below:\n
{context}
"""
)
human_message_prompt = HumanMessagePromptTemplate.from_template("{question}")
if "vector_store" not in st.session_state:
st.session_state.vector_store = create_or_get_vector_store(chunks)
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.set_page_config(
page_title="Documentation Chatbot",
page_icon=":books:",
)
st.title("Documentation Chatbot")
st.subheader("Chatbot per la documentazione del progetto LangChain")
st.markdown(
"""
Questo chatbot è stato creato per rispondere a domande sulla documentazione del progetto LangChain.
Poni una domanda e il chatbot ti risponderà con la pagina più rilevante della documentazione.
"""
)
st.image("https://images.unsplash.com/photo-1485827404703-89b55fcc595e") # Immagine presa con diritti di citazione da Unsplash - ref. Alex Knight
user_question = st.text_input("Cosa vuoi chiedere?")
with st.spinner("Elaborando risposta..."):
if user_question:
handle_style_and_responses(user_question)
st.session_state.conversation = get_conversation_chain(
st.session_state.vector_store, system_message_prompt, human_message_prompt
)
if __name__ == "__main__":
main()




Commenti dalla community