
Queste rappresentazioni, chiamate embedding, sono utilizzate in molte attività di elaborazione del linguaggio naturale, come il clustering di parole, la classificazione e la generazione di testo.
L'algoritmo Word2Vec ha scandito l'inizio di una epoca nel mondo dell'NLP quando è stato introdotto per la prima volta da Google nel 2013.
Esso si basa sulle rappresentazioni di parole create da una rete neurale (da qui il termine embedding, incorporamenti in italiano) addestrata su corpus di dati molto grandi.
L'output di Word2Vec sono vettori, uno per ogni parola presente nel dizionario di addestramento, che catturano in maniera efficace relazioni tra le parole.
Vettori vicini nello spazio vettoriale hanno significati simili in base al contesto e i vettori distanti tra loro hanno significati diversi. Ad esempio, le parole "forte" e "potente" sarebbero vicini mentre "forti" e "Parigi" sarebbe relativamente lontani all'interno dello spazio vettoriale.
Questo è un notevole miglioramento rispetto alle performance del modello bag-of-words, che si basa sul semplice conteggio dei token presenti in un corpus di dati testuali.
In questo articolo andremo a esplorare Gensim, una libreria Python molto famosa per addestrare modelli di machine learning basati sul testo, per addestrare un modello Word2Vec da zero.
Useremo come dataset uno script presente nell'articolo
per reperire tutti i testi presenti in questo blog e usarli per addestrare un modello Word2Vec e mostrare come le parole usate nella scrittura siano relazionate tra di loro.
Questo permetterà a voi lettori di applicare lo script presente in questo post a qualsiasi scenario reale (a patto che il sito non sia completamente renderizzato in JavaScript) e creare voi stessi gli embedding e visualizzarli.
Iniziamo!
La ricetta per il progetto
Stiliamo una lista di azioni da fare per gettare le basi del progetto
- Creiamo un nuovo ambiente virtuale
(leggi qui per capire come: Come impostare un ambiente di sviluppo per il machine learning) - Installiamo le dipendenze, tra le quali Gensim
- Eseguiamo lo script per scaricare i dati dal nostro blog target (in questo caso useremo proprio Diario Di Un Analista)
- Prepariamo il nostro corpus per consegnarlo a Word2Vec
- Addestriamo il modello e lo salviamo
- Usiamo TSNE e Plotly per visualizzare gli embedding comprendere visivamente lo spazio vettoriale generato da Word2Vec
- BONUS: Useremo la libreria Datapane per creare un report interattivo in HTML da condividere con chi vogliamo
Alla fine del percorso avremo tra le mani un'ottima base per sviluppare ragionamenti più complessi, come clustering degli embedding.
Darò per scontato che abbiate già configurato il vostro ambiente correttamente, quindi non spiegherò in questo articolo come farlo. Partiamo subito con lo scaricare i dati del blog.
Le dipendenze da installare
Prima di iniziare assicuriamoci di installare le seguenti dipendenze a livello di progetto, eseguendo pip install XXXXX nel terminale.
trafilaturapandasgensimnltktqdmscikit-learnplotlydatapane
Inizializziamo anche un oggetto logger per ricevere i messaggi di Gensim in terminale.
Reperire il corpus di dati testuali
Come menzionato useremo lo script nel mio articolo linkato per scraperare questo blog e reperire gli articoli partendo dalla sitemap.
Creiamo uno script e incolliamo il seguente codice Python.
import pandas as pd
from tqdm import tqdm
from trafilatura.sitemaps import sitemap_search
from trafilatura import fetch_url, extract
from pprint import pprint
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
def get_urls_from_sitemap(resource_url: str) -> list:
"""
Funzione che crea un DataFrame Pandas di URL e articoli.
"""
urls = sitemap_search(resource_url)
return urls
def extract_article(url: str) -> dict:
"""
Estrae un articolo da una URL con Trafilatura
"""
downloaded = fetch_url(url)
article = extract(downloaded, favor_precision=True)
return article
def create_dataset(list_of_websites: list) -> pd.DataFrame:
"""
Funzione che crea un DataFrame Pandas di URL e articoli.
"""
data = []
for website in tqdm(list_of_websites, desc="Websites"):
urls = get_urls_from_sitemap(website)
for url in tqdm(urls, desc="URLs"):
d = {
'url': url,
"article": extract_article(url)
}
data.append(d)
time.sleep(0.5)
df = pd.DataFrame(data)
df = df.drop_duplicates()
df = df.dropna()
return df
if __name__ == "__main__":
list_of_websites = ["https://www.diariodiunanalista.it/"]
df = create_dataset(list_of_websites)
df.to_csv("dataset.csv", index=False)Abbiamo ora un file .csv nella nostra cartella di progetto che conterrà i dati in questo formato:
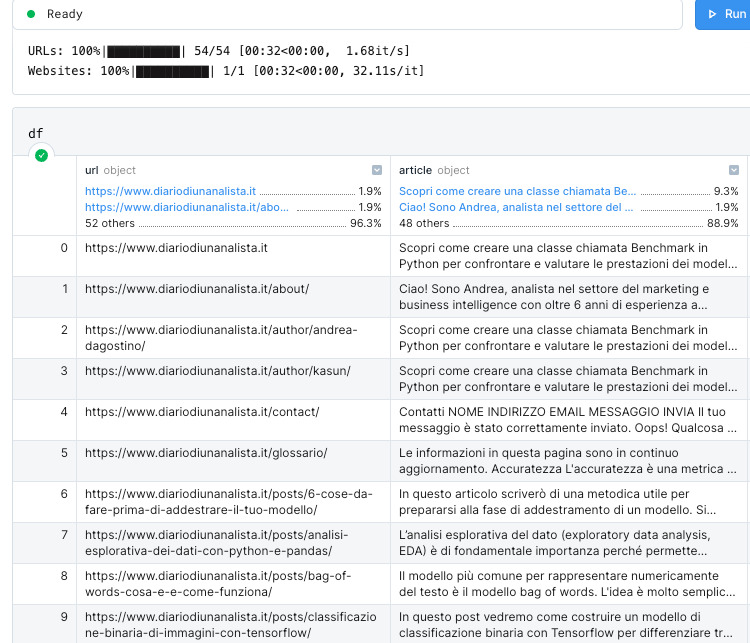
I dati testuali che andremo ad utilizzare sono sotto la colonna article. Vediamo come appare un testo preso a caso

Vediamo come questo debba essere processato prima di essere consegnato al modello Word2Vec. Dobbiamo andare a rimuovere le stopword italiane, pulire da punteggiatura, numeri e altri simboli. Questo sarà il prossimo step.
Preparazione del corpus di dati
La prima cosa da fare è importare delle dipendenze fondamentali per il preprocessing.
# librerie per la manipolazione del testo
import re
import string
import nltk
from nltk.corpus import stopwords
# nltk.download('stopwords') <-- eseguiamo questo comando per scaricare le stopword nel progetto
# nltk.download('punkt') <-- essenziale per la tokenizzazione
stopwords.words("italian")[:10]
>>> ['ad', 'al', 'allo', 'ai', 'agli', 'all', 'agl', 'alla', 'alle', 'con']Ora creiamo una funzione preprocess_text che prende in input un testo e restituisce una versione pulita dello stesso.
def preprocess_text(text: str, remove_stopwords: bool) -> str:
"""Funzione che pulisce il testo in input andando a
- rimuovere i link
- rimuovere i caratteri speciali
- rimuovere i numeri
- rimuovere le stopword
- trasformare in minuscolo
- rimuovere spazi bianchi eccessivi
Argomenti:
text (str): testo da pulire
remove_stopwords (bool): rimuovere o meno le stopword
Restituisce:
str: testo pulito
"""
# rimuovi link
text = re.sub(r"http\S+", "", text)
# rimuovi numeri e caratteri speciali
text = re.sub("[^A-Za-z]+", " ", text)
# rimuovere le stopword
if remove_stopwords:
# 1. crea token
tokens = nltk.word_tokenize(text)
# 2. controlla se è una stopword
tokens = [w.lower().strip() for w in tokens if not w.lower() in stopwords.words("italian")]
# restituisci una lista di token puliti
return tokensApplichiamo questa funzione al dataframe Pandas usando una funzione lambda con .apply.
df["cleaned"] = df.article.apply(lambda x: preprocess_text(x, remove_stopwords=True))Otteniamo una serie pulita.
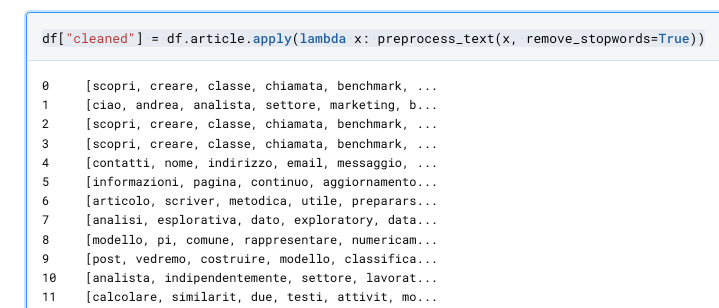
Esaminiamo un testo per vedere l'effetto del nostro preprocessing.
Il testo ora sembra essere pronto ad essere processato da Gensim. Continuamo.
Addestramento di Word2Vec
La prima cosa da fare è creare una variabile texts che conterrà i nostri testi.
texts = df.cleaned.tolist()Ora siamo pronti ad addestrare il modello. Word2Vec può accettare tanti parametri, ma per ora non preoccupiamocene. Addestrare il modello è semplice, e richiede una riga di codice.
from gensim.models import Word2Vec
model = Word2Vec(sentences=texts)
Il nostro modello è pronto e gli embedding sono stati creati. Per verificarlo, proviamo a trovare il vettore per la parola overfitting.
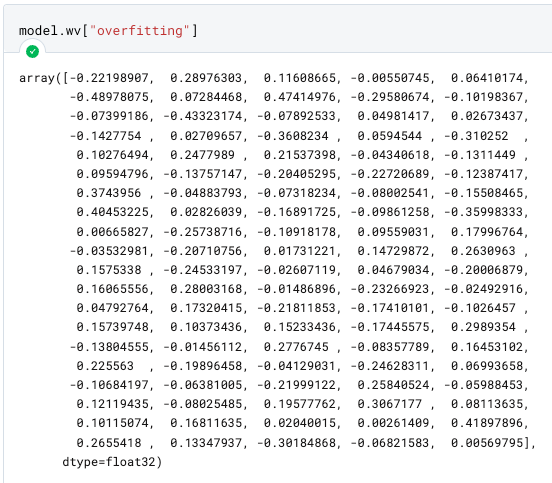
Di default, Word2Vec crea vettori 100-dimensionali. Questo parametro può essere modificato, insieme a tanti altri, quando istanziamo la classe. In ogni caso, più dimensioni sono associate ad una parola, più informazioni avrà la rete neurale sulla parola stessa e la sua relazione alle altre.
Ovviamente questo ha un costo computazionale e di memoria più elevato.
Nota bene: una delle limitazioni più importanti di Word2Vec è l'inabilità di generare vettori per parole non presenti nel vocabolario (chiamate OOV - out of vocabulary words).
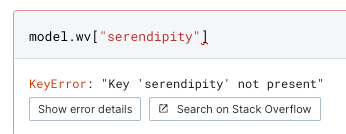
Per gestire parole nuove, quindi, bisogna addestrare un nuovo modello oppure aggiungere i vettori manualmente.
Calcolare la similarità tra due parole
Con il coseno di similarità possiamo calcolare quanto distanti siano vettori nello spazio.
Con il comando di seguito istruiamo Gensim a trovare le prime 3 parole più simili a overfitting
model.wv.most_similar(positive=['overfitting'], topn=3))
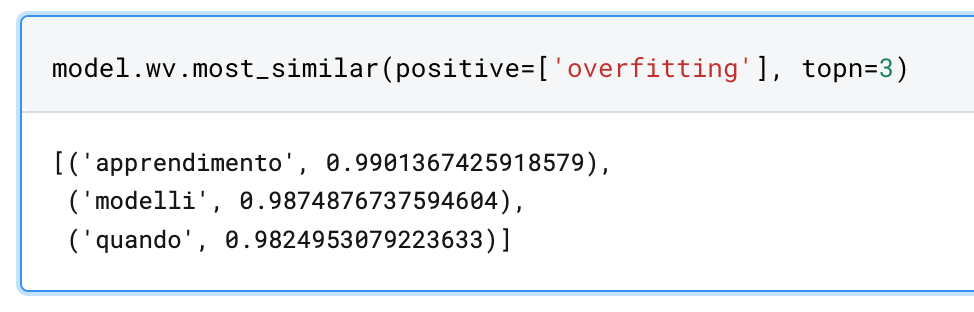
Vediamo come la parola "quando" sia presente in questo risultato. Sarà il caso di includere nelle stop word anche avverbi simili per pulire i risultati.
Per salvare il modello, basta fare model.save("./percorso/al/modello").
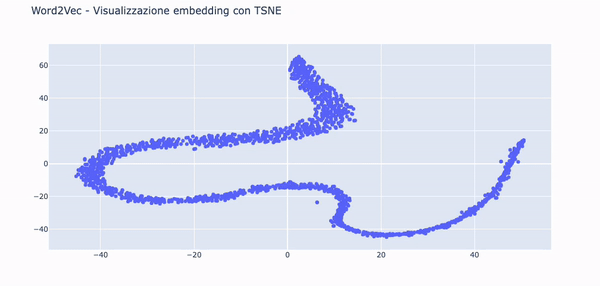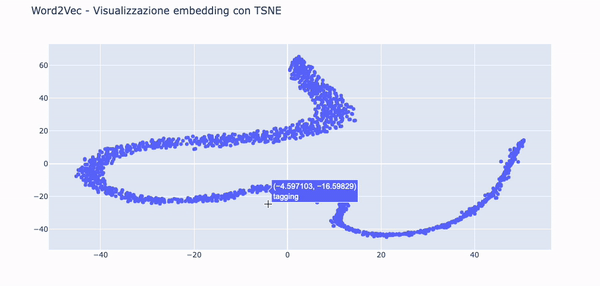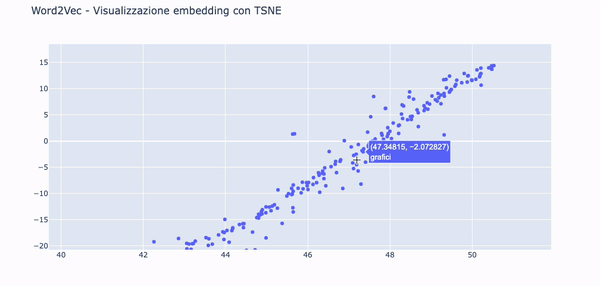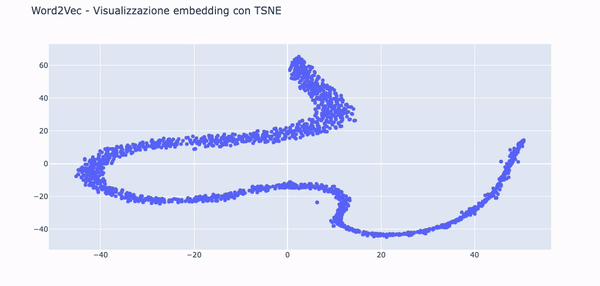
Visualizzare gli embedding con TSNE e Plotly
I nostri vettori sono 100-dimensionali. È un problema visualizzarli a meno che non facciamo qualcosa per ridurre la loro dimensionalità.
Useremo la tecnica TSNE per ridurre la dimensionalità dei vettori e creare due componenti, una per l'asse X e l'altra per la Y su un grafico a dispersione.
Nella .gif in basso è possibile vedere le parole embeddate nello spazio grazie alle funzionalità di Plotly.
Ecco il codice per generare questa immagine.
def reduce_dimensions(model):
num_components = 2 # numero di dimensioni da mantenere in seguito alla compressione
# estraiamo il vocabolario dal modello e i vettori in modo da associarli nel grafico
vectors = np.asarray(model.wv.vectors)
labels = np.asarray(model.wv.index_to_key)
# applichiamo TSNE
tsne = TSNE(n_components=num_components, random_state=0)
vectors = tsne.fit_transform(vectors)
x_vals = [v[0] for v in vectors]
y_vals = [v[1] for v in vectors]
return x_vals, y_vals, labels
def plot_embeddings(x_vals, y_vals, labels):
import plotly.graph_objs as go
fig = go.Figure()
trace = go.Scatter(x=x_vals, y=y_vals, mode='markers', text=labels)
fig.add_trace(trace)
fig.update_layout(title="Word2Vec - Visualizzazione embedding con TSNE")
fig.show()
return fig
x_vals, y_vals, labels = reduce_dimensions(model)
plot = plot_embeddings(x_vals, y_vals, labels)
Questa visualizzazione può essere utile per notare tendenze semantiche e sintattiche nei dati.
Ad esempio, è molto utile per mettere in risalto anomalie, come gruppi di parole che tendono a raggrupparsi insieme per un qualche motivo.
Parametri di Word2Vec
Guardando sul sito di Gensim vediamo che i parametri sono parecchi. I più importanti sono vectors_size, min_count, window e sg.
- vectors_size: definisce le dimensioni del nostro spazio vettoriale.
- min_count: le parole al di sotto della frequenza min_count vengono rimosse dal vocabolario prima dell'addestramento.
- window: distanza massima tra la parola corrente e quella prevista all'interno di una frase.
- sg: definisce l'algoritmo di addestramento. 0 = CBOW (continuous bag of words), 1 = Skip-Gram.
Non andremo nel dettaglio in ognuno di questi. Suggerisco al lettore interessato di dare una occhiata alla documentazione di Gensim.
Proviamo a riaddestrare il nostro modello con i seguenti parametri
VECTOR_SIZE = 100
MIN_COUNT = 5
WINDOW = 3
SG = 1
new_model = Word2Vec(sentences=texts, vector_size=VECTOR_SIZE, min_count=MIN_COUNT, sg=SG)
x_vals, y_vals, labels = reduce_dimensions(new_model)
plot = plot_embeddings(x_vals, y_vals, labels)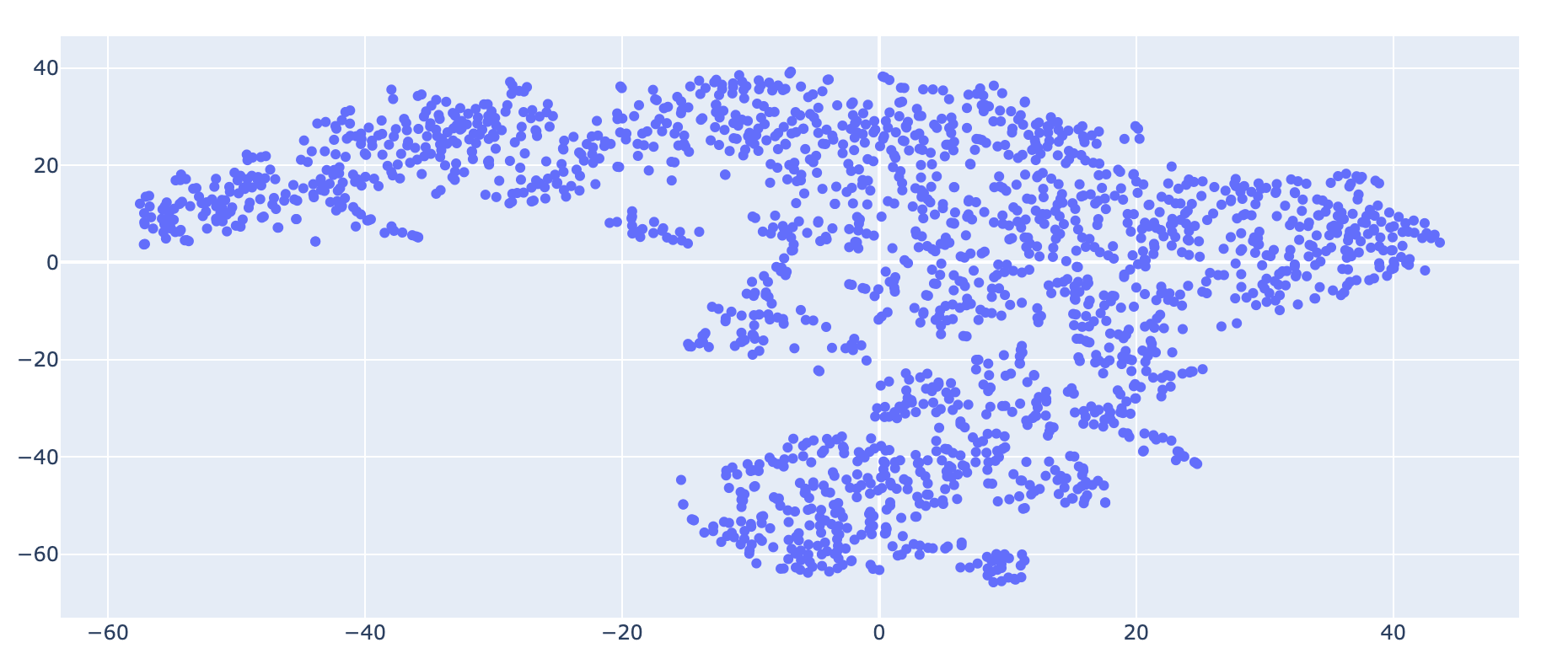
Vediamo come la rappresentazione cambi molto. Il numero di vettori è uguale a quello precedente (Word2Vec ha come default 100), mentre min_count, window e sgsono stati cambiati dai valori di default.
Suggerisco al lettore di cambiare questi parametri per comprendere quale rappresentazione sia più la adeguata alla propria casistica.
BONUS: Creare un report interattivo con Datapane
Siamo arrivati alla fine dell'articolo. Concludiamo il progetto andando a creare un report interattivo in HTML con Datapane, che permetterà all'utente di visualizzare direttamente in browser il grafico creato precedentemente con Plotly.
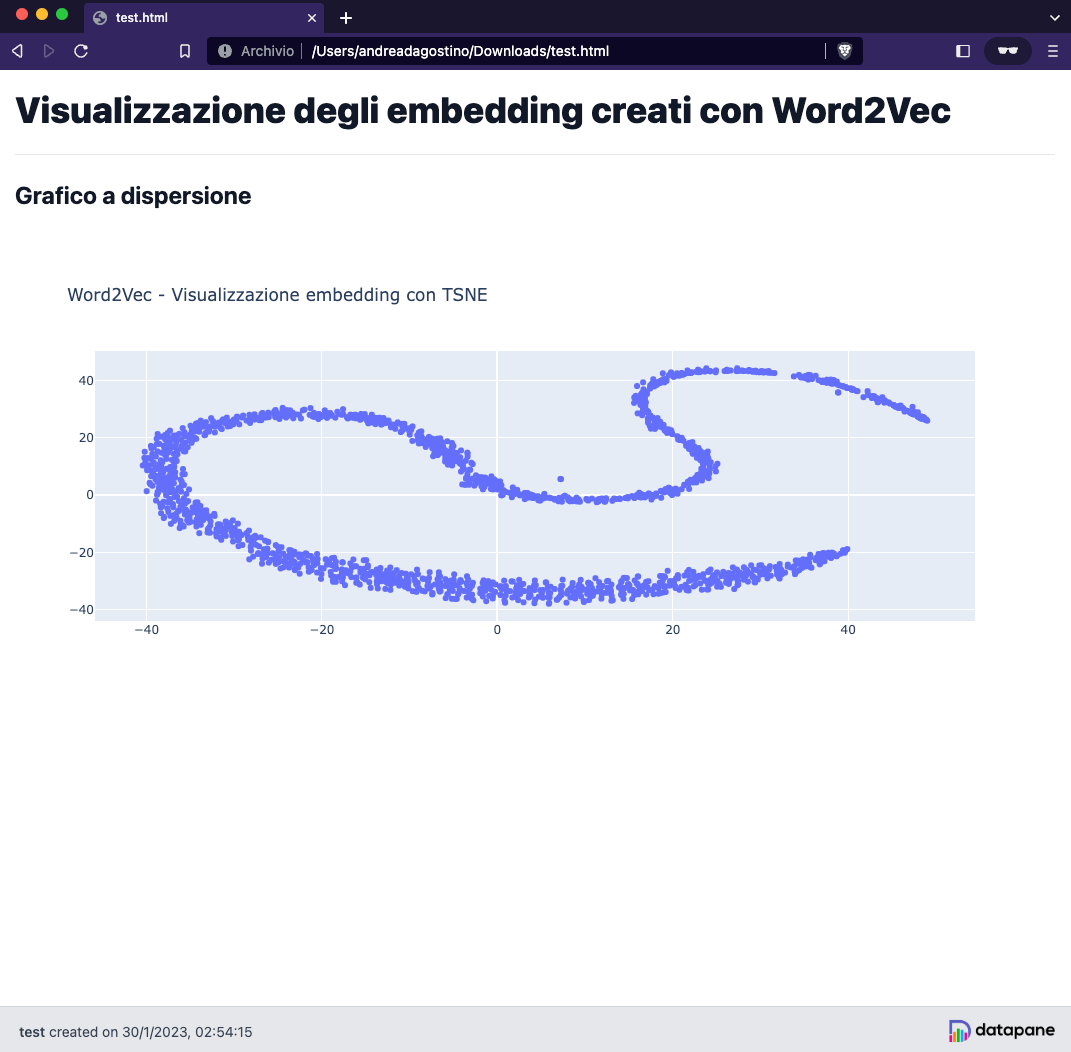
e questo è il codice Python
import datapane as dp
app = dp.App(
dp.Text(text='# Visualizzazione degli embedding creati con Word2Vec'),
dp.Divider(),
dp.Text(text='## Grafico a dispersione'),
dp.Group(
dp.Plot(plot),
columns=1,
),
)
app.save(path="test.html")Datapane è altamente customizzabile. Consiglio al lettore di studiare la documentazione per integrare estetica e altre funzionalità.
Conclusioni
Abbiamo visto come costruire degli embedding da zero usando Gensim e Word2Vec. La cosa è molto semplice da fare se si ha un dataset strutturato e se si conosce l'API di Gensim.
Con gli embedding possiamo fare veramente tante cose, ad esempio
- fare clustering dei documenti, visualizzando tali cluster nello spazio vettoriale
- fare ricerca su similarità tra le parole
- usare gli embedding come feature in un modello di machine learning
- gettare le basi per la machine translation
e molto altro. Se siete interessati ad un argomento che estende quello trattato qui, lasciate un commento nel box qui sotto 👍
Con questo progetto potete arricchire il vostro portfolio di template per NLP e comunicare ad uno stakeholder expertise nel trattare documenti testuali nel contesto del machine learning.
Come sempre, se avete bisogno di me o volete condividere qualche pensiero, contattatemi sui social o attraverso il blog.
A presto 👋





Commenti dalla community