
Tabella dei Contenuti
- Motivazione per il processo di analisi esplorativa
- Librerie necessarie per l’analisi esplorativa
- 1. Importazione di un dataset di lavoro
- 2. Comprensione del quadro generale
- Proprietà e funzioni utili di Pandas
- Qual è il nostro obiettivo?
- 3. Preparazione
- 4. Comprensione delle variabili
- 4. Studio delle relazioni tra variabili
- 5. Brainstorming
- L’importanza di porsi le domande giuste
- Quale visualizzazione scegliere?
- Conclusione
Questo articolo ha l'obiettivo di comunicarti cosa sia una analisi esplorativa e come farla praticamente con Python e Pandas.
L’analisi esplorativa del dato (exploratory data analysis, EDA) è di fondamentale importanza perché permette all’analista di conoscere a fondo il dataset sul quale lavora, stipulare o scartare ipotesi e creare dei modelli predittivi su basi solide.
Essa utilizza tecniche manipolazione dei dati e diversi concetti di statistica per comprendere con quali variabili lavoriamo, come esse sono relazionate tra di loro e come possono impattare sul business.
Infatti, è grazie alla EDA che possiamo porci delle domande che abbiano senso lato business.
- Cosa è l'analisi esplorativa e come farla in Python con Pandas
- Tante funzioni e logiche per l'interrogazione dei dati
- Un template intuitivo e replicabile da applicare nel tuo workflow
- Preparare i dati per creare un report business-oriented o modelli di machine learning
Questa è messa in atto attraverso l’utilizzo della libreria Pandas - strumento essenziale per qualsiasi analista che lavora con Python.
Essa è composta da diversi step:
- Importazione di un dataset di lavoro
- Comprensione del quadro generale
- Preparazione
- Comprensione delle variabili
- Studio delle relazioni tra variabili
- Brainstorming
Questo template è frutto di tante iterazioni e mi permette di giungere velocemente al pormi delle domande sensate sui dati che ho di fronte.
Alla fine del processo, saremo in grado di consolidare un report per il business oppure di continuare con la fase di modellazione del dato.
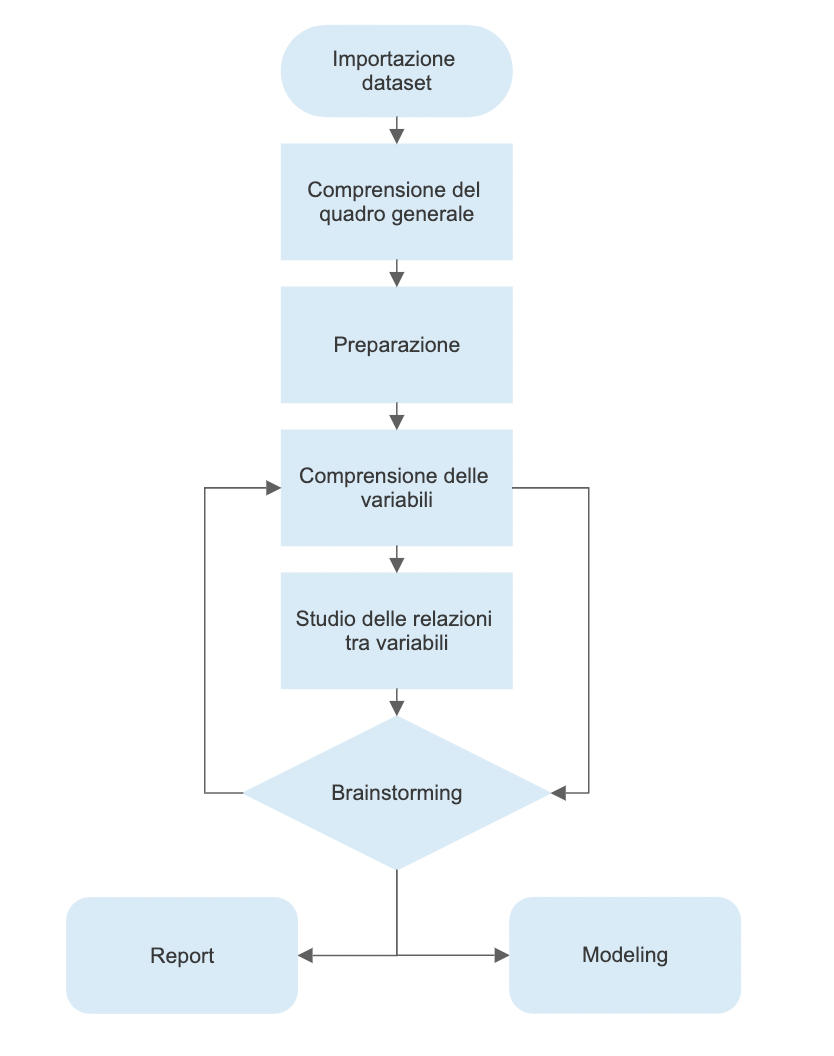
Vediamo nell’immagine in basso come la fase di brainstorming sia collegata con quella della comprensione delle variabili e come questa sia a sua volta collegata di nuovo con quella del brainstorming.
Questo processo descrive come possiamo muoverci per formulare nuove domande finché non siamo soddisfatti.
Vedremo alcune delle funzionalità di Pandas più comuni e importanti e anche alcune tecniche per manipolare il dato in modo da comprenderlo a fondo.
Motivazione per il processo di analisi esplorativa
Ho scoperto con il tempo e con l’esperienza che una grossa fetta di aziende cercano insight e valore che provengono da attività fondamentalmente descrittive.
Questo significa che spesso e volentieri le aziende sono disposte ad allocare parecchie risorse per acquisire la consapevolezza necessaria del fenomeno che noi analisti stiamo andando a studiare.
La conoscenza di qualcosa.
Se siamo abili a investigare il dato e a porci le domande giuste, il processo EDA diventa estremamente potente.
Unendo abilità di data visualization, un analista abile è in grado di costruire una carriera solo facendo leva su queste abilità.
Non occorre nemmeno andare nella modellistica.
Un buon approccio alla EDA permette quindi di fornire valore aggiunto a molti contesti di business, soprattutto dove il nostro cliente/capo trova difficoltà di natura interpretative o di accesso al dato.
Questa è l’idea di base che mi ha portato a mettere giù un template del genere.
Ho scritto un thread su Twitter che mette nero su bianco il mio pensiero al riguardo
[Data Analysis] 🧵
— Andrea D'Agostino (@theDrewDag) May 4, 2022
Exploratory data analysis is a fundamental step in any analysis work. You don't have to be a data scientist and be proficient at modeling to be a useful asset to your client if you can do great EDA.
Here's a template of a basic yet powerful EDA workflow👇
Librerie necessarie per l’analisi esplorativa
Prima di iniziare vediamo quali sono le librerie fondamentali richieste per svolgere l’EDA.
Ci sono molte librerie utili (alcune anche che fanno parte del lavoro in automatico) ma qui vedremo solo quelle che utilizza questo template
# manipolazione dati
import pandas as pd
import numpy as np
# visualizzazione
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns
# applichiamo uno stile piacevole alla vista e settiamo i parametri di visualizzazione
plt.style.use("ggplot")
rcParams['figure.figsize'] = (12, 6)
# usiamo sklearn per caricare un dataset di esempio
from sklearn.datasets import load_wine1. Importazione di un dataset di lavoro
La pipeline di analisi dati inizia con l’importazione o la creazione di un dataset di lavoro. La fase di analisi esplorativa inizia subito dopo.
Importare un dataset è semplice con Pandas attraverso delle funzioni dedicate alla lettura del dato. Se il nostro dataset è un file .csv, basta scrivere
df sta per dataframe, che è l’oggetto di Pandas simile ad un foglio Excel. Questa nomenclatura viene usata spesso. La funzione read_csv prende come input il percorso del file che vogliamo leggere. Ci sono molti altri argomenti che possiamo specificare.
Il formato .csv non è l’unico che possiamo importare - ce ne sono di fatto molti altri come Excel, Parquet e Feather.
Per facilità, in questo esempio useremo Sklearn per importare il wine dataset. Questo dataset è molto usato nel settore per fini educativi e contiene informazioni sulla composizione chimica di vini per un task di classificazione.
Non useremo un .csv ma un dataset presente in Sklearn per creare il dataframe
# carichiamo il dataset
wine = load_wine()
# convertiamo il dataset in un dataframe Pandas
df = pd.DataFrame(data=wine.data, columns=wine.feature_names)
# creiamo la colonna per il target
df["target"] = wine.target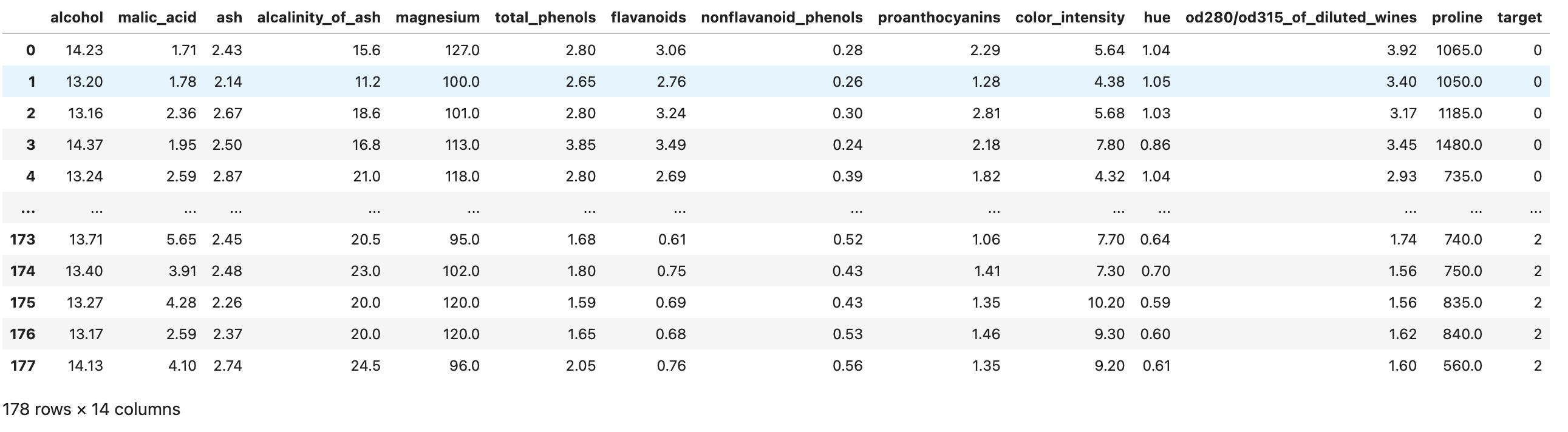
Ora che abbiamo importato un dataset usabile, passiamo all’applicazione della pipeline di EDA.
Exploratory Data Analysis
Un corso gratuito della Johns Hopkins University per imparare a esplorare, visualizzare e comprendere i dati attraverso grafici, tecniche statistiche e modelli. Parte della celebre specializzazione in Data Science su Coursera.

2. Comprensione del quadro generale
In questa prima fase il nostro obiettivo è capire cosa abbiamo di fronte, ma senza andare nel dettaglio.
Cerchiamo di capire il problema che vogliamo andare a risolvere, andando a ragionare sull’intero dataset e sul significato delle variabili.
Questa fase può essere lenta e a volte anche noiosa, ma ci darà modo di farci una opinione del nostro dataset.
Prendiamo degli appunti
Solitamente apro Excel oppure un file di testo in VSCode per segnare queste informazioni:
- Variabile: nome della variabile
- Tipo: il tipo o formato della variabile. Questo può essere categoriale, numerica, booleana e così via
- Contesto: informazioni utili per comprendere lo spazio semantico della variabile. Nel caso del nostro dataset, il contesto è sempre quello chimico-fisico, quindi è facile. In un altro contesto, ad esempio quello dell’immobiliare, una variabile potrebbe appartenere ad un segmento particolare, come quello dell’anatomia del materiale oppure quello sociale (quanti vicini di casa ci sono?)
- Aspettativa: quanto è rilevante questa variabile rispetto al nostro task? Decliniamo la nostra opinione in “Alta, Media, Bassa”.
- Commenti: se abbiamo o meno dei commenti da fare sulla variabile
Di tutte queste, la colonna Aspettativa è una delle più importanti perché ci aiuta a sviluppare il “sesto senso” dell’analista - a mano a mano che accumuliamo esperienza sul campo riusciremo a mappare mentalmente quali variabili sono rilevanti e quali no.
In ogni caso, il punto di svolgere questa attività è che ci mette in condizione di fare delle riflessioni preliminari sui nostri dati, il che ci aiuta a iniziare il processo di analisi.
Proprietà e funzioni utili di Pandas
Faremo leva su diverse funzioni e proprietà di Pandas per comprendere il quadro generale. Vediamone alcune.
Funzioni .head() e .tail()
Due delle funzioni più usate in assoluto in Pandas sono .head() e .tail(). Queste due permettono di visualizzare un numero arbitrario di righe (di default 5) dall’inizio o dalla fine del dataset. Molto utili per accedere ad una piccola parte del dataframe in modo veloce.

Attributo .shape
Se applichiamo .shape sul dataset, Pandas ci restituisce una coppia di numeri che rappresentano la dimensionalità del nostro dataset. Questa proprietà è molto utile per capire il numero di colonne e la lunghezza del dataset.

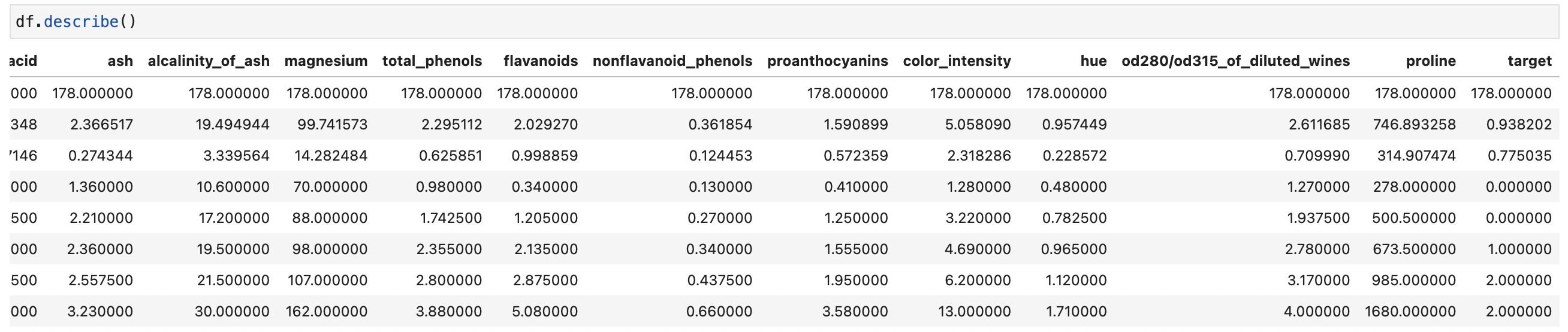
Funzione .describe()
La funzione describe fa esattamente questo: fornisce delle informazioni puramente descrittive del dataset. Queste informazioni includono delle statistiche che riassumono la tendenza centrale della variabile, la loro dispersione, la presenza di valori vuoti e la loro forma.
Funzione .info()
A differenza di .describe(), .info() ci fornisce un sommario più breve del nostro dataset. Ci restituisce informazioni sul tipo di dato, valori non nulli e utilizzo di memoria.
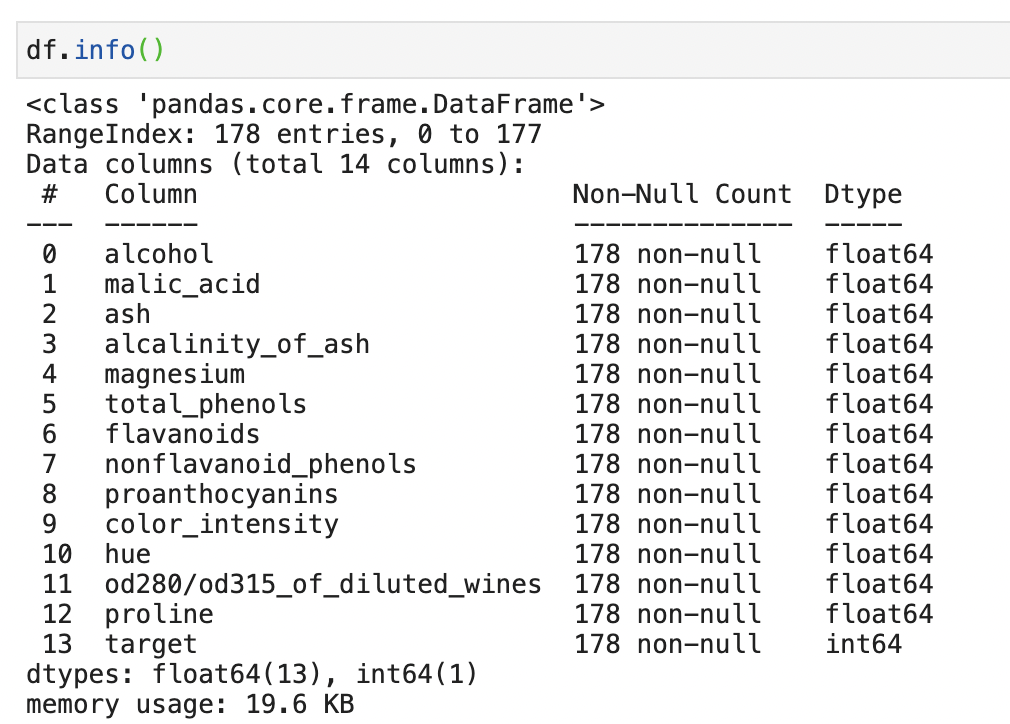
Esistono anche .dtypes e .isna() che ci danno rispettivamente il tipo di dato e se il valore è nullo o meno. Usare .info() però permette di accedere a queste informazioni in un singolo comando.
Qual è il nostro obiettivo?
Questa è una domanda importante che dobbiamo sempre porci. Nel nostro caso, vediamo come il target sia una variabile categoriale numerica che copre i valori di 0, 1 e 2. Questi numeri identificano il tipo di vino.
Se usiamo la documentazione di Sklearn su questo dataset vediamo sia stato costruito proprio per task di classificazione. Se volessimo fare modeling, l’idea sarebbe quindi di usare le caratteristiche del vino per predirne il tipo.
In un setting di analisi dati invece, vedremo come i diversi tipi di vino abbiano caratteristiche differenti e come queste sono distribuite.
3. Preparazione
In questa fase vogliamo iniziare a pulire il nostro dataset in modo da continuare l’analisi. Alcune delle domande che ci faremo sono
- esistono variabili inutili o ridondanti?
- ci sono delle colonne duplicate?
- la nomenclatura ha senso?
- ci sono delle nuove variabili che vogliamo creare?
Vediamo come applicare questi ragionamenti al nostro dataset.
Rispondendo ad ogni domanda qui, vediamo come
- Tutte le variabili sembrano essere misure chimico-fisiche. Questo significa che potrebbero essere tutte utili e contribuire a definire il segmentare il tipo di vino. Non abbiamo motivo di rimuovere delle colonne
- Per verificare la presenza di righe duplicate possiamo usare
.isduplicated().sum()- questo ci stamperà il numero di righe duplicated nel nostro dataset
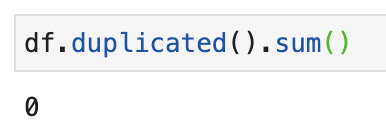
- La nomenclatura può essere sicuramente ottimizzata. Ad esempio
od280/od315_of_diluted_winesè difficile da capire. Poiché indica una metodologia di ricerca che serve per capire la concentrazione di proteine nel liquido, la chiameremoprotein_concentration
df.rename(columns={"od280/od315_of_diluted_wines": "protein_concentration"}, inplace=True)- Una delle metodiche più comuni di feature engineering è quella di creare delle nuove feature che siano la combinazione lineare / polinomiale di quelle esistenti. Questa diventa utile per fornire più informazioni ad un modello predittivo per migliorare le sue performance. Non lo faremo nel nostro caso
Essendo un dataset fantoccio, esso è praticamente già preparato per noi. Rimangono comunque dei punti utili da seguire per dataset più complessi.
4. Comprensione delle variabili
Mentre nel punto precedente siamo a descrivere il dataset per intero, ora cerchiamo di descrivere puntualmente tutte le variabili che ci interessano. Per questo motivo, questa fase può essere anche chiamata analisi univariata.
Variabili categoriali
In italiano conteggio_valori, è una delle funzioni più importanti per comprendere quanti valori di una determinata variabile ci sono nel nostro dataset. Prendiamo ad esempio la variabile target.
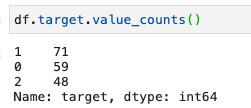
È possibile anche esprimere i dati in percentuale passando normalize=True
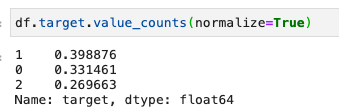
A questa funzione possiamo aggiungere anche un grafico con
df.target.value_counts().plot(kind="bar")
plt.title("Conteggio valori della variabile target")
plt.xlabel("Tipo di vino")
plt.xticks(rotation=0)
plt.ylabel("Conteggio")
plt.show()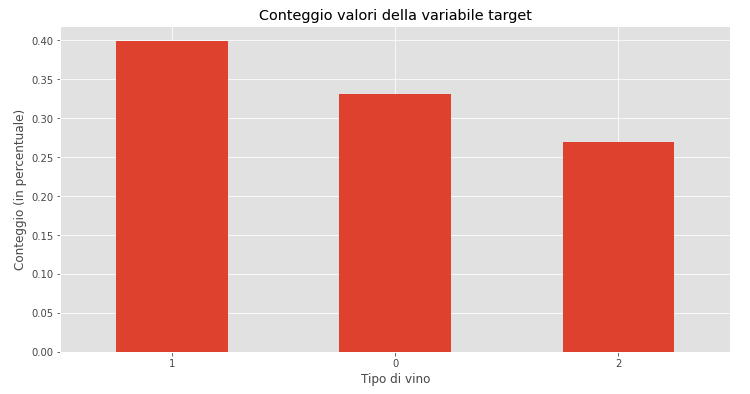
value_counts() può essere usata con qualsiasi variabile, ma funziona al meglio con variabili categoriali come il nostro target.
Questa funzione ci informa anche di quanto bilanciate siano le classi all’interno del dataset. Vediamo come la classe 2 sia inferiore alle altre due classi - nella fase di modeling forse possiamo implementare delle tecniche di bilanciamento del dato per non confondere il nostro modello.
Variabili numeriche
Se invece vogliamo analizzare una variabile numerica, possiamo descrivere la sua distribuzione con describe() come abbiamo visto prima e possiamo visualizzarla con .hist().
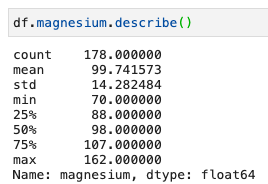
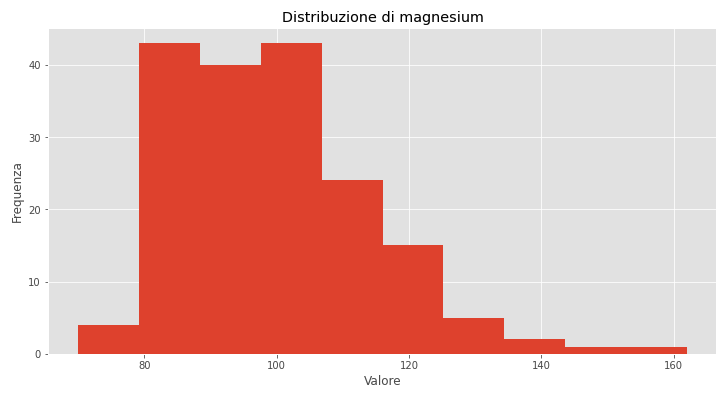
Prendiamo ad esempio la variabile magnesium
Prima .describe()
e poi l’istogramma
Valutiamo anche la curtosi e asimmetria della distribuzione:
print(f"Curtosi: {df['magnesium'].kurt()}")
print(f"Asimmetria: {df['magnesium'].skew()}")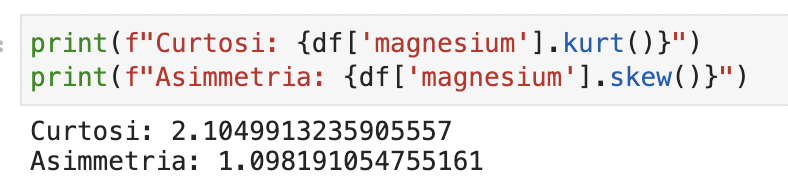
Da queste informazioni vediamo quindi come la distribuzione:
- non segua una curva normale
- mostri dei picchi
- abbia valori di curtosi e asimmetria maggiori di 1
Facciamo questo per ogni variabile, e avremo un quadro descrittivo pseudo completo del loro comportamento.
Questo lavoro ci serve per comprendere a fondo ogni variabile, e sblocca lo studio della relazione tra variabili.
4. Studio delle relazioni tra variabili
Ora l’idea è quella di trovare relazioni interessanti che mostrano influenza di una variabile sull’altra, preferibilmente sul target.
Questo lavoro sblocca le prime opzioni di intelligence - in un contesto lavorativo come il marketing digitale o nell’advertising online, queste informazioni offrono valore e possibilità di agire strategicamente.
Possiamo iniziare a esplorare le relazioni con l’aiuto di Seaborn e pairplot.
sns.pairplot(df)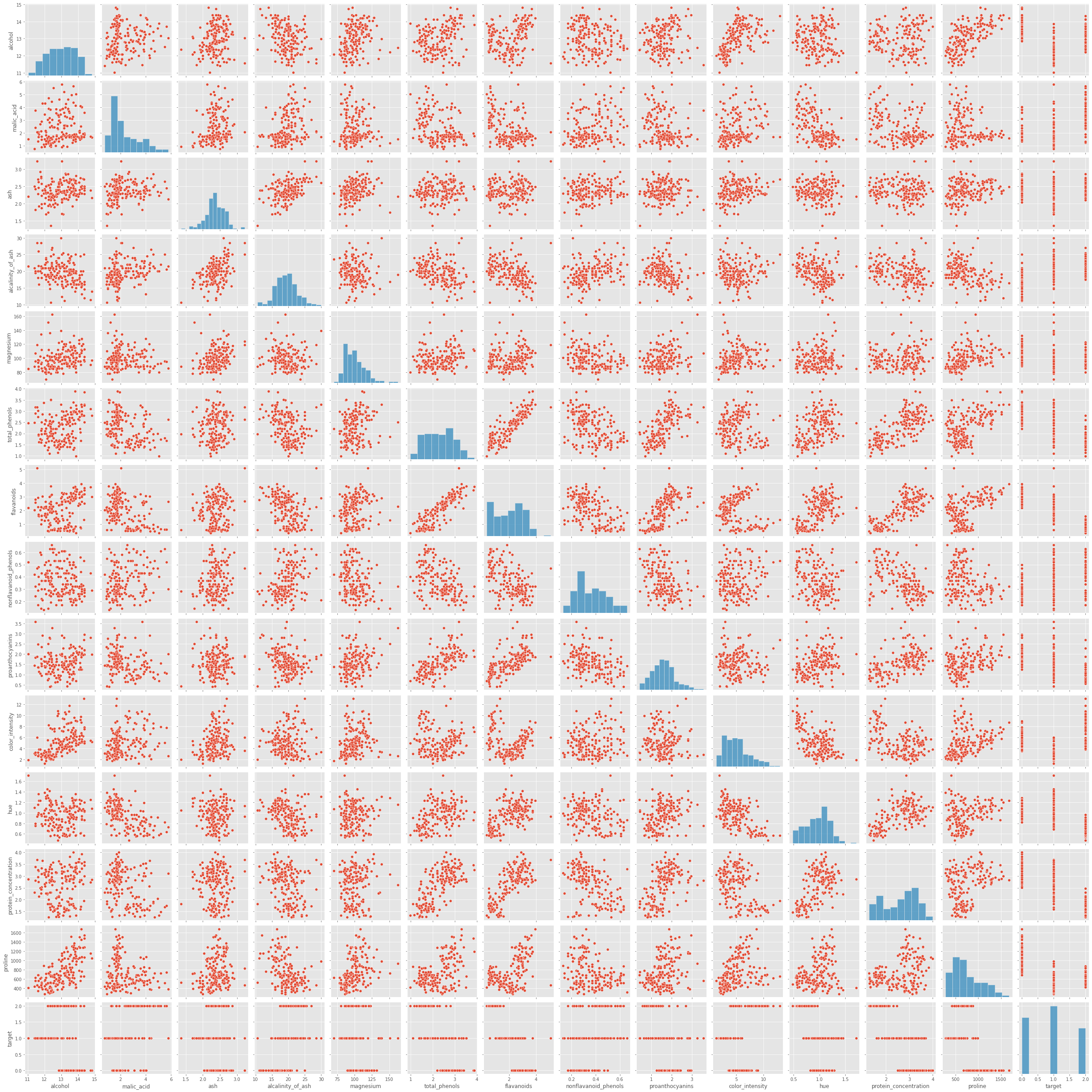
Com’è possibile notare, pairplot visualizza in un diagramma a dispersione tutte le variabili una contro l’altra. È molto utile per cogliere le relazioni più importanti senza dover andare a spulciare ogni singola combinazione manualmente.
Attenzione però - è computazionalmente pesante da calcolare, quindi è più adatto per dataset con un numero di variabili relativamente basso come questo.
Analizziamo il pairplot partendo dal target

Il modo migliore per comprendere la relazione tra una variabile numerica e variabile categoriale è attraverso un boxplot. Creiamo un boxplot per alcohol, flavanoids, color_intensity e proline.
Perché queste variabili? Perché a occhio mostrano delle segmentazioni un po’ più marcate per un determinato tipo. Ad esempio, guardiamo proline vs target
sns.catplot(x="target", y="proline", data=df, kind="box", aspect=1.5)
plt.title("Boxplot per target e proline")
plt.show()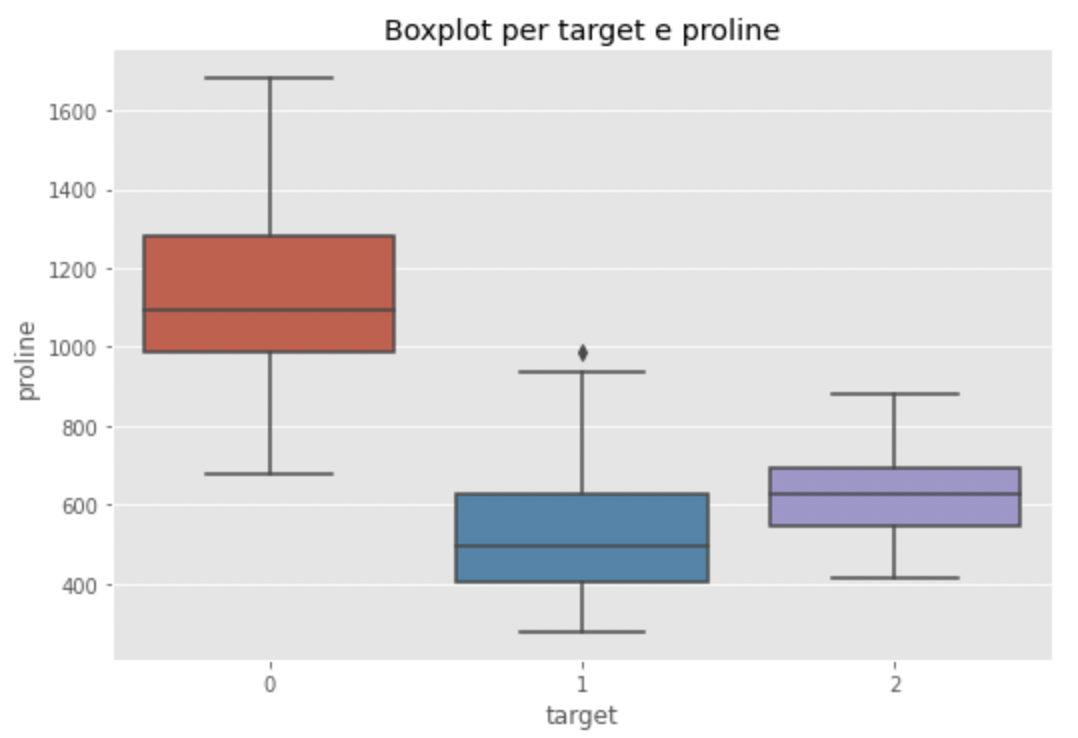
Vediamo infatti come la mediana di proline del vino tipo 0 sia più lata di quella degli altri due tipi. Che sia un fattore differenziante? Troppo presto per dirlo. Potrebbero esserci altre variabili da considerare. Vediamo flavanoids ora
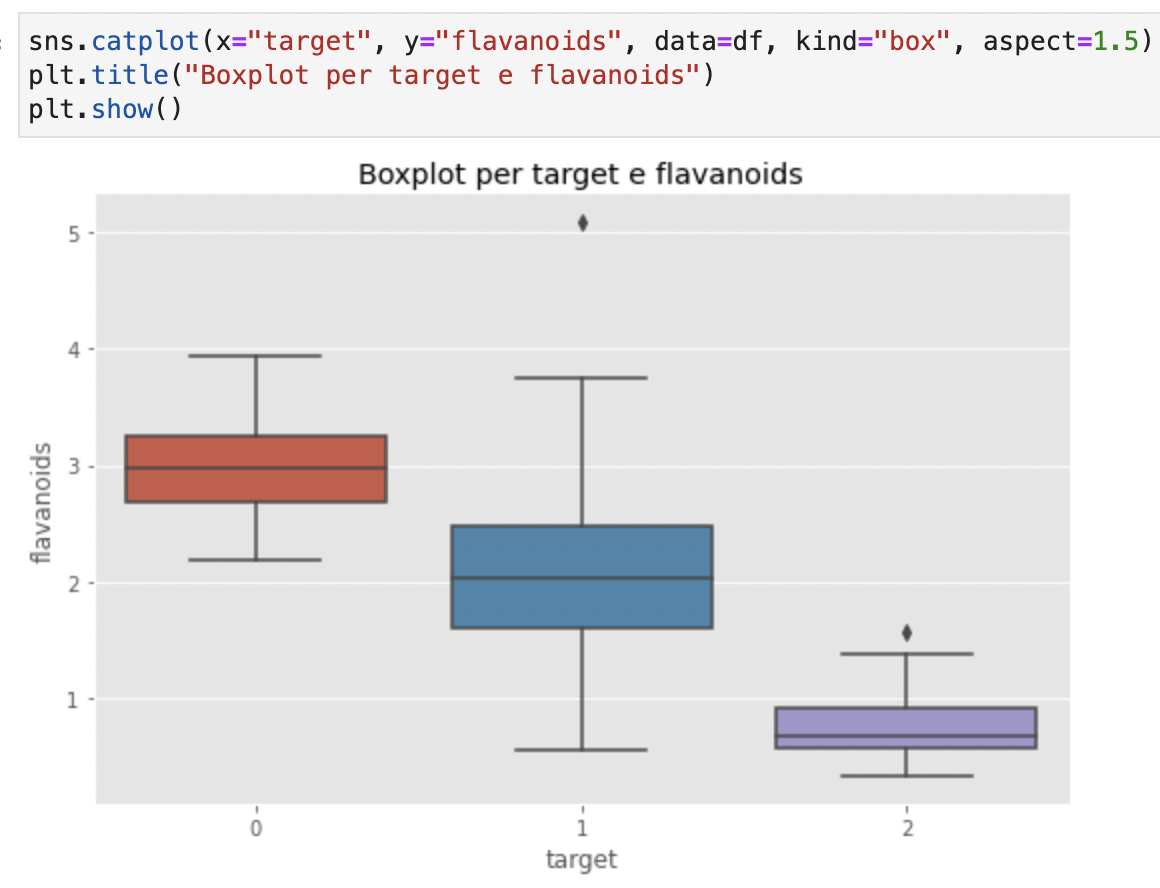
Anche qui, il vino tipo 0 sembra avere dei valori più alti di flavanoidi. Possibile che i vini tipo 0 abbiano livelli combinati più alti di proline e flavanoids?
Con Seaborn è possibile creare un diagramma a dispersione e visualizzare a quale classe di vini appartiene un punto. Basta specificare il parametro hue
sns.scatterplot(x="proline", y="flavanoids", hue="target", data=df, palette="Dark2", s=80)
plt.title("Relazione tra proline, flavanoids e target")
plt.show()
view raw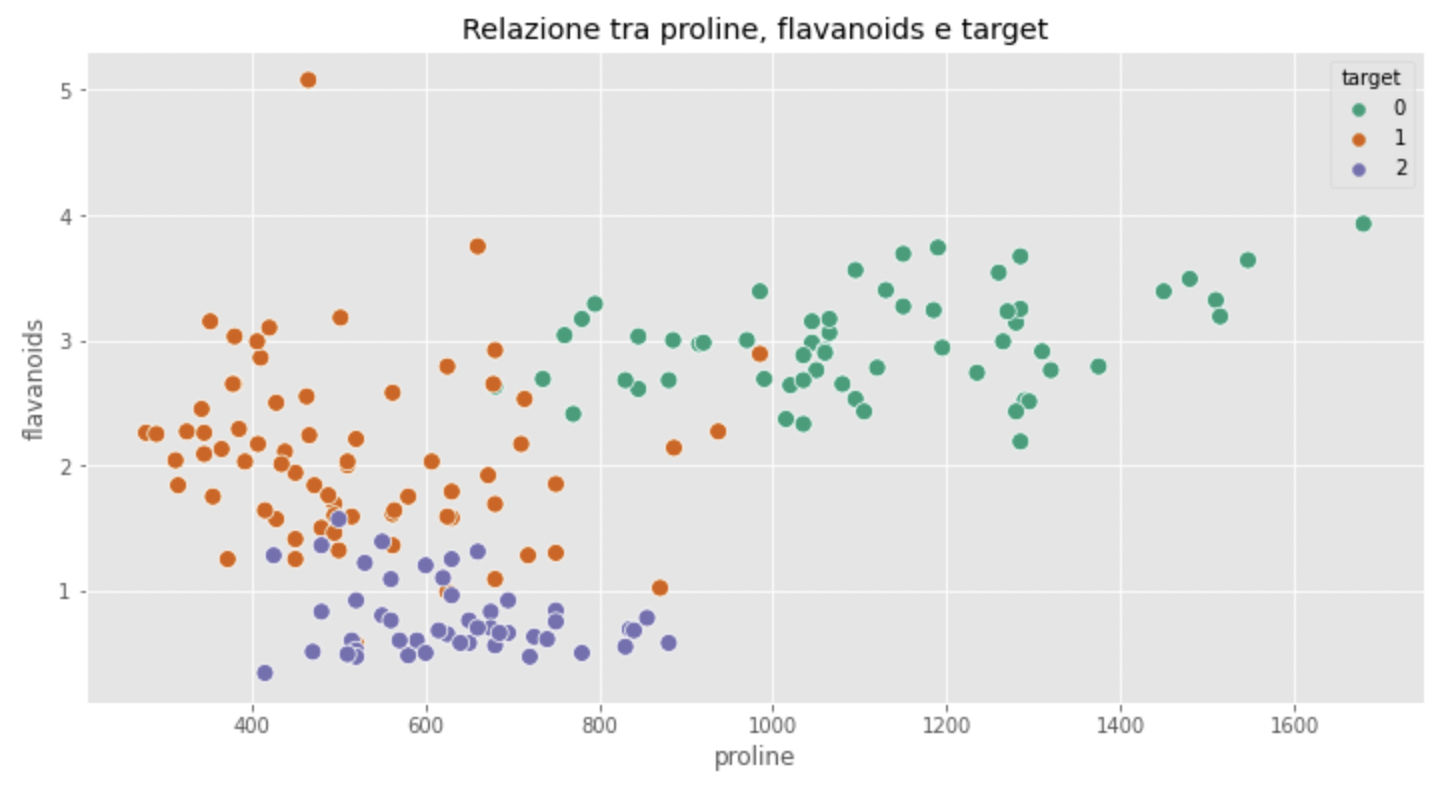
La nostra intuizione ci ha visto bene! I vini di tipo 0 mostrano pattern chiari di flavanoidi e prolina. In particolare, i livelli di prolina sono molto più alti mentre il livello di flavanoidi è stabile intorno al valore di 3.
Vediamo ora come Seaborn possa di nuovo aiutarci ad espandere la nostra esplorazione grazie alla mappa di calore (heatmap). Andremo a creare una matrice di correlazione con Pandas e a isolare le variabili più correlate tra loro
corrmat = df.corr()
hm = sns.heatmap(corrmat,
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 10},
yticklabels=df.columns,
xticklabels=df.columns,
cmap="Spectral_r")
plt.show()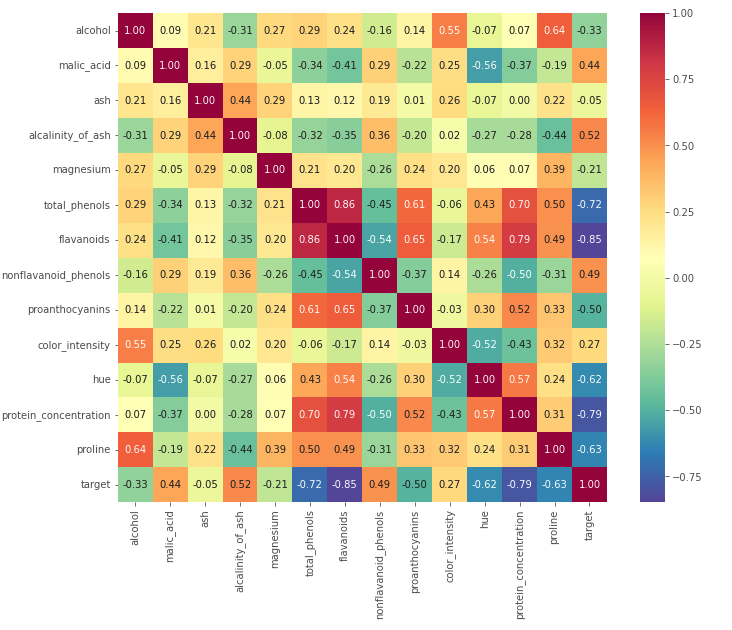
La mappa di calore è utile perché ci permette di cogliere efficientemente quali sono le variabili che sono correlate fortemente tra loro. Notiamo come al diminiure della variabile target (che va interpretato come una tendenza andare allo 0, quindi alla al tipo di vino 0) aumentino i flavanoidi, i fenoli totali, la prolina e le altre proteine. E viceversa.
Vediamo anche le relazioni tra le altre variabili, escludendo il target. Ad esempio c’è una correlazione molto forte tra alcol e prolina. Ad alti livelli di alcol corrispondono alti livelli di prolina.
Tiriamo le somme con la fase di brainstorming.
5. Brainstorming
Abbiamo raccolto molti dati a sostegno dell’ipotesi che il vino di classe 0 abbia una composizione chimica particolare.
Rimane ora isolare quali sono le condizioni che differenziano il tipo 1 dal tipo 2. Lascerò questo esercizio al lettore. A questo punto dell’analisi abbiamo diverse cose che possiamo fare:
- creare un report per gli stakeholder
- fare modeling
- continuare con l’esplorazione per chiarire ulteriormente delle domande di business
L’importanza di porsi le domande giuste
A prescindere dalla strada che prendiamo dopo l’EDA, porsi le domande giuste è quello separa un analista dati bravo da uno mediocre.
Possiamo conoscere lo strumento quanto vogliamo, ma questa abilità è inutile se non siamo in grado di recuperare informazioni dai dati.
Porsi le domande giuste permette all’analista di “essere in sync” con lo stakeholder, oppure di implementare un modello predittivo che funzioni veramente.
Ancora una volta, esorto il lettore interessato ad aprire il suo editor di testo preferito e a popolarlo di domande ogniqualvolta sorga il dubbio su qualcosa. Siate maniacali - se la risposta è nei dati, allora è compito nostro trovarla e comunicarla nel migliore dei modi.
Quale visualizzazione scegliere?
Pur non essendo un articolo incentrato sulla data visualization, l'analisi esplorativa si basa fortemente su questo argomento e abbiamo visto diversi grafici, ognuno efficace a modo suo a comunicare il rispettivo insight.
Se il lettore è interessato volerne sapere di più sull'argomento, consiglio fortemente il libro Storytelling with Data: A Data Visualization Guide for Business Professionals di Cole Nussbaumer Knaflic.
Un libro eccellente, che spiega nel minimo dettaglio ma senza mai stancare perché una visualizzazione è da preferire ad un altra, presentando prove e use case.
Leggi la mia recensione di Storytelling with Data qui 👇
 Andrea D’Agostino
Andrea D’Agostino
Conclusione
Va specificato quanto il processo descritto finora sia di natura iterativa. Infatti, l’analisi esplorativa va avanti finché non abbiamo risposto a tutte le domande di business.
Per me è impossibile mostrare tutte le tecniche possibili di esplorazione del dato - mancano sia le richieste di business che il dataset. Tuttavia posso trasmettere al lettore l’importanza di applicare un template come il seguente per essere efficienti nell’analisi.
Grazie per l’attenzione e a presto.





Commenti dalla community